创建顶点缓冲
原文链接:https://kylemayes.github.io/vulkanalia/vertex/vertex_buffer_creation.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在 Vulkan 中,缓冲是用于存储可被显卡读取的任意数据的内存区域。我们会在本章中用它们来存储顶点数据,但它们也可以用于许多其他目的,这些将在以后的章节中探讨。与我们到目前为止见过的 Vulkan 对象不同,缓冲不会自动为自己分配内存。前面章节中的工作已经表明,Vulkan API 将几乎所有事物置于程序员的控制下,内存管理就是其中之一。
尽管本教程只使用 Vulkan API 管理内存, 但现实世界中的许多 Vulkan 应用程序使用更高级的抽象,例如 Vulkan 内存分配器(VMA)。VMA 是一个库,它封装了 Vulkan API,并使内存管理变得更加简单和容易。
vulkanalia-vmacrate(vulkanalia项目的一部分)提供了 VMA 与vulkanalia的集成。
创建缓冲
首先,我们创建一个名为 create_vertex_buffer 的新函数,并在 App::create 函数中,在 create_command_buffers 之前调用它。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_vertex_buffer(&instance, &device, &mut data)?;
create_command_buffers(&device, &mut data)?;
// ...
}
}
unsafe fn create_vertex_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}创建缓冲需要填充一个 vk::BufferCreateInfo 结构体。
let buffer_info = vk::BufferCreateInfo::builder()
.size((size_of::<Vertex>() * VERTICES.len()) as u64)
// continued...结构体的第一个字段是 size ,它指定缓冲的大小,以字节为单位。使用 size_of 可以很容易地计算出顶点数据的大小。
.usage(vk::BufferUsageFlags::VERTEX_BUFFER)结构体的第二个字段是 usage,它表示缓冲中的数据将用于哪些目的。使用按位或可以指定多个目的。在当前的场景下我们会将缓冲用作顶点缓冲,关于其他类型的用法将在以后的章节中讨论。
.sharing_mode(vk::SharingMode::EXCLUSIVE);和交换链中的图像一样,缓冲也既可以由特定的队列族拥有,或者在多个队列族之间共享。由于缓冲仅将在图形队列中使用,因此我们可以使用独占访问。
.flags(vk::BufferCreateFlags::empty()); // 可选flags 参数用于配置稀疏缓冲内存(sparse buffer memory),现在我们还不用关心这个。你可以省略这个字段,它会被自动设置为默认值(空标志集)。
现在,我们可以使用 create_buffer 创建缓冲。首先在 AppData 中添加一个 vertex_buffer 字段来保存缓冲句柄。
struct AppData {
// ...
vertex_buffer: vk::Buffer,
}接下来在 create_vertex_buffer 中调用 create_buffer:
unsafe fn create_vertex_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let buffer_info = vk::BufferCreateInfo::builder()
.size((size_of::<Vertex>() * VERTICES.len()) as u64)
.usage(vk::BufferUsageFlags::VERTEX_BUFFER)
.sharing_mode(vk::SharingMode::EXCLUSIVE);
data.vertex_buffer = device.create_buffer(&buffer_info, None)?;
Ok(())
}缓冲应该在程序结束之前在渲染指令中保持可用,并且缓冲不依赖于交换链,因此我们将在 App::destroy 方法中清理它:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_buffer(self.data.vertex_buffer, None);
// ...
}内存需求
缓冲已经创建了,但实际上我们还没有为其分配任何内存。为缓冲分配内存的第一步是使用 get_buffer_memory_requirements 函数查询其内存需求。
let requirements = device.get_buffer_memory_requirements(data.vertex_buffer);这个函数返回的 vk::MemoryRequirements 结构体有三个字段:
size– 所需内存大小(以字节为单位),可能与buffer_info.size不同。alignment– 缓冲在内存分配的区域中开始的偏移量(以字节为单位),取决于buffer_info.usage和buffer_info.flags。memory_type_bits– 适用于缓冲的内存类型。
显卡可以分配不同类型的内存,每种类型的内存在允许的操作和性能特性方面各不相同。我们需要将缓冲的需求(vk::MemoryRequirements)和我们应用程序的需求结合起来,找到合适的内存类型。为此,我们创建一个新函数 get_memory_type_index。
unsafe fn get_memory_type_index(
instance: &Instance,
data: &AppData,
properties: vk::MemoryPropertyFlags,
requirements: vk::MemoryRequirements,
) -> Result<u32> {
}首先,我们需要使用 get_physical_device_memory_properties 查询设备上可用的内存类型。
let memory = instance.get_physical_device_memory_properties(data.physical_device);返回的 vk::PhysicalDeviceMemoryProperties 结构体有两个数组 memory_types 和 memory_heaps。内存堆代表不同的内存资源,比如专用的 VRAM 和在 VRAM 耗尽时 RAM 中的交换空间。这些堆中有不同类型的内存。现在我们只关注内存类型,而不关注内存来自哪个堆,但你应该能想到不同的堆会影响性能。
首先,让我们找到一个对缓冲本身合适的内存类型:
(0..memory.memory_type_count)
.find(|i| (requirements.memory_type_bits & (1 << i)) != 0)
.ok_or_else(|| anyhow!("Failed to find suitable memory type."))requirements 参数中的 memory_type_bits 字段将被用于指定适合的内存类型。这意味着我们可以通过简单地迭代并检查相应的位是否设置为 1 来找到适合的内存类型的索引。
然而,内存类型不仅要对顶点缓冲合适,我们还需要能够将顶点数据写入该内存。memory_types 数组由 vk::MemoryType 结构体组成,该结构体指定每种类型内存的堆(heap)和属性(properties)。属性定义了内存的特殊特性,例如能否从 CPU 映射它以便我们从 CPU 写入数据 —— 这个属性通过 vk::MemoryPropertyFlags::HOST_VISIBLE 来指示。我们还需要使用 vk::MemoryPropertyFlags::HOST_COHERENT 属性。我们将在映射内存时看到为什么需要这样做。
现在,修改循环以检查此属性的支持:
(0..memory.memory_type_count)
.find(|i| {
let suitable = (requirements.memory_type_bits & (1 << i)) != 0;
let memory_type = memory.memory_types[*i as usize];
suitable && memory_type.property_flags.contains(properties)
})
.ok_or_else(|| anyhow!("Failed to find suitable memory type."))如果存在适合缓冲的内存类型,并且该内存类型具有我们所需的所有属性,则返回其索引;否则返回错误。
内存分配
现在我们已经有了确定正确内存类型的方法,我们可以填充 vk::MemoryAllocateInfo 结构体来实际分配内存了。
let memory_info = vk::MemoryAllocateInfo::builder()
.allocation_size(requirements.size)
.memory_type_index(get_memory_type_index(
instance,
data,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
requirements,
)?);内存分配就是简单地指定大小和类型,这两者都来自于顶点缓冲的内存需求和所需的属性。在 AppData 中添加一个字段来存储内存句柄:
struct AppData {
// ...
vertex_buffer: vk::Buffer,
vertex_buffer_memory: vk::DeviceMemory,
}调用 allocate_memory 来填充这个新字段:
data.vertex_buffer_memory = device.allocate_memory(&memory_info, None)?;如果内存分配成功,我们就可以使用 bind_buffer_memory 将内存与缓冲关联起来:
device.bind_buffer_memory(data.vertex_buffer, data.vertex_buffer_memory, 0)?;前两个参数不言自明,第三个参数是顶点数据在内存区域内的偏移量。由于此内存专门为顶点缓冲分配,因此偏移量是 0。如果我们要提供非零的偏移量,则这个值必须可被 requirements.alignment 整除。
当然,就像在 C 语言中动态分配的内存一样,内存应该在某个时候被释放。绑定到缓冲对象的内存在缓冲不再被使用时可以被释放,所以让我们在缓冲被销毁后释放它:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_buffer(self.data.vertex_buffer, None);
self.device.free_memory(self.data.vertex_buffer_memory, None);
// ...
}填充顶点缓冲
现在是时候将顶点数据复制到缓冲了,这是使用 map_memory 函数通过将缓冲内存映射到 CPU 可访问的内存中来完成的。
let memory = device.map_memory(
data.vertex_buffer_memory,
0,
buffer_info.size,
vk::MemoryMapFlags::empty(),
)?;该函数允许我们访问由偏移量和大小指定的内存区域。在这里,偏移量和大小分别为 0 和 buffer_info.size。还可以使用特殊值 vk::WHOLE_SIZE 来映射所有内存。最后一个参数可用于指定标志,但当前 API 中还没有任何可用的标志。它必须设置为空标志集。返回的值是映射值的指针。
在继续之前,我们需要一个将顶点列表的内存复制到映射内存中的函数。在程序中添加这个导入:
use std::ptr::copy_nonoverlapping as memcpy;现在我们可以将顶点数据复制到缓冲内存中,然后使用 unmap_memory 取消映射。
memcpy(VERTICES.as_ptr(), memory.cast(), VERTICES.len());
device.unmap_memory(data.vertex_buffer_memory);不幸的是,出于诸如缓存(caching)的原因,驱动程序可能不会立即将数据复制到缓冲内存中。写入缓冲的数据亦可能在映射内存中尚不可见。有两种方法可以解决这个问题:
- 使用主机一致(host coherent)的内存堆,这种堆使用
vk::MemoryPropertyFlags::HOST_COHERENT表示 - 在写入映射内存后调用
flush_mapped_memory_ranges,并在读取映射内存之前调用invalidate_mapped_memory_ranges
我们采用了第一种方法,这样可以确保映射内存始终与分配的内存内容相匹配。相较于冲刷(flush)内存而言,这样做性能稍差,但我们将在下一章看到为什么这没关系。
冲刷内存范围或使用一致性内存堆意味着驱动程序将知道我们对缓冲的写入,但这并不意味着我们写入的数据实际上已经在 GPU 上可见。将数据传输到 GPU 是在后台进行的操作,规范仅保证这个操作在我们下一次调用 queue_submit 时是完成的。
绑定顶点缓冲
现在,仅剩的任务是在渲染操作期间绑定顶点缓冲。我们将扩展 create_command_buffers 函数来完成这个任务。
// ...
device.cmd_bind_vertex_buffers(*command_buffer, 0, &[data.vertex_buffer], &[0]);
device.cmd_draw(*command_buffer, VERTICES.len() as u32, 1, 0, 0);
// ...cmd_bind_vertex_buffers 函数用于将顶点缓冲绑定到绑定点,就像我们在上一章中设置的那样。第二个参数指定我们正在使用的顶点输入绑定的索引。最后两个参数指定要绑定的顶点缓冲和从中开始读取顶点数据的字节偏移量。你还应该更改对 cmd_draw 的调用,将缓冲中的顶点数传递给该函数,代替原先硬编码的数字 3。
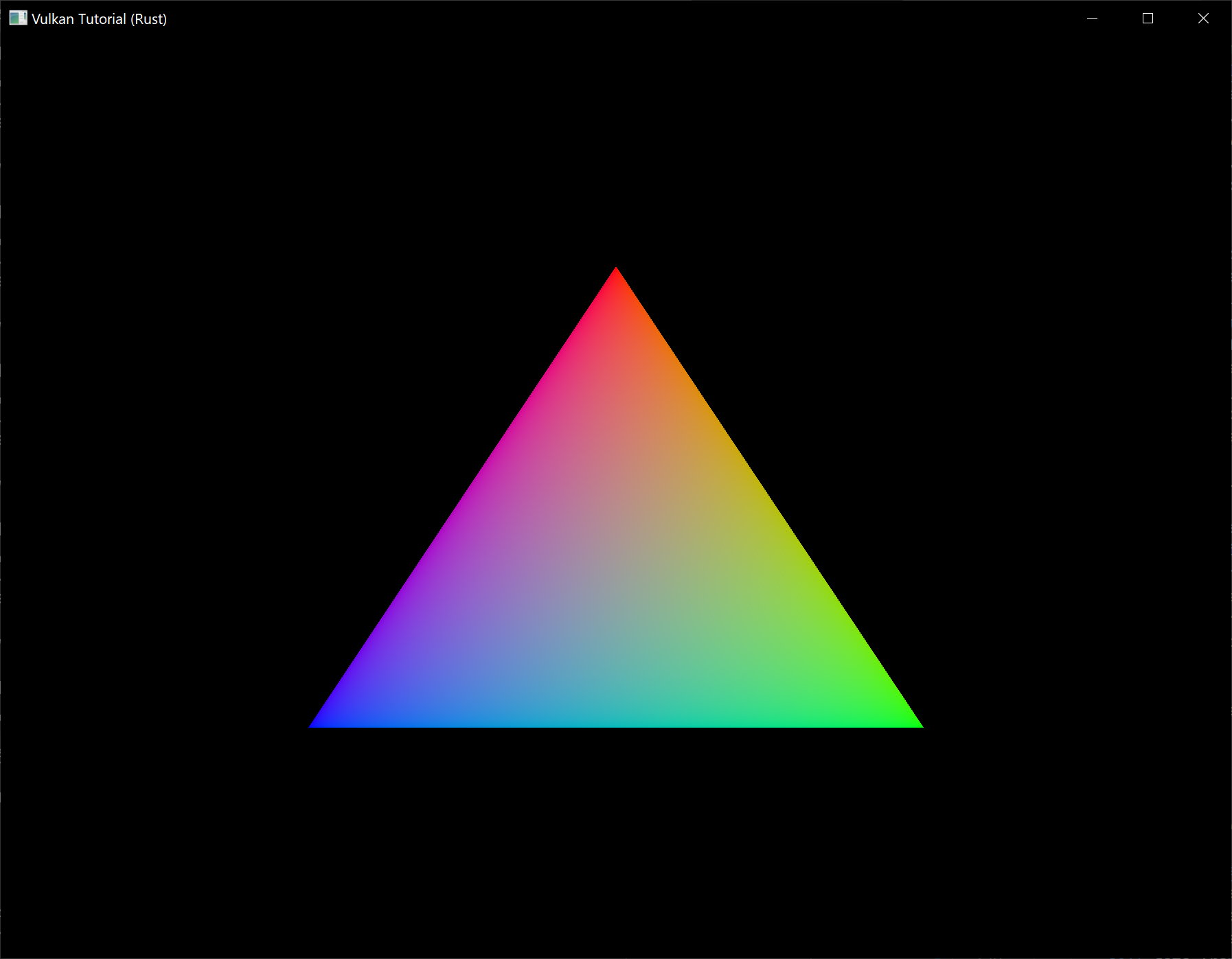
现在运行程序,你应该会再次看到熟悉的三角形:
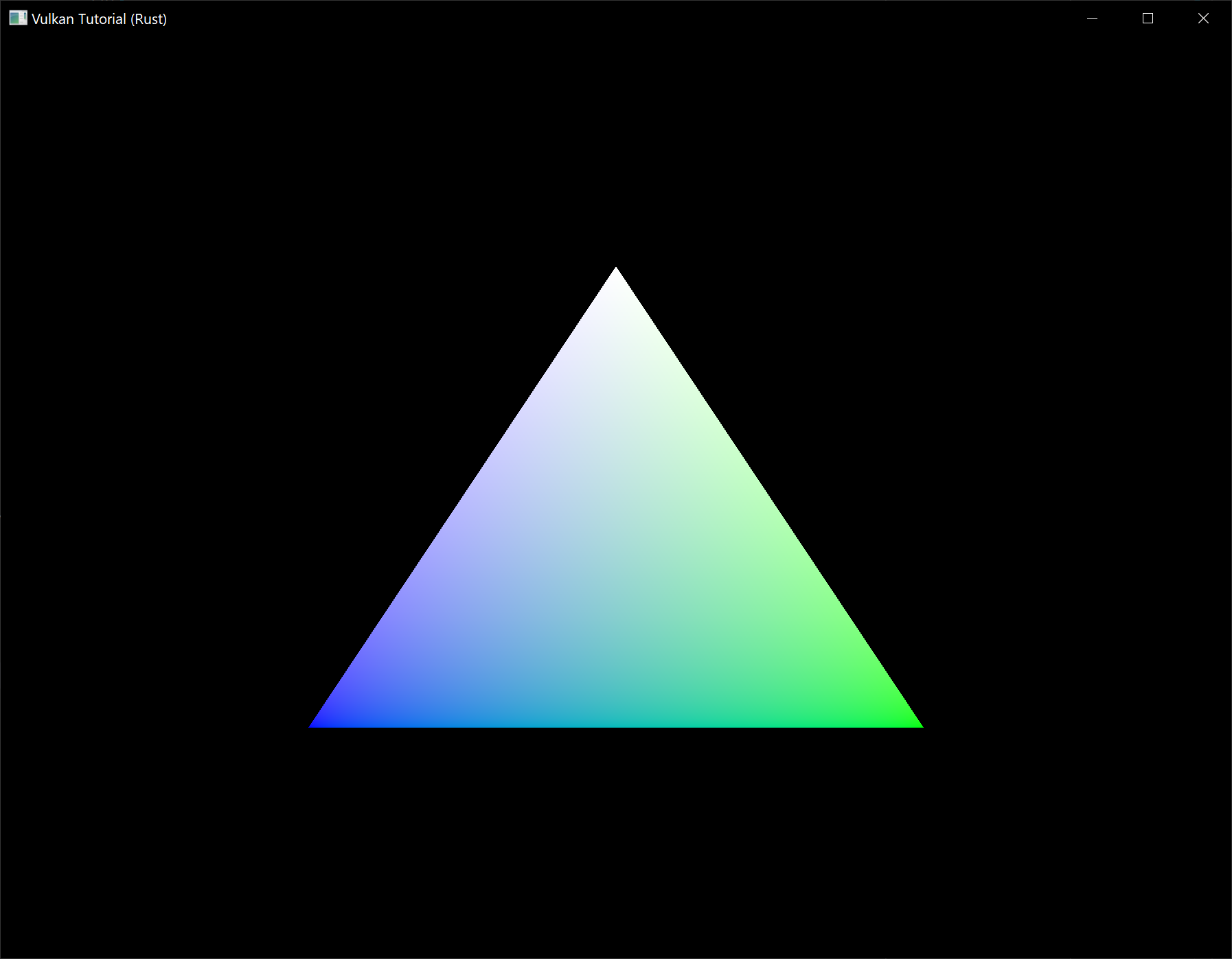
通过修改 VERTICES 列表,将顶点的颜色更改为白色,可以尝试修改三角形的顶点颜色:
static VERTICES: [Vertex; 3] = [
Vertex::new(vec2(0.0, -0.5), vec3(1.0, 1.0, 1.0)),
Vertex::new(vec2(0.5, 0.5), vec3(0.0, 1.0, 0.0)),
Vertex::new(vec2(-0.5, 0.5), vec3(0.0, 0.0, 1.0)),
];再次运行程序,你应该会看到以下效果:
在下一章中,我们将介绍另一种将顶点数据复制到顶点缓冲的方法。这种方法能带来更好的性能,但需要更多的工作。