介绍
原文链接:https://kylemayes.github.io/vulkanalia/introduction.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本教程是用 Rust 对 https://vulkan-tutorial.com 的改写版本,应当归功于原教程的作者 (Alexander Overvoorde) 及其他贡献者们。
同时,本教程也包含由笔者原创的章节(从推送常量章节开始)。这些章节介绍了在几乎所有的 Vulkan 应用中都非常重要的 Vulkan 概念和特性。然而,正如这些章节中所说明的那样,这些特性是实验性的。
关于
本教程会教授一些 Vulkan 图形与计算 API 的基础知识。Vulkan 是一个由 Khronos 组织 (因 OpenGL 而为人所知)提出的新 API,针对现代显卡的特性提供了更好的抽象。新的接口可以让你更好地描述你的应用程序要做什么,从而带来相比于 OpenGL 和 Direct3D 之类的现有的图形 API 更好的性能和更少的意外驱动程序行为。Vulkan 的设计思想与 Direct3D 12 和 Metal 相似,但 Vulkan 在跨平台方面具有优势,可以让你同时开发 Windows,Linux 和 Android 应用程序(并借由 MoltenVK 开发 iOS 与 MacOS 应用程序)。
然而,为了这些增益,你所付出的代价便是你要使用一个更加冗长的 API。从创建帧缓冲(framebuffer)到管理缓冲和纹理图像一类对象的内存,每个和图形 API 相关的细节都需要在你的应用程序中从头开始设置。图形驱动程序会做更少手把手的指导,也就意味着你要在你的应用程序中做更多工作来确保正确的行为。
简而言之,Vulkan 并不是适合所有人使用的 API。它面向的是那些热衷于高性能计算机图形学,并且愿意为其投入精力的程序员们。如果你更感兴趣的是游戏开发而不是计算机图形学,那么你可能还是应该坚持使用 OpenGL 或者 Direct3D,因为它们不会那么快被 Vulkan 取代。另一个选择是使用像 Unreal Engine 这样的引擎,它们可以使用 Vulkan,但会提供给你一个更高层次的 API。
抛开上面的问题,让我们来看看跟着这个教程学习所需的一些东西:
本教程不会要求你有 OpenGL 或者 Direct3D 的知识储备,但要求你必须理解 3D 计算机图形学的基础。例如,教程中不会解释透视投影背后的数学原理。这本在线书籍是一个很好的计算机图形学入门资源。其他一些很好的计算机图形学资源包括:
- Ray tracing in one weekend
- Physically Based Rendering book
- 在真正的开源游戏引擎中使用 Vulkan:Quake 和 DOOM 3
如果你想要 C++ 教程,请查看原教程:
https://vulkan-tutorial.com
本教程使用 vulkanalia crate 来提供 Rust 语言对 Vulkan API 的访问。vulkanalia 提供了对 Vulkan API 的原始绑定,同时也提供了一个轻量级的封装,使得运用这些 API 更简单,也“更 Rust”(下一章里你会看到的)。也就是说,你不必费心考虑你的 Rust 程序如何与 Vulkan API 交互,同时你也能免受 Vulkan API 的危险性和冗长性的影响。
如果你想要一个使用更安全、细致封装的 vulkano crate 的 Rust Vulkan 教程,请查看这个教程:https://github.com/bwasty/vulkan-tutorial-rs。
教程结构
我们首先会速览一下 Vulkan 是如何工作的,以及要把第一个三角形画到屏幕上所需的工作。在你了解这些小的步骤在整个过程中的基本作用之后,它们的目的会更加清晰。接下来,我们会使用 Vulkan SDK 来设置开发环境。
在这之后,我们会实现渲染第一个三角形的 Vulkan 程序所需的所有基本组件。每一章的结构大致如下:
- 引入一个新的概念及其目的
- 使用所有相关的 API 调用,将其集成到你的程序中
- 将其抽象为辅助函数
尽管每一章都是作为前一章的后续章节编写的,但把每一章作为单独的介绍一个特定 Vulkan 特性的文章来阅读也是可以的。也就是说这个网站也可以作为一个 Vulkan 参考。所有 Vulkan 函数和类型都链接到了 Vulkan 规范或者 vulkanalia 的文档,你可以点击链接来了解更多。Vulkan 仍然是一个非常年轻的 API,所以 Vulkan 的规范本身可能有一些缺点。你可以提交反馈到 这个 Khronos 仓库。
如同前面所提到的,Vulkan API 是一个非常冗长的 API,提供了许多参数,能给你对图形硬件最大的控制。这就导致像创建纹理这种基本操作都要经过很多步骤,而且每次都要重复。因此,我们会在整个教程中会创建一系列我们自己的的辅助函数。
每一章也包含了一个链接,指向了该章节完成后的最终代码。如果你对代码的结构有任何疑问,或者你遇到了 bug,想要对比一下,你可以参考这些代码。
本教程旨在成为社区的共同努力。Vulkan 仍然是一个相当新的 API,而最佳实践尚未完全建立。如果你对教程或者网站本身有任何类型的反馈,请随时向 GitHub 存储库 提交问题或拉取请求。
译者注:本译本也有 GitHub 仓库,如果你对中文翻译有任何疑问或者改进建议,欢迎提交 Issue 和 PR :)
在你完成了第一个 Vulkan 三角形的绘制之后,我们会开始扩展程序,添加线性变换、纹理和 3D 模型等功能。
如果你有使用其他图形 API 的经验,你会明白在第一个三角形在屏幕上显示出来之前可能会有很多步骤。在 Vulkan 中也有很多这样的步骤,但是你会发现每个步骤都很容易理解,而且不会感觉哪一步是多余的。一旦你有了这个基础的三角形,绘制拥有贴图的 3D 模型并不需要太多额外的工作,并且在这之后的每一步都会给你带来更多增益。
如果你在阅读本教程时遇到了任何问题,请查阅 FAQ,看看你的问题和解决方案是否已经在里面列出。接下来,你可以在原教程对应章节的评论区里找找,看是否有人遇到了相同的问题(如果不是 Rust 特有的问题)。
概览
原文链接:https://kylemayes.github.io/vulkanalia/overview.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章会以介绍 Vulkan 和它所解决的问题开始。之后,我们会看到绘制第一个三角形所需的所有组件。这会给你一个总体的蓝图,以便你将每个后续章节放在正确的位置。之后我们会讨论 vulkanalia 提供的 Vulkan API。
Vulkan 的起源
和之前的图形 API 一样,Vulkan 也是为跨平台抽象 GPU 而设计的。以往的 API 大都有一个问题,那就是它们都是根据诞生年代的图形硬件特性来设计的,而此时的图形硬件大多都只有一些可配置的功能。程序员必须以标准的格式提供顶点数据,并且在光照和着色选项上受制于 GPU 制造商。
在显卡架构成熟之后,它们开始提供更多的可编程特性。所有这些新功能都必须以某种方式与现有的 API 集成。这就导致这些 API 不能提供理想的抽象,而显卡驱动需要猜测程序员的意图,以将其映射到现代图形架构。这就是为什么有这么多驱动更新来提高游戏性能,而且有时候提升幅度很大。由于这些驱动的复杂性,应用程序开发人员还需要处理制造商之间的不一致性,例如着色器接受的语法。除了这些新功能之外,过去十年还涌入了具有强大图形硬件的移动设备。这些移动 GPU 出于空间和能耗上的考虑采用了与桌面端不同的架构。其中一个例子是 tiled rendering,它可以给程序员提供对此功能的更多控制,从而提高性能。此外受限于诞生的年代,这些 API 对多线程的支持都非常有限,这可能会导致 CPU 成为性能瓶颈。
Vulkan 从头开始、针对现代图形架构而设计,从而解决了上述问题。Vulkan 要求程序员明确地指定他们的意图,从而减少驱动开销,并允许多个线程并行创建和提交指令。Vulkan 使用一种标准的字节码格式和一种编译器来减少着色器编译中的不一致性。最后,它将现代图形卡的通用处理能力纳入到单个 API 中,从而将图形和计算功能统一起来。
画一个三角形需要什么
接下来我们会总览一下在一个良好的 Vulkan 程序中绘制一个三角形所需的所有步骤。这里只是给你一个大的蓝图,以便你将所有的单独组件联系起来,而所有概念都会在后面的章节中详细介绍。
1. 创建实例并选择物理设备
一个 Vulkan 应用首先通过创建一个 VkInstance 来设置 Vulkan API。实例的创建是通过描述你的应用程序和你将要使用的 API 扩展来完成的。创建实例之后,你可以查询支持 Vulkan 的硬件,并选择一个或多个 VkPhysicalDevice 来使用。你可以查询像 VRAM 大小和设备功能这样的属性来选择所需的设备,例如优先使用独立显卡。
2. 逻辑设备和队列族(queue families)
选择正确的硬件设备后,你需要创建一个 VkDevice (逻辑设备),在这里你需要更具体地描述你将要使用的 VkPhysicalDeviceFeatures,例如多视口渲染和 64 位浮点数。你还需要指定你想要使用的队列族。大多数 Vulkan 操作,例如绘制指令和内存操作,都是通过提交到 VkQueue 来异步执行的。队列是从队列族中分配的,每个队列族都支持一组特定的操作。例如,可能会有单独的队列族用于图形、计算和内存传输操作。队列族的可用性也可以用作物理设备选择的区分因素。虽然支持 Vulkan 的设备可能不提供任何图形功能,但是今天所有支持 Vulkan 的显卡通常都支持我们感兴趣的所有队列操作。
3. 创建窗口和交换链(swapchain)
除非你只对离屏渲染有兴趣,否则你需要创建一个窗口来呈现渲染图像。窗口可以使用本地平台 API 创建,也可以使用类似 GLFW、SDL 或 winit crate 的库来创建。在本教程中我们会使用 winit crate,下一章会对其进行详细介绍。
我们还需要两个组件才能完成窗口渲染:一个窗口表面(VkSurfaceKHR)和一个交换链(VkSwapchainKHR),可以注意到这两个组件都有一个 KHR 后缀,这表示它们都是 Vulkan 扩展。Vulkan 本身完全是平台无关的,这就是为什么我们需要使用标准 WSI(Window System Interface,窗口系统接口)扩展与原生的窗口管理器进行交互。表面(Surface)是一个渲染窗口的跨平台抽象,通常它是由原生窗口系统句柄 —— 例如 Windows 上的 HWND —— 作为参数实例化得到的。vulkanalia 包含了可选的 winit 集成,这会帮助我们处理创建窗口和与之关联的表面的过程中那些平台特定的细节。
交换链是一系列的渲染目标。它可以保证我们正在渲染的图像不是当前屏幕上正在显然的图像,从而确保只有完整的图像才会被显示。每次我们想要绘制一帧时,我们都必须要求交换链提供一个图像来进行渲染。当我们完成一帧的绘制后,图像就会被返回到交换链中,以便在某个时刻呈现到屏幕上。渲染目标的数量和呈现图像到屏幕的条件取决于呈现模式(present mode)。常见的呈现模式有双缓冲(垂直同步)和三缓冲。我们将在创建交换链章节讨论这些问题。
有的平台允许你直接渲染到输出,而不通过 VK_KHR_display 和 VK_KHR_display_swapchain 与窗口管理器进行交互。这就允许你创建一个覆盖整个屏幕的表面,你可以用它来实现你自己的窗口管理器。
4. 图像视图(image view)和帧缓冲(framebuffer)
从交换链获取图像后,还不能直接在图像上进行绘制,需要将图像先包装进 VkImageView 和 VkFramebuffer。一个图像视图可以引用图像的一个特定部分,而一个帧缓冲则可以引用用于颜色、深度和模板的图像视图。因为交换链中可能有很多不同的图像,所以我们会预先为每个交换链图像创建一个图像视图和帧缓冲,并在绘制时选择正确的那个。
5. 渲染流程(render passes)
Vulkan 中的渲染流程描述了渲染操作中使用的图像类型、图像的使用方式,以及如何处理它们的内容。在我们最初的三角形渲染程序中,我们会告诉 Vulkan 我们会使用一个图像作为颜色目标,并且我们希望在绘制操作之前将其清除为一个纯色。渲染流程只描述图像的类型,VkFramebuffer 则会将特定的图像绑定到这些槽中。
6. 图形管线(graphics pipeline)
Vulkan 的图形管线通过创建 VkPipeline 对象建立。它描述了显卡的可配置状态 —— 例如视口(viewport)的大小和深度缓冲操作,以及使用 VkShaderModule 的可编程状态。VkShaderModule 对象是从着色器字节码创建的。驱动还需要知道在管线中将使用哪些渲染目标,我们通过引用渲染流程来指定。
Vulkan 与之前的图形 API 最大的不同是几乎所有图形管线的配置都需要提前完成。这也就意味着如果我们想要切换到另一个着色器,或者稍微改变顶点布局,那么整个图形管线都要被重建。也就是说,我们需要为所有不同的组合创建很多 VkPipeline 对象。只有一些基本的配置 —— 例如视口大小和清除颜色 —— 可以被动态地改变。所有的状态都需要被显式地描述,没有默认的颜色混合状态。
这样做的好处类似于预编译相比于即时编译,驱动程序可以获得更大的优化空间,并且运行时的性能更加可预测,因为像切换到另一个图形管线这样的大的状态改变都是显式的。
7. 指令池和指令缓冲
之前提到,Vulkan 的许多操作 —— 例如绘制操作 —— 需要被提交到队列才能执行。这些操作首先要被记录到一个 VkCommandBuffer 中,然后提交给队列。这些指令缓冲由 VkCommandPool 分配,它与特定的队列族相关联。要绘制一个简单的三角形,我们需要记录下列操作到 VkCommandBuffer 中:
- 开始渲染
- 绑定图形管线
- 绘制三个顶点
- 结束渲染
帧缓冲绑定的图像依赖于交换链给我们的图像,我们可以提前为每个图像创建指令缓冲,然后在绘制时直接选择对应的指令缓冲使用。当然,每一帧都重新记录指令缓冲也是可以的,但这样做的效率很低。
8. 主循环
将绘制指令包装进指令缓冲之后,主循环就很直截了当了。我们首先使用 vkAcquireNextImageKHR 从交换链获取一张图像,接着为图像选择正确的指令缓冲,然后用 vkQueueSubmit 执行它。最后,我们使用 vkQueuePresentKHR 将图像返回到交换链,从而使其呈现到屏幕上。
提交给队列的操作会被异步执行。我们需要采取诸如信号量一类的同步措施来确保正确的执行顺序。绘制指令必须在获取图像完成后才能开始执行,否则可能会出现我们渲染到一个仍然在屏幕上显示的图像的情况。vkQueuePresentKHR 调用也需要等到渲染完成后才能执行,我们会使用第二个信号量来实现这一点。
总结
这个快速的介绍应该能让你对绘制第一个三角形所需的工作有一个基本的了解。一个真实的程序包含更多的步骤,例如分配顶点缓冲、创建 uniform 缓冲和上传纹理图像,这些都会在后续章节中介绍,但我们会从简单的开始,因为 Vulkan 本身的学习曲线就已经非常陡峭了。请注意,我们会通过将顶点坐标嵌入到顶点着色器中来作弊,而不使用顶点缓冲。这是因为管理顶点缓冲需要对指令缓冲有一定的了解。
所以简单来说,要绘制第一个三角形,我们需要:
- 创建一个
VkInstance - 选择一个支持的显卡(
VkPhysicalDevice) - 创建用于绘制和呈现的
VkDevice和VkQueue - 创建窗口、窗口表面和交换链
- 将交换链图像包装进
VkImageView - 创建描述渲染目标和用途的渲染流程
- 为渲染流程创建帧缓冲
- 设置图形管线
- 为每个可能的交换链图像分配并记录一个包含绘制指令的指令缓冲
- 通过获取图像、提交正确的绘制指令缓冲,然后将图像返回到交换链来绘制帧
步骤非常多,但其实每一步都非常简单。每一步都会在后续章节中详细介绍。如果你对程序中的某一步感到困惑,可以回来参考一下本章节。
API 概念
Vulkan API 是用 C 语言定义的。Vulkan API 的规范 —— Vulkan API 注册表 —— 是用一个 XML 文件来定义的,它提供了机器可读的 Vulkan API 定义。
Vulkan 头文件 是 Vulkan SDK 的一部分,它们是从 Vulkan API 注册表生成的。下一章里我们将要安装的 Vulkan SDK 包含了这些头文件。然而,我们不会直接或间接地使用这些头文件,因为 vulkanalia 提供的 Rust 接口独立于 Vulkan SDK 提供的 C 接口,这个 Rust 接口也是从 Vulkan API 注册表生成的。
vulkanalia 的基础是 vulkanalia-sys crate,它定义了 Vulkan API 注册表中的原始类型。这些原始类型被 vulkanalia crate 在 vk 模块中重新导出,同时还包含了从 Vulkan API 注册表生成的其他一些项目,作为前面介绍中提到的对 Vulkan API 的轻量级包装。
类型名称
因为 Rust 有对名称空间(namespace)的支持而 C 没有,vulkanalia 的 API 会略去 Vulkan 类型名称中用于名称空间的部分。更具体地说,Vulkan 类型,例如结构体、联合和枚举,没有 Vk 前缀。例如,VkInstanceCreateInfo 结构体在 vulkanalia 中变成了 InstanceCreateInfo 结构体,并且可以在前面提到的 vk 模块中找到。
从现在开始,本教程将使用 vulkanalia 中的 vk:: 模块前缀来引用 vulkanalia 中定义的 Vulkan 类型,以明确该类型表示的是从 Vulkan API 注册表生成的东西。
这些类型名称会被链接到 vulkanalia 文档中对应的类型。Vulkan 类型的 vulkanalia 文档还包含一个指向 Vulkan规范中该类型的链接,可以用来了解该类型的目的和用法。
一些类型名的例子:
vk::Instancevk::InstanceCreateInfovk::InstanceCreateFlags
枚举
vulkanalia 将 Vulkan 枚举实现为结构体,并将枚举变体实现为这些结构体的关联常量。不使用 Rust 枚举是因为在 FFI 调用中使用 Rust 枚举可能导致未定义行为。
因为结构体充当了关联常量的名称空间,我们也就不必像在 C 语言中那样担心不同 Vulkan 枚举(或来自其他库的枚举)名称之间的冲突。所以和类型名称一样,vulkanalia 会略去 Vulkan 枚举名称中用于名称空间的部分。
例如,VK_OBJECT_TYPE_INSTANCE 枚举变体是 VkObjectType 枚举的 INSTANCE 值。在 vulkanalia 中,这个变体变成了 vk::ObjectType::INSTANCE。
掩码(bitmasks)
vulkanalia 将掩码实现为结构体,并将位标志(bitflags)实现为这些结构体的关联常量。这些结构体和关联常量是通过 bitflags crate 提供的 bitflags! 宏来生成的。
和枚举变体一样,位标志名中用于名称空间的部分会被略去。
例如,VK_BUFFER_USAGE_TRANSFER_SRC_BIT 位标志是 VkBufferUsageFlags 掩码的 TRANSFER_SRC 位标志。在 vulkanalia 中,这个位标志变成了 vk::BufferUsageFlags::TRANSFER_SRC。
指令(command,即 Vulkan API 函数)
尽管 Vulkan specification 会将 Vulkan API 中的函数称作指令(command),但 C++ 版本的教程并没有使用这个术语。此外,将这些函数称作“指令”可能会和另一个概念引起混淆。因此本翻译中都不使用这个术语。
诸如 vkCreateInstance 的原始 Vulkan 函数的类型在 vulkanalia 中被定义为带有 PFN_(pointer to function,函数指针)前缀的函数指针类型别名。所以 vkCreateInstance 的 vulkanalia 类型别名是 vk::PFN_vkCreateInstance。
只有这些函数签名还不足以调用 Vulkan 函数,我们必须先加载这些类型所描述的函数。Vulkan 规范针对这个问题有一个详细的描述,但是在这里我会给出一个简化的版本。
第一个要加载的函数是 vkGetInstanceProcAddr,这个函数是以平台特定的方式加载的,但是 vulkanalia 提供了一个可选的 libloading 集成,我们会在本教程中使用它来从 Vulkan 共享库中加载这个函数。vkGetInstanceProcAddr 可以用来加载我们想要调用的其他 Vulkan 函数。
然而,取决于系统上的 Vulkan 实现,可能会有多个版本的 Vulkan 函数可用。例如,如果你的系统上有一个独立的 NVIDIA GPU 和一个集成的 Intel GPU,那么可能会有针对每个设备的专用 Vulkan 函数的不同实现,例如 allocate_memory。在这种情况下,vkGetInstanceProcAddr 会返回一个函数,这个函数会根据使用的设备来分派调用到正确的设备特定函数。
要避免这种分派的运行时开销,可以使用 vkGetDeviceProcAddr 函数来直接加载这些设备特定的 Vulkan 函数。这个函数的加载方式和 vkGetInstanceProcAddr 一样。
我们会在这个教程中用到许多 Vulkan 函数。幸运的是,我们不需要手动加载它们,因为 vulkanalia 已经提供了以下四类结构体,可以用来轻松地加载所有 Vulkan 函数:
vk::StaticCommands– 以平台特定的方式加载的 Vulkan 函数,可以用来加载其他函数(例如vkGetInstanceProcAddr和vkGetDeviceProcAddr)vk::EntryCommands– 使用vkGetInstanceProcAddr和一个空的 Vulkan 实例加载的 Vulkan 函数。这些函数不与特定的 Vulkan 实例绑定,可以用来查询实例支持并创建实例vk::InstanceCommands– 使用vkGetInstanceProcAddr和一个有效的 Vulkan 实例加载的 Vulkan 函数。这些函数与特定的 Vulkan 实例绑定,可以用来查询设备支持并创建设备vk::DeviceCommands– 使用vkGetDeviceProcAddr和一个有效的 Vulkan 设备加载的 Vulkan 函数。这些函数与特定的 Vulkan 设备绑定,并且提供了你期望中图形 API 提供的大多数功能
这些结构体能让你简单地在 Rust 中加载和调用原始 Vulkan 函数,不过 vulkanalia 提供了对原始函数的包装,这使得在 Rust 中使用它们更加容易,并且不易出错。
函数封装(command wrapper)
一个典型的 Vulkan 函数的签名在 C 中看起来就像这样:
VkResult vkEnumerateInstanceExtensionProperties(
const char* pLayerName,
uint32_t* pPropertyCount,
VkExtensionProperties* pProperties
);
熟悉 Vulkan API 的人可以从这个签名中快速看出这个函数的用法,尽管它没有包含一些关键信息。
而对于那些刚接触 Vulkan API 的人来说,查看此函数的文档可能会更有启发性。文档中对此函数行为的描述表明,使用此函数列出 Vulkan 实例可用的扩展(extension)需要多个步骤:
- 调用函数以获取扩展的数量
- 分配一个可以容纳输出的缓冲
- 再次调用函数,获取扩展并填充缓冲
所以在 C++ 中,这些步骤可能看起来像这样(简单起见,这里忽略了函数的结果):
// 1.
uint32_t pPropertyCount;
vkEnumerateInstanceExtensionProperties(NULL, &pPropertyCount, NULL);
// 2.
std::vector<VkExtensionProperties> pProperties{pPropertyCount};
// 3.
vkEnumerateInstanceExtensionProperties(NULL, &pPropertyCount, pProperties.data());
而 vkEnumerateInstanceExtensionProperties 的封装的 Rust 签名如下:
unsafe fn enumerate_instance_extension_properties(
&self,
layer_name: Option<&[u8]>,
) -> VkResult<Vec<ExtensionProperties>>;这个函数封装使得从 Rust 使用 vkEnumerateInstanceExtensionProperties 更加容易、更少出错,并且更符合习惯用法:
layer_name参数的可选性被编码在函数签名中。这个参数是可选的,这一点在 C 函数签名中没有体现,需要查阅 Vulkan 规范才能得到这个信息- 函数的可失败性通过返回一个
Result(VkResult<T>是Result<T, vk::ErrorCode>的类型别名)体现。这使得我们可以利用 Rust 强大的错误处理能力,并且在我们忘记检查可失败函数的结果时,编译器会发出警告 - 函数封装在内部处理了上面描述的三个步骤,并返回一个包含扩展属性的
Vec
注意,函数封装仍然是 unsafe 的,因为虽然 vulkanalia 可以消除某些类型的错误(例如给此函数传递一个空的层名称),但还是有很多可能会出错的事情,导致诸如段错误之类“有趣”的事情发生。你可以随时检查 Vulkan 文档中函数的 Valid Usage 部分以了解如何正确地调用函数。
你可能注意到了上面函数封装中的 &self 参数。这些函数封装是在 trait 中定义的,而 vulkanalia 暴露的类型实现了这些 trait。这些 trait 可以分为两类:版本 trait(version traits)和扩展 trait(extension traits)。版本 trait 为 Vulkan 的标准部分中的函数提供函数封装,而扩展 trait 为 Vulkan 扩展中的函数提供函数封装。
例如,enumerate_instance_extension_properties 是一个非扩展 Vulkan 函数,是 Vulkan 1.0 的一部分,不依赖于 Vulkan 实例或设备,所以它被放在 vk::EntryV1_0 trait 中。而 cmd_draw_indirect_count 函数是在 Vulkan 1.2 中添加的,并且依赖于 Vulkan 设备,所以它被放在 vk::DeviceV1_2 trait 中。
而 vk::KhrSurfaceExtension 是一个扩展 trait,我们将在后面的章节中使用它来调用 destroy_surface_khr 这样的 Vulkan 函数,这些函数是在 VK_KHR_surface 扩展中定义的。
这些版本和扩展 trait 是为包含加载的函数和所需的 Vulkan 实例或设备(如果有的话)的类型定义的。这些类型是精心手工制作的,而不是 vulkanalia 的 vk 模块中自动生成的 Vulkan 绑定的一部分。它们是 Entry、Instance 和 Device 结构体,将在后面的章节中使用。
从现在开始,本教程将继续像本章节一样直接按名称引用这些函数封装(例如 create_instance)。你可以访问 vulkanalia 文档来获取函数封装的更多信息,例如函数封装是在哪个 trait 中定义的。
生成器(Builders)
Vulkan API 通常使用结构体作为 Vulkan 函数的参数。这些作为函数的参数使用的 Vulkan 结构体有一个字段,用于指示结构体的类型。在 C API 中,这个字段(sType)需要被显式地设置。例如,这里我们正在填充 VkInstanceCreateInfo 的一个实例,然后在 C++ 中使用它来调用 vkCreateInstance:
std::vector<const char*> extensions{/* 3 extension names */};
VkInstanceCreateInfo info;
info.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
info.enabledExtensionCount = static_cast<uint32_t>(extensions.size());
info.ppEnabledExtensionNames = extensions.data();
VkInstance instance;
vkCreateInstance(&info, NULL, &instance);
当使用 vulkanalia 时,你仍然可以用这种方式填充参数结构体,但是 vulkanalia 提供了生成器(builder),简化了这些参数结构体的构造。在 vulkanalia 中,vk::InstanceCreateInfo 对应的生成器是 vk::InstanceCreateInfoBuilder。使用这个生成器,上面的代码就可以写成:
let extensions = &[/* 3 extension names */];
let info = vk::InstanceCreateInfo::builder()
.enabled_extension_names(extensions)
.build();
let instance = entry.create_instance(&info, None).unwrap();注意以下差异:
- 无需为
s_type字段提供值。这是因为生成器会自动为这个字段提供正确的值(vk::StructureType::INSTANCE_CREATE_INFO) - 无需为
enabled_extension_count字段提供值。这是因为生成器的enabled_extension_names方法会自动使用提供的切片的长度设置这个字段
然而,上面的 Rust 代码有一定程度的危险。生成器有生存期(lifetime),这要求生成器中存储的引用至少要与生成器本身活得一样久。也就是说,在上面的例子中,Rust 编译器会确保传递给 enabled_extension_names 方法的切片至少活得与生成器一样长。然而,一旦我们调用 .build() 来获取底层的 vk::InstanceCreateInfo 结构体,生成器的生存期就会被丢弃。这意味着 Rust 编译器不再能防止我们 搬起石头砸自己的脚,例如解引用一个已经不存在的切片的指针。
下面的代码会崩溃(但愿如此),因为传递给 enabled_extension_names 的临时 Vec 在我们使用 vk::InstanceCreateInfo 结构体调用 create_instance 时已经被销毁了:
let info = vk::InstanceCreateInfo::builder()
.enabled_extension_names(&vec![/* 3 extension names */])
.build();
let instance = entry.create_instance(&info, None).unwrap();幸运的是,vulkanalia 为此提供了解决方案 —— 不调用 build(),而是直接将生成器传递给函数封装!在任何接受 Vulkan 结构体的地方,你都可以直接提供与 Vulkan 结构体对应的生成器。如果从上面的代码中删除 build() 调用,Rust 编译器就能够利用生成器上的生存期来拒绝这个坏代码,并告诉你 error[E0716]: temporary value dropped while borrowed。
prelude 模块
vulkanalia 提供了prelude 模块,用于暴露使用 crate 所需的基本类型。每个 Vulkan 版本都有一个 prelude 模块,每个模块都会暴露相关的函数 trait,以及其他经常用到的类型:
// Vulkan 1.0
use vulkanalia::prelude::v1_0::*;
// Vulkan 1.1
use vulkanalia::prelude::v1_1::*;
// Vulkan 1.2
use vulkanalia::prelude::v1_2::*;校验层(Validation layers)
如前文所述,Vulkan 是为高性能和低驱动程序开销而设计的。因此,默认情况下 Vulkan 只包含非常有限的错误检查和调试功能。如果你做错了什么,驱动程序通常会崩溃而不是返回错误代码,或者比这更糟 —— 程序会在你的显卡上运行,但在其他显卡上完全失效。
你可以通过校验层来在 Vulkan 中启用很多检查。校验层是可以插入到 API 和图形驱动程序之间的代码片段,用于对函数参数进行额外的检查,并且跟踪内存管理问题。你可以在开发时启用它们,然后在发布应用程序时将其完全禁用,从而实现零开销。任何人都可以编写自己的校验层,但是 LunarG 的 Vulkan SDK 提供了一套标准的校验层,我们将在本教程中使用它们。你还需要注册一个回调函数来接收校验层的调试消息。
因为 Vulkan 对每个操作都非常明确,校验层也非常广泛,所以实际上相比于 OpenGL 和 Direct3D,你更容易找出为什么你的画面是全黑的!
开发环境
原文链接:https://kylemayes.github.io/vulkanalia/development_environment.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
在这个章节中,我们将会安装 Vulkan SDK 并搭建开发 Vulkan 应用所需的环境。此教程假设你已经有一个搭建好的 Rust(1.70+)开发环境。
Cargo 项目
首先,我们创建一个 Cargo 项目:
cargo new vulkan-tutorial
在执行这个命令后,你会看到一个叫做 vulkan-tutorial 的文件夹,里面有一个简单的生成 Rust 可执行文件的 Cargo 项目。
打开这个文件夹里的 Cargo.toml 文件,并且将下列依赖加入其中的 [dependencies] 部分:
anyhow = "1"
log = "0.4"
cgmath = "0.18"
nalgebra-glm = "0.18"
png = "0.17"
pretty_env_logger = "0.5"
thiserror = "1"
tobj = { version = "3", features = ["log"] }
vulkanalia = { version = "=0.25.0", features = ["libloading", "provisional", "window"] }
winit = "0.29"
anyhow– 用于简单的错误处理log– 日志库cgmath– 一个 Rust 语言的 GLM(graphics math library,图形数学库)替代png– 用于将 PNG 图片文件加载到纹理pretty_env_logger– 用于打印日志到控制台thiserror– 用于在自定义错误类型时减少样板代码tobj– 用于加载 Wavefront .obj 格式 的 3D 模型vulkanalia– 用于调用 Vulkan APIwinit– 用于创建将进行渲染的窗口
Vulkan SDK
在开发 Vulkan 应用时需要用到的最关键的组件就是 Vulkan SDK。它包含了头文件、标准校验层、调试工具,以及一个 Vulkan 函数加载器。加载器将会在运行时从驱动中寻找 Vulkan 函数,如果你熟悉 OpenGL 的话,它的功能与 GLEW 类似。
Windows
SDK 能在 LunarG 网站下载。创建账户不是必须的,但它会给你阅读一些额外文档的权限,这些文档或许对你有用。

继续完成安装,并且注意 SDK 的安装路径。我们需要做的第一件事就是验证你的显卡与驱动支持 Vulkan。进入 SDK 的安装路径,打开 Bin 文件夹并且运行 vkcube.exe 示例应用。你应该会看到这个画面:
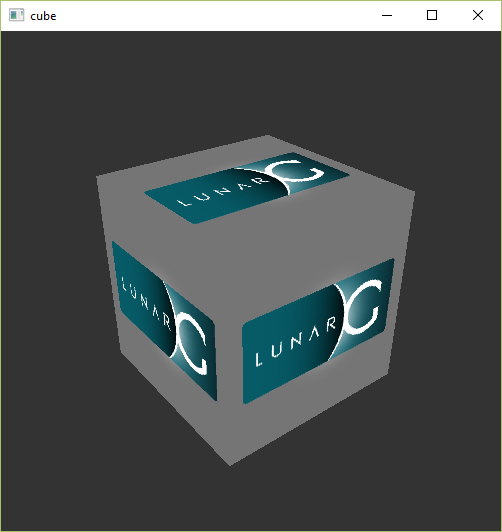
如果你收到了一条错误信息,那你需要确保你的显卡驱动是最新的,包含 Vulkan 运行时,并且你的显卡支持 Vulkan。主流品牌的驱动下载链接详见介绍章节。
这个文件夹里有另外两个对开发很有用的程序。glslangValidator.exe 和 glslc.exe 将会把人类可阅读的 GLSL (OpenGL Shading Language,OpenGL 着色器语言)代码编译为字节码。我们将会在着色器模块章节深入讨论这部分内容。Bin 文件夹也包含了 Vulkan 加载器与校验层的二进制文件;Lib 文件夹则包含了库。
你可以自由地探索其它文件,但本教程并不会用到它们。
Linux
以下操作说明面向 Ubuntu 用户,非 Ubuntu 用户也可以将 apt 命令换成合适的你使用的包管理器的命令。
在 Linux 上开发 Vulkan 应用时需要用到的最关键的组件是 Vulkan 加载器,校验层,以及一些用来测试你的机器是否支持 Vulkan 的命令行实用工具:
sudo apt install vulkan-tools– 命令行实用工具,最关键的两个是vulkaninfo和vkcube。运行这两个命令来测试你的机器是否支持 Vulkan。sudo apt install libvulkan-dev– 安装 Vulkan 加载器。加载器将会在运行时从驱动中寻找这些函数,如果你熟悉 OpenGL 的话,它的功能与 GLEW 类似。sudo apt install vulkan-validationlayers-dev– 安装标准校验层。这在调试 Vulkan 应用程序时非常关键,我们会在之后的章节中讨论这部分内容。
如果你安装成功了,你在 Vulkan 部分没有别的需要做的了。记得运行 vkcube 并确保你可以在一个窗口中看见这个画面:

如果你收到了一条错误信息,那你需要确保你的显卡驱动是最新的,包含 Vulkan 运行时,并且你的显卡支持 Vulkan。主流品牌的驱动下载链接详见介绍章节。
MacOS
SDK 可在 LunarG 网站 下载。创建账户不是必须的,但它会给你阅读一些或许对你有用的额外文档的权限。
MacOS 版本的 SDK 在内部使用了 MoltenVK。Vulkan 在 MacOS 上没有原生支持,所以 MoltenVK 会作为中间层把 Vulkan API 的调用翻译至苹果的 Metal 图形框架。这样你就可以享受到苹果的 Metal 框架在调试与性能上的优点。
下载完成之后,将其解压到你自己选择的文件夹。在解压后的文件夹内,你可以在 Applications 文件夹中找到一些使用 SDK 运行的示例应用的可执行文件。运行 vkcube 示例应用,你会看到这个画面:
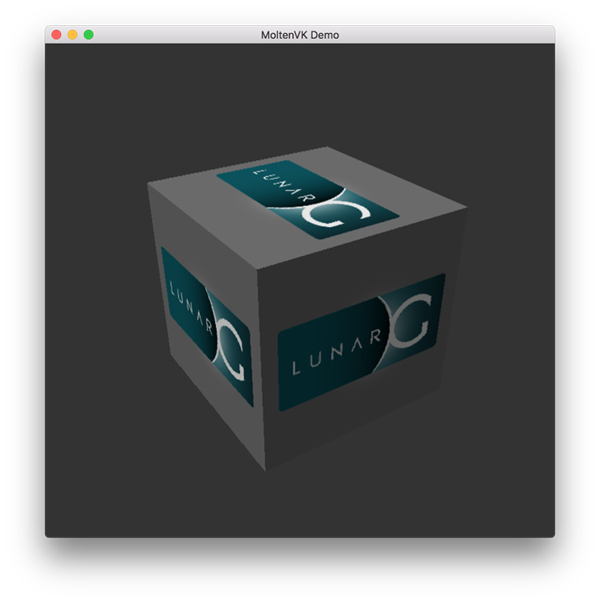
环境配置
当在 Vulkan SDK 目录以外的地方运行 Vulkan 应用程序时,你可能会需要运行由 Vulkan SDK 提供的 setup-env.sh 脚本,以避免找不到 Vulkan 库(例如 libvulkan.dylib)导致的问题。如果你把 Vulkan SDK 安装到了默认位置,脚本应该可以在如下目录中找到:~/VulkanSDK/1.3.280.1/setup-env.sh(用你实际安装的版本号替换 1.3.280.1 以匹配你的 Vulkan 安装)。
你也可以把这个脚本添加到你 Shell 的启动脚本中,这样它就能自动运行了。例如你可以在 ~/.zshrc 文件中添加这样一行:
source ~/VulkanSDK/1.3.280.1/setup-env.sh
FAQ
原文链接:https://kylemayes.github.io/vulkanalia/faq.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本页面列举了在开发 Vulkan 应用时可能遇到的常见问题及其解决方案。
-
(MacOS) 我安装了 Vulkan SDK,但我运行 Vulkan 应用程序的时候遇到了找不到
libvulkan.dylib的错误 —— 参见MacOS Vulkan SDK 安装说明中的环境配置章节。 -
我在核心校验层中遇到了访问冲突(access violation)错误 – 确保未运行 MSI Afterburner / RivaTuner Statistics Server,因为它们和 Vulkan 之间存在一些兼容性问题。
-
我看不到任何来自校验层的消息/校验层不可用 – 首先确保校验层有机会打印错误信息,请在程序退出后保持终端窗口打开。在 Visual Studio 中,你可以通过使用 Ctrl-F5 而不是 F5 来运行程序;在 Linux 中,你可以从终端窗口执行程序。如果仍然没有消息,并且你确信校验层已启用,那么你应该按照此页面上的“Verify the Installation”说明来确保 Vulkan SDK 已正确安装。同时确保你的 SDK 版本至少为 1.1.106.0,以支持
VK_LAYER_KHRONOS_validation校验层。 -
vkCreateSwapchainKHR在SteamOverlayVulkanLayer64.dll中引发错误 – 这似乎是测试版 Steam 客户端中的一个兼容性问题。以下有几个也许可行的解决方法:- 退出 Steam 测试计划
- 将环境变量
DISABLE_VK_LAYER_VALVE_steam_overlay_1设置为1。 - 删除注册表中
HKEY_LOCAL_MACHINE\SOFTWARE\Khronos\Vulkan\ImplicitLayers下的 Steam overlay Vulkan layer 项目。
示例:
基础代码
原文链接:https://kylemayes.github.io/vulkanalia/setup/base_code.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在开发环境一章中,我们创建了一个 Cargo 项目添加了必要的依赖项目。在本章中,我们会用下面的代码替换 src/main.rs 中的内容:
#![allow( dead_code, unused_variables, clippy::too_many_arguments, clippy::unnecessary_wraps )] use anyhow::Result; use winit::dpi::LogicalSize; use winit::event::{Event, WindowEvent}; use winit::event_loop::, EventLoop; use winit::window::{Window, WindowBuilder}; fn main() -> Result<()> { pretty_env_logger::init(); // 创建窗口 let event_loop = EventLoop::new()?; let window = WindowBuilder::new() .with_title("Vulkan Tutorial (Rust)") .with_inner_size(LogicalSize::new(1024, 768)) .build(&event_loop)?; // 初始化应用程序 let mut app = unsafe { App::create(&window)? }; let mut app = unsafe { App::create(&window)? }; event_loop.run(move |event, elwt| { match event { // Request a redraw when all events were processed. Event::AboutToWait => window.request_redraw(), Event::WindowEvent { event, .. } => match event { // Render a frame if our Vulkan app is not being destroyed. WindowEvent::RedrawRequested if !elwt.exiting() => unsafe { app.render(&window) }.unwrap(), // Destroy our Vulkan app. WindowEvent::CloseRequested => { elwt.exit(); unsafe { app.destroy(); } } _ => {} } _ => {} } })?; Ok(()) } /// 我们的 Vulkan 应用程序 #[derive(Clone, Debug)] struct App {} impl App { /// 创建 Vulkan App unsafe fn create(window: &Window) -> Result<Self> { Ok(Self {}) } /// 渲染帧 unsafe fn render(&mut self, window: &Window) -> Result<()> { Ok(()) } /// 销毁 Vulkan App unsafe fn destroy(&mut self) {} } /// 我们的 Vulkan 应用程序所使用的 Vulkan 句柄和相关属性 #[derive(Clone, Debug, Default)] struct AppData {}
首先我们导入 anyhow::Result,这样我们就可以为程序中所有可失败的函数使用 anyhow 提供的 Result 类型。接下来我们导入所有 winit 类型,这些类型将被用于创建窗口并且启动窗口的事件循环。
接着是我们的 main 函数(它返回一个 anyhow::Result)。这个函数首先初始化 pretty_env_logger,它将会把日志打印到控制台(稍后会展示)。
接着,我们创建一个事件循环(event loop),并用 winit 和 LogicalSize 来创建一个窗口作为渲染的目标。LogicalSize 会根据你的显示器的 DPI 来缩放窗口。如果你想了解更多关于 UI 缩放的内容,可以阅读 winit 文档。
接着,我们创建一个我们的 Vulkan 应用(App)的实例,并进入渲染循环。这个循环会持续将我们的场景渲染到窗口,直到你请求关闭窗口 —— 此时应用程序会被销毁并且程序会退出。destroying 标志是必要的,因为在应用程序被销毁时,我们不希望继续渲染场景,否则程序很可能会在尝试访问已被销毁的 Vulkan 资源时崩溃。
最后是 App 和 AppData,App 会被用来实现 Vulkan 程序所需的设置、渲染和析构逻辑。在接下来的章节中,我们都会围绕这个 Vulkan 程序工作。我们会创建非常多的 Vulkan 资源,AppData 会被用作容纳这些资源的容器,这样我们就可以轻松地将这些资源传递给函数。
这样做非常方便,因为我们接下来的很多章节都是加入一个接受 &mut AppData 的函数,创建并初始化 Vulkan 资源。这些函数会在 App::create 构造器中被调用来初始化我们的 Vulkan 应用。并且,在程序结束前,这些 Vulkan 资源会被 App::destory 方法销毁。
一个关于安全性的注解
所有的 Vulkan 函数,无论是原始函数还是它们的封装,在 vulkanalia 中都是被标记为 unsafe 的。这是因为许多 Vulkan 函数对如何调用它们作了限制,而 Rust 无法确保这些限制(除非引入一个更高阶的接口来隐藏 Vulkan API,例如 vulkano)。
本教程通过把所有调用 Vulkan 函数的函数和方法标记为 unsafe 来解决这一问题。这可以最大程度上减少语法噪音,但一个真实的程序中你可能希望自己封装一个安全的接口,并自行确保调用 Vulkan 函数时的正确性。
资源管理
正如在 C 中使用 malloc 分配的每一块内存都需要对应一个 free 调用一样,对于我们创建的每一个 Vulkan 对象,我们都要在不再需要它时显式地将其销毁。在 Rust 中,使用资源分配即初始化(Resource Acuisition Is Initialization, RAII)配合像 Rc 和 Arc 这样的智能指针来自动管理资源是可行的。然而,https://vulkan-tutorial.com 的作者选择在教程中显式地创建和销毁 Vulkan 对象,并且我也打算采用同样的方式。毕竟,Vulkan 的特点就是每一个操作都要显式地进行以避免错误,所以显式地管理对象的生命周期也是很好的学习 API 工作方式的途径。
在完成本教程之后,你就可以编写 Rust 结构体来包装 Vulkan 对象,并在其 Drop 实现中释放 Vulkan 对象,从而实现自动资源管理。对于大规模的 Vulkan 程序而言,RAII 是推荐的模式,但是为了学习,了解背后发生了什么也是很有好处的。
Vulkan 对象要么是由 create_xxx 之类的函数直接创建出来的,要么是通过另一个对象和 allocate_xxx 之类的函数分配出来的。在确保一个对象不会再使用之后,你需要用对应的 destroy_xxx 或者 free_xxx 来销毁它。这些函数的参数通常因对象的类型不同而有所不同,但是它们都有一个共同的参数:allocator。这是一个可选参数,允许你指定一个自定义内存分配器的回调函数。在本教程中我们会忽略这个参数,总是传递 None。
Vulkan 实例
原文链接:https://kylemayes.github.io/vulkanalia/setup/instance.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
你首先要做的事情就是通过创建一个实例来初始化 Vulkan 库。实例是你的应用程序和 Vulkan 库之间的连接,创建它涉及到向驱动程序指定一些关于你的应用程序的细节。首先,添加下面的导入:
use anyhow::{anyhow, Result};
use log::*;
use vulkanalia::loader::{LibloadingLoader, LIBRARY};
use vulkanalia::window as vk_window;
use vulkanalia::prelude::v1_0::*;这里我们引入 anyhow! 宏,这个宏可以让我们轻松地构造 anyhow 错误的实例。然后,我们引入 log::*,这样我们就可以使用 log crate 中的日志宏。接下来,我们引入 LibloadingLoader,它是 vulkanalia 提供的 libloading 集成,我们会用它来从 Vulkan 共享库中加载最初的 Vulkan 函数。你操作系统上的 Vulkan 共享库(例如 Windows 上的 vulkan-1.dll)将会被导入为 LIBRARY。
接着我们将 vulkanalia 对窗口的集成导入为 vk_window,我们将在本章中使用它来枚举渲染到窗口所需的全局 Vulkan 扩展。在将来的章节中,我们还将使用 vk_window 来将 Vulkan 实例与 winit 窗口链接起来。
最后我们从 vulkanalia 引入 Vulkan 1.0 的 prelude 模块,它将为本章和将来的章节提供我们需要的所有其他 Vulkan 相关的导入。
要创建一个实例,我们就要用我们的应用程序的一些信息来填充一个 vk::ApplicationInfo 结构体。技术上来说,这些数据是可选的,但它们可以给驱动程序提供一些有用的信息,以便优化我们的特定应用程序(例如我们的应用程序使用了某个众所周知的图形引擎,这个引擎具有某些特定的行为)。我们将在函数 create_instance 中创建 vk::ApplicationInfo 结构体,create_instance 函数接受我们的窗口和一个 Vulkan 入口点(entry point,我们将在后面创建)并返回一个 Vulkan 实例:
unsafe fn create_instance(window: &Window, entry: &Entry) -> Result<Instance> {
let application_info = vk::ApplicationInfo::builder()
.application_name(b"Vulkan Tutorial\0")
.application_version(vk::make_version(1, 0, 0))
.engine_name(b"No Engine\0")
.engine_version(vk::make_version(1, 0, 0))
.api_version(vk::make_version(1, 0, 0));
}在 Vulkan 中,许多信息都是通过结构体而非函数参数传递的,所以我们再需要填充一个结构体,来提供创建一个实例所需的信息。下一个结构体不是可选的,它会告诉 Vulkan 驱动程序我们想要使用哪些全局扩展和校验层。这里的“全局”意味着这些扩展和校验层适用于整个程序,而不是特定的设备。“全局”和“设备”的概念将在接下来的几章中逐渐变得清晰。首先我们需要使用 vulkanalia 的窗口集成 vk_window 来枚举所需的全局扩展,并将它们转换为以空字符结尾的 C 字符串(null-terminated C strings,*const c_char):
let extensions = vk_window::get_required_instance_extensions(window)
.iter()
.map(|e| e.as_ptr())
.collect::<Vec<_>>();在有了所需的全局扩展列表之后,我们就可以使用传入此函数的 Vulkan 入口点来创建 Vulkan 实例并将其返回了:
let info = vk::InstanceCreateInfo::builder()
.application_info(&application_info)
.enabled_extension_names(&extensions);
Ok(entry.create_instance(&info, None)?)如你所见,Vulkan 中的对象创建函数参数的一般模式是:
- 包含创建信息的结构体的引用
- 可选的自定义分配器回调的引用,本教程中始终为
None
现在我们有了一个可以通过入口点创建 Vulkan 实例的函数,接下来我们需要创建一个 Vulkan 入口点。这个入口点将加载用于查询实例支持和创建实例的 Vulkan 函数。但在此之前,先向我们的 App 结构体添加一些字段来存储我们将要创建的 Vulkan 入口点和实例:
struct App {
entry: Entry,
instance: Instance,
}接着,像这样更新 App::create 方法,以填充 App 中的这些字段:
unsafe fn create(window: &Window) -> Result<Self> {
let loader = LibloadingLoader::new(LIBRARY)?;
let entry = Entry::new(loader).map_err(|b| anyhow!("{}", b))?;
let instance = create_instance(window, &entry)?;
Ok(Self { entry, instance })
}这里我们首先创建了一个 Vulkan 函数加载器,用来从 Vulkan 共享库中加载最初的 Vulkan 函数,接着我们使用这个函数加载器创建 Vulkan 入口点,这个入口点将会加载我们需要的所有 Vulkan 函数。最后,我们用 Vulkan 入口点调用 create_instance 函数来创建 Vulkan 实例。
清理工作
只有当程序将要退出时,Instance 实例才应该被销毁。可以在 App::destroy 方法中使用 destroy_instance 销毁实例:
unsafe fn destroy(&mut self) {
self.instance.destroy_instance(None);
}和创建对象所用的 Vulkan 函数一样,用于销毁对象的 Vulkan 函数也接受一个可选的、指向自定义分配器回调的引用。所以和之前一样,我们传入 None 来使用默认的分配器行为。
不合规的 Vulkan 实现
不幸的是,并非每个平台都有一个完全符合 Vulkan 规范的 Vulkan API 的实现。在这样的平台上,可能会有一些标准的 Vulkan 特性是不可用的,或者 Vulkan 应用程序的实际行为与 Vulkan 规范有很大的不同。
在 Vulkan SDK 的 1.3.216 版本之后,使用不合规 Vulkan 实现的应用程序必须启用一些额外的 Vulkan 扩展。这些兼容性扩展的主要目的是强制开发人员承认他们的应用程序正在使用不合规的 Vulkan 实现,并且他们不期望一切都按 Vulkan 规范进行。
本教程会使用这些兼容性 Vulkan 扩展,这样你的程序就可以在缺少完全符合 Vulkan 实现的平台上运行了。
然而,你可能会问:“为什么我们要这么做?我们真的需要在一个入门级的 Vulkan 教程中考虑对小众平台的支持吗?”而事实证明,不那么小众的 macOS 就是那些缺少完全符合 Vulkan 实现的平台之一。
就如我们在介绍中提到的,Apple 有他们自己的底层图形 API,Metal。Vulkan SDK 为 macOS 提供的 Vulkan 实现(MoltenVK)是一个位于应用程序和 Metal 之间的中间层,它将应用程序所做的 Vulkan API 调用转换为 Metal API 调用。因为 MoltenVK 不完全符合 Vulkan 规范,所以你需要启用我们在本教程中将要讨论的兼容性 Vulkan 扩展来支持 macOS。
顺带一提,尽管 MoltenVK 不是完全合规的实现,但在 macOS 上实践本教程时,应该也是不会有任何问题的。
启用兼容性扩展
注意: 就算你用的不是 macOS,本节中添加的一些代码也会在本教程的后续部分中被引用,所以你不能跳过它们!
我们希望检查我们所用的 Vulkan 版本是否高于引入兼容性扩展要求的 Vulkan 版本。我们首先添加一个额外的导入:
use vulkanalia::Version;导入 vulkanalia::Version 之后,我们就可以定义一个常量来表示最低版本:
const PORTABILITY_MACOS_VERSION: Version = Version::new(1, 3, 216);接着,像这样修改枚举扩展并创建实例的代码:
let mut extensions = vk_window::get_required_instance_extensions(window)
.iter()
.map(|e| e.as_ptr())
.collect::<Vec<_>>();
// 从 Vulkan 1.3.216 之后,macOS 上的 Vulkan 实现需要启用额外的扩展
let flags = if
cfg!(target_os = "macos") &&
entry.version()? >= PORTABILITY_MACOS_VERSION
{
info!("Enabling extensions for macOS portability.");
extensions.push(vk::KHR_GET_PHYSICAL_DEVICE_PROPERTIES2_EXTENSION.name.as_ptr());
extensions.push(vk::KHR_PORTABILITY_ENUMERATION_EXTENSION.name.as_ptr());
vk::InstanceCreateFlags::ENUMERATE_PORTABILITY_KHR
} else {
vk::InstanceCreateFlags::empty()
};
let info = vk::InstanceCreateInfo::builder()
.application_info(&application_info)
.enabled_extension_names(&extensions)
.flags(flags);这些代码会在 Vulkan 版本高于我们定义的最小版本,而平台又缺乏完全合规的 Vulkan 实现(这里只检查了 macOS)的情况下启用 KHR_PORTABILITY_ENUMERATION_EXTENSION 兼容性扩展。
这段代码还会启用 KHR_GET_PHYSICAL_DEVICE_PROPERTIES2_EXTENSION 扩展。启用 KHR_PORTABILITY_SUBSET_EXTENSION 需要先启用这个扩展。我们在后面的教程中创建逻辑设备时会用到 KHR_PORTABILITY_SUBSET_EXTENSION 扩展。
Instance 和 vk::Instance
当我们调用 create_instance 函数时,我们得到的不是 Vulkan 函数 vkCreateInstance 返回的原始 Vulkan 实例,而是一个 vulkanalia 中的自定义类型,它将原始 Vulkan 实例和为该特定实例加载的函数结合在一起。
我们使用的 Instance 类型(从 vulkanalia 的 prelude 模块中导入)不应和 vk::Instance 混淆。vk::Instance 类型是原始的 Vulkan 实例。在后面的章节中,我们也会用到 Device 类型。和 Instance 类似的是,Device 也由原始 Vulkan 设备(vk::Device)和为该设备加载的函数组成。幸运的是,本教程中我们不需要直接使用 vk::Instance 或者 vk::Device,所以你不用担心弄混它们。
因为 Instance 中包含了 Vulkan 实例和与之关联的函数,所以 Instance 的函数封装也能够在需要原始 Vulkan 实例时提供它。
如果你查看 vkDestroyInstance 函数的文档,你会发现它接受两个参数:要销毁的实例和可选的自定义分配器回调。然而,destroy_instance 只接受可选的自定义分配器回调,因为它能够提供原始 Vulkan 实例作为第一个参数,就像上面描述的那样。
创建完实例之后,在继续进行更复杂的步骤之前,是时候拿出校验层,看看我们的调试功能了。
校验层
原文链接:https://kylemayes.github.io/vulkanalia/setup/validation_layers.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
Vulkan API 的设计秉持了尽可能降低驱动开销的理念,带来的影响就是 API 默认只提供极少的错误检查。即便是像把枚举设置成了一个非法值这样简单的错误也不会被显式处理,而是会导致程序崩溃或是未定义行为。由于 Vulkan 要求你明确你所做的事,你很容易就会犯下许多小错误,例如在使用一个 GPU 特性时忘记在创建逻辑设备时请求这个特性。
然而,这并不意味着 Vulkan API 就没法进行错误检查。Vulkan 引入了一个优雅的系统,叫做校验层(Validation Layer)。校验层是可选的,它们能在你调用 Vulkan 函数时插入钩子,执行额外的操作。一些常见的操作包括:
- 对比规范检查参数值,以检测是否有误用
- 追踪对象的创建和销毁,找出资源泄漏
- 通过追踪发起调用的线程,检查线程安全性
- 在标准输出中打印含有所有调用及其参数的日志
- 追踪 Vulkan 调用,用于性能分析(profiling)与重放(replay)
诊断校验层中一个函数的实现看起来就像这样(C 语言):
VkResult vkCreateInstance(
const VkInstanceCreateInfo* pCreateInfo,
const VkAllocationCallbacks* pAllocator,
VkInstance* instance
) {
if (pCreateInfo == nullptr || instance == nullptr) {
log("Null pointer passed to required parameter!");
return VK_ERROR_INITIALIZATION_FAILED;
}
return real_vkCreateInstance(pCreateInfo, pAllocator, instance);
}
你可以随意堆叠校验层来引入你感兴趣的调试功能。你只需为 Debug 构建启用校验层,而在 Release 构建禁用它们,就能使这两个构建获得最大收益。
Vulkan 并不内置任何校验层,但是 LunarG Vulkan SDK 提供了一系列校验层,用以检查常见的错误。它们是完全开源的,所以你可以找到它们能检查的错误类型,并且可以参与贡献。你的应用可能会因为无意中依赖于未定义行为而在不同的驱动程序上遇到错误,而要避免这种事,最好的方式就是使用校验层。
校验层只能在安装到系统中之后使用。比如 LunarG 校验层只能在安装了 Vulkan SDK 的电脑上使用。
之前,在 Vulkan 中有两种不同类型的校验层:实例(instance)特定的校验层与设备(device)特定的校验特定层。实例特定的校验层会检查与全局 Vulkan 对象 —— 例如 Vulkan 实例 —— 相关的调用,而设备特定的校验层只会检查与某个特定的 GPU 相关的调用。设备特定的校验层现在已经被弃用了,这也就意味着实例特定的校验层会对所有的 Vulkan 调用生效。规范文档依旧建议你出于兼容性考虑启用设备特定的校验层,而这在某些实现中是必须的。我们将简单地在逻辑设备级别指定与实例相同的校验层,稍后我们会看到。
在开始之前,我们需要为本章节添加一些新的引入:
use std::collections::HashSet;
use std::ffi::CStr;
use std::os::raw::c_void;
use vulkanalia::vk::ExtDebugUtilsExtension;HashSet 会被用来存储与查询支持的校验层,vk::ExtDebugUtilsExtension 提供管理调试功能的函数封装。其它引入会被用于记录校验层传来的消息。
使用校验层
在这个章节中,我们将会学习如何启用 Vulkan SDK 提供的标准校验层。和扩展一样,启用校验层需要指定它们的名称。在 SDK 中,所有有用的标准校验都被打包于 VK_LAYER_KHRONOS_validation 校验层中。
我们先给我们程序增加两个配置变量,一个用来指定需要启用的校验层,一个用来指定是否启用校验层。我决定根据程序是否使用 Debug 模式编译来选择是否启用校验层。
const VALIDATION_ENABLED: bool =
cfg!(debug_assertions);
const VALIDATION_LAYER: vk::ExtensionName =
vk::ExtensionName::from_bytes(b"VK_LAYER_KHRONOS_validation");我们给 create_instance 函数加一些新的代码,用来收集所有支持的实例特定校验层并将其存储在一个 HashSet 中,然后使用这个 HashSet 检查我们需要的校验层是否可用,并创建一个包含校验层名称的列表。这些代码应该放在构建 vk::ApplicationInfo 结构体的正下方:
let available_layers = entry
.enumerate_instance_layer_properties()?
.iter()
.map(|l| l.layer_name)
.collect::<HashSet<_>>();
if VALIDATION_ENABLED && !available_layers.contains(&VALIDATION_LAYER) {
return Err(anyhow!("Validation layer requested but not supported."));
}
let layers = if VALIDATION_ENABLED {
vec![VALIDATION_LAYER.as_ptr()]
} else {
Vec::new()
};然后,你需要调用 enabled_layer_names,在 vk::InstanceCreateInfo 中指定需要启用的校验层:
let info = vk::InstanceCreateInfo::builder()
.application_info(&application_info)
.enabled_layer_names(&layers)
.enabled_extension_names(&extensions)
.flags(flags);现在,在 Debug 模式下执行程序,并且确保没有跳出 Validation layer requested but not supported. 这条错误信息。如果看到报错信息,那你需要看一下 FAQ。如果一切顺利,那么 create_instance 应该永远都不会返回错误代码 vk::ErrorCode::LAYER_NOT_PRESENT,不过你还是应该运行程序以确保万无一失。
消息回调
默认情况下,校验层会将调试消息打印至标准输出,但我们也可以提供显式回调自己处理这些消息。这样我们可以自主决定处理哪些类型的消息,因为并非所有消息都是(致命)错误消息。如果你不想现在做这些事,你可以跳到本章的最后一节。
要在程序中配置一个处理消息和消息细节的回调,我们需要使用 VK_EXT_debug_utils 扩展配置一个带回调的调试信使(debug messenger)。
我们会往 create_instance 函数中函数添加更多代码。这次我们需要将 extensions 列表改为可变的,然后在校验层启用时将调试实用工具扩展(debug utilities extension)加入这个列表:
let mut extensions = vk_window::get_required_instance_extensions(window)
.iter()
.map(|e| e.as_ptr())
.collect::<Vec<_>>();
if VALIDATION_ENABLED {
extensions.push(vk::EXT_DEBUG_UTILS_EXTENSION.name.as_ptr());
}vulkanalia 为每个 Vulkan 扩展提供了一系列元数据。在这个例子中,我们只需要加载扩展的名称,所以我们将 vk::EXT_DEBUG_UTILS_EXTENSION 结构体常量的 name 字段的值添加到我们的扩展名称列表中。
运行程序,确保你没有收到 vk::ErrorCode::EXTENSION_NOT_PRESENT 错误代码。事实上,我们并不需要检查这个扩展是否存在,因为只要校验层可用,这个扩展就应该可用。
现在让我们看看调试回调函数是什么样的。添加一个名为 debug_callback 的 extern "system" 函数,它的签名与 vk::PFN_vkDebugUtilsMessengerCallbackEXT 原型相匹配。extern "system" 是必须的,这样 Vulkan 才能正确调用我们的 Rust 函数。
extern "system" fn debug_callback(
severity: vk::DebugUtilsMessageSeverityFlagsEXT,
type_: vk::DebugUtilsMessageTypeFlagsEXT,
data: *const vk::DebugUtilsMessengerCallbackDataEXT,
_: *mut c_void,
) -> vk::Bool32 {
let data = unsafe { *data };
let message = unsafe { CStr::from_ptr(data.message) }.to_string_lossy();
if severity >= vk::DebugUtilsMessageSeverityFlagsEXT::ERROR {
error!("({:?}) {}", type_, message);
} else if severity >= vk::DebugUtilsMessageSeverityFlagsEXT::WARNING {
warn!("({:?}) {}", type_, message);
} else if severity >= vk::DebugUtilsMessageSeverityFlagsEXT::INFO {
debug!("({:?}) {}", type_, message);
} else {
trace!("({:?}) {}", type_, message);
}
vk::FALSE
}第一个参数表示消息的严重程度,它可以有以下取值:
vk::DebugUtilsMessageSeverityFlagsEXT::VERBOSE– 诊断信息vk::DebugUtilsMessageSeverityFlagsEXT::INFO– 提示消息,例如资源的创建vk::DebugUtilsMessageSeverityFlagsEXT::WARNING– 行为不一定是错误,但很可能意味着你的程序有 bugvk::DebugUtilsMessageSeverityFlagsEXT::ERROR– 行为无效,可能会导致崩溃
枚举值被设置为递增的,这样就可以用比较运算符来检查一条消息是否比某个严重程度更严重。我们根据这一点来决定在记录消息时使用哪个 log 宏。
type_ 参数可以有以下取值:
vk::DebugUtilsMessageTypeFlagsEXT::GENERAL– 与规范或性能无关的事件vk::DebugUtilsMessageTypeFlagsEXT::VALIDATION– 违反规范或可能是错误的事件vk::DebugUtilsMessageTypeFlagsEXT::PERFORMANCE– 这个用法可能不是 Vulkan 的最佳实践
data 参数指向一个 vk::DebugUtilsMessengerCallbackDataEXT 结构体,它包含了消息本身的细节,其中最重要的成员是:
message– 调试信息,以空字符结尾的 C 字符串(*const c_char)objects– 与消息相关的 Vulkan 对象句柄数组object_count– 数组中对象的数量
最后一个参数 —— 这里用 _ 忽略 —— 包含了一个指针,它在回调函数设置时被指定,允许你将自己的数据传递给它。
回调函数返回一个布尔值,它表示触发校验层消息的 Vulkan 调用是否应该被中止。如果回调函数返回 true,那么这个调用就会被中止,并且返回错误代码 vk::ErrorCode::VALIDATION_FAILED_EXT。这通常只用于测试校验层本身,所以你应该总是返回 vk::FALSE。
现在我们需要告诉 Vulkan 关于回调函数的事情。也许有点出乎意料,在 Vulkan 中,即使是调试回调函数也需要被显式地创建和销毁。这样的回调函数是调试信使(debug messenger)的一部分,你可以有任意多个这样的回调函数。在 AppData 结构体中添加一个字段:
struct AppData {
messenger: vk::DebugUtilsMessengerEXT,
}修改 create_instance 函数的签名与结尾,让它变得像这样:
unsafe fn create_instance(
window: &Window,
entry: &Entry,
data: &mut AppData
) -> Result<Instance> {
// ...
let instance = entry.create_instance(&info, None)?;
if VALIDATION_ENABLED {
let debug_info = vk::DebugUtilsMessengerCreateInfoEXT::builder()
.message_severity(vk::DebugUtilsMessageSeverityFlagsEXT::all())
.message_type(
vk::DebugUtilsMessageTypeFlagsEXT::GENERAL
| vk::DebugUtilsMessageTypeFlagsEXT::VALIDATION
| vk::DebugUtilsMessageTypeFlagsEXT::PERFORMANCE,
)
.user_callback(Some(debug_callback));
data.messenger = instance.create_debug_utils_messenger_ext(&debug_info, None)?;
}
Ok(instance)
}注: 对 Vulkan 标志类型调用静态方法
all(例如以上代码中的vk::DebugUtilsMessageSeverityFlagsEXT::all())会返回vulkanalia已知的所有标志。完整的标志集合中可能包括仅当特定扩展启用时才有效的标志,或是在比你所用/所面向的 Vulkan 版本更高的版本中才可用的标志。在以上代码中,我们明确列出了我们需要使用的
vk::DebugUtilsMessageTypeFlagsEXT标志,因为这个标志集包含了一个标志(vk::DebugUtilsMessageTypeFlagsEXT::DEVICE_ADDRESS_BINDING),它只有在启用了某个特定扩展 时才有效。多数情况下,使用不支持的标志不会导致任何错误或改变应用程序的行为,但如果你启用了校验层(正如我们在本章中所做的那样),那么它肯定会导致校验错误。
首先,我们从返回表达式中提取出 Vulkan 实例,这样我们就可以用它来添加我们的调试回调函数。
接着,我们构造一个 vk::DebugUtilsMessengerCreateInfoEXT 结构体,它提供了和我们的调试回调函数以及如何调用这个函数有关的信息。
message_severity 字段允许你指定你的回调函数感兴趣的所有严重程度类型。我请求所有严重程度的消息都被包含。这通常会产生大量的冗长的调试信息,但是我们可以在不感兴趣的时候通过日志级别来过滤掉这些信息。
类似地,message_type 字段允许你过滤你的回调函数感兴趣的消息类型。我在这里启用了所有类型。如果某些类型的消息对你没用,你可以禁用它们。
最后,user_callback 字段指定了回调函数。你可以选择传递一个可变引用给 user_data 字段,它会通过最后一个参数传递给回调函数。比如,你可以使用这个来传递一个指向 AppData 结构体的指针。
最后,我们调用 create_debug_utils_messenger_ext 来把我们的调试回调函数注册到 Vulkan 实例中。
因为 create_instance 函数接受一个 AppData 的引用,我们还需要更新 App 和 App::create:
注意:
AppData::default()会使用AppData结构体上的#[derive(Default)]生成的Defaulttrait 的实现。这会导致像Vec这样的容器被初始化为空列表,而像vk::DebugUtilsMessengerEXT这样的 Vulkan 句柄被初始化为空句柄。如果 Vulkan 句柄在使用之前没有被正确初始化,我们在本章中启用的校验层应该会告诉我们遗漏了什么。
struct App {
entry: Entry,
instance: Instance,
data: AppData,
}
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
let mut data = AppData::default();
let instance = create_instance(window, &entry, &mut data)?;
Ok(Self { entry, instance, data })
}
}在程序退出前,我们创建的 vk::DebugUtilsMessengerEXT 对象需要被清理。我们会在 App::destroy中,在销毁实例之前做这件事:
unsafe fn destroy(&mut self) {
if VALIDATION_ENABLED {
self.instance.destroy_debug_utils_messenger_ext(self.data.messenger, None);
}
self.instance.destroy_instance(None);
}创建与销毁调试实例
尽管我们已经通过校验层添加了调试功能,但活还没完全干完。调用 create_debug_utils_messenger_ext 需要一个有效的实例,而 destroy_debug_utils_messenger_ext 必须在实例被销毁前调用。这意味着我们现在还不能调试 create_instance 和 destroy_instance 调用中的任何问题。
不过,如果你仔细阅读过扩展文档,你就会看到,还有一种方式可以为这两个函数调用创建一个单独的调试信使。只需在 vk::InstanceCreateInfo 的 next 扩展字段中传递一个指向 vk::DebugUtilsMessengerCreateInfoEXT 结构体的指针即可。在这么做之前,我们先来讨论一下在 Vulkan 中如何扩展结构体。
我们在概览章节的生成器那一节提到过,许多 Vulkan 结构体中都有一个 s_type 字段。它必须设置成正确的 vk::StructureType 枚举变体,以指示结构体的类型(例如,vk::ApplicationInfo 结构体的 s_type 字段必须设置成 vk::StructureType::APPLICATION_INFO)。
你可能好奇过这个字段的目的是什么:Vulkan 不是已经知道传递给它的结构体的类型了吗?事实上,这个字段与 next 字段的目的紧密相关:它提供了扩展 Vulkan 结构体的能力。
Vulkan 结构体中的 next 字段可以用来指定一个结构体指针链。next 可以是空指针,也可以是一个指向 Vulkan 结构体的指针,Vulkan 可以利用这一点来扩展结构体。这个链中的每个结构体都可以为传递给 Vulkan 函数的根结构体提供额外的信息。Vulkan 的这个特性允许在不破坏向后兼容性的情况下扩展 Vulkan 函数的功能。
当你将这样的结构体链传递给 Vulkan 函数时,Vulkan 函数将会遍历结构体链以收集链中所有结构体的信息。因此,Vulkan 不知道链中每个结构体的类型,这就需要 s_type 字段。
vulkanalia 提供的生成器能够轻松地以类型安全的方式构建这样的结构体链。例如,看一下 vk::InstanceCreateInfoBuilder 生成器,特别是 push_next 方法。这个方法允许将任何实现了 vk::ExtendsInstanceCreateInfo trait 的 Vulkan 结构体添加到 vk::InstanceCreateInfo 的结构体链中。
vk::DebugUtilsMessengerCreateInfoEXT 便是这种结构体之一,我们会用它来扩展 vk::InstanceCreateInfo 结构,以设置我们的调试回调函数。为了做到这一点,继续修改 create_instance 函数,这一次我们会把 info 结构体变成可变的,这样我们就可以修改它的指针链。然后将 debug_info 结构体 —— 现在也是可变的 —— 放在 info 结构体的下面,这样我们就可以将它推到 info 的指针链上:
let mut info = vk::InstanceCreateInfo::builder()
.application_info(&application_info)
.enabled_layer_names(&layers)
.enabled_extension_names(&extensions)
.flags(flags);
let mut debug_info = vk::DebugUtilsMessengerCreateInfoEXT::builder()
.message_severity(vk::DebugUtilsMessageSeverityFlagsEXT::all())
.message_type(
vk::DebugUtilsMessageTypeFlagsEXT::GENERAL
| vk::DebugUtilsMessageTypeFlagsEXT::VALIDATION
| vk::DebugUtilsMessageTypeFlagsEXT::PERFORMANCE,
)
.user_callback(Some(debug_callback));
if VALIDATION_ENABLED {
info = info.push_next(&mut debug_info);
}**注:**在这里选择同样的调试信息,包括相同的严重程度、类型和回调函数,既调用
create_debug_utils_messenger_ext又添加到vk::InstanceCreateInfo实例的扩展中,可能看起来有些多余。然而,这两种用法有不同的目的。这里的用法(将调试信息添加到vk::InstanceCreateInfo)设置了在创建和销毁实例期间的调试。调用create_debug_utils_messenger_ext为其他一切设置了持久性调试。请参阅 Vulkan 规范中相关章节中以 "To capture events that occur while creating or destroying an instance" 开头的段落。
debug_info 需要在条件语句之外定义,因为它需要一直存活到我们调用完 create_instance 之后。幸运的是,我们可以依赖 Rust 编译器来保护我们:因为 vulkanalia 生成器定义的生命周期,我们无法将一个活得不够长的结构体推到指针链上。
现在我们可以运行程序,观察调试回调函数打印的日志了。不过我们要先设置 RUST_LOG 环境变量,这样 pretty_env_logger 就会启用我们感兴趣的日志级别。我们先把日志级别设置为 debug,以确定这些东西工作正常。下面是在 Windows(PowerShell)上的一个例子:
如果一切正常,那你应该不会看到任何警告或者错误信息。接下来,你可能想要使用 RUST_LOG=info 来减少日志的冗长程度,除非你是在调试错误。
配置
除了 vk::DebugUtilsMessengerCreateInfoEXT 结构中的标志之外,还有更多针对校验层行为的配置项目。浏览 Vulkan SDK 所在的位置,进入 Config 目录。你会在这里找到一个 vk_layer_settings.txt 文件,它解释了如何配置校验层的行为。
要为你自己的应用程序配置校验层,你需要将文件复制到项目可执行文件的工作目录,并按照说明设置所需的行为。不过,在本教程的其余部分,我将假设你使用默认设置。
在本教程中,我会故意制造一些错误,以展示校验层是如何帮助你捕获这些错误的,并告诉你与 Vulkan 共事时清楚自己在做什么是多么重要。现在是时候看看系统中的 Vulkan 设备了。
物理设备与队列族
原文链接:https://kylemayes.github.io/vulkanalia/setup/physical_devices_and_queue_families.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在通过 Instance 初始化 Vulkan 库之后,我们需要在系统中选择一个支持我们所需功能的图形处理器。事实上,我们可以选择任意多个图形处理器,并同时使用它们,不过在本教程中我们只会选择第一个满足我们需求的图形处理器。
我们会添加一个 pick_physical_device 函数,用来枚举并选择图形处理器,然后将图形处理器及其相关信息存储在 AppData 中。这个函数及其调用的函数会使用一个自定义的错误类型(SuitabilityError)来表示物理设备不满足应用程序的需求。这个错误类型会使用 thiserror crate 来自动实现错误类型需要的所有的样板代码。
use thiserror::Error;
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
pick_physical_device(&instance, &mut data)?;
Ok(Self { entry, instance, data })
}
}
#[derive(Debug, Error)]
#[error("Missing {0}.")]
pub struct SuitabilityError(pub &'static str);
unsafe fn pick_physical_device(instance: &Instance, data: &mut AppData) -> Result<()> {
Ok(())
}被选中的物理设备会被存储在我们刚添加到 AppData 结构体的 vk::PhysicalDevice 句柄中。当 Instance 被销毁时,这个对象也会被隐式销毁,所以我们不需要在 App::destroy 方法中做任何额外的工作。
struct AppData {
// ...
physical_device: vk::PhysicalDevice,
}设备的适用性
我们需要一种方法来确定一个物理设备是否符合我们的需求。我们会创建一个用来检测设备适用性的函数,如果我们传给这个函数的物理设备不能完全支持我们需要的功能,那么这个函数会返回一个 SuitabilityError 错误:
unsafe fn check_physical_device(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
Ok(())
}要评估一个物理设备是否满足我们的需求,我们需要从设备中查询一些详细信息。设备的名称、类型和支持的 Vulkan 版本等基本信息可以使用 get_physical_device_properties 查询:
let properties = instance
.get_physical_device_properties(physical_device);设备对可选特性,例如纹理压缩、64 位浮点类型和多视口渲染(在 VR 中很有用)的支持则可以使用 get_physical_device_features 查询:
let features = instance
.get_physical_device_features(physical_device);我们会在讨论设备内存和队列族(见下一节)的时候再讨论更多可以查询的设备细节。
举个例子,假设我们的应用程序只能在支持几何着色器(geometry shader)的独立显卡上运行。那么 check_physical_device 函数可能如下所示:
unsafe fn check_physical_device(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
let properties = instance.get_physical_device_properties(physical_device);
if properties.device_type != vk::PhysicalDeviceType::DISCRETE_GPU {
return Err(anyhow!(SuitabilityError("Only discrete GPUs are supported.")));
}
let features = instance.get_physical_device_features(physical_device);
if features.geometry_shader != vk::TRUE {
return Err(anyhow!(SuitabilityError("Missing geometry shader support.")));
}
Ok(())
}相比于直接选择第一个合适的设备,你也可以给每个设备评分,然后选择得分最高的那个。这样你就可以通过给独立显卡一个更高的分数来优先选择独立显卡,但是如果只有集成显卡可用,就回退到集成显卡。你也可以直接显示设备的名称,然后让用户自行选择。
接下来,我们会讨论第一个我们真正需要的功能。
队列族
之前已经介绍过,在 Vulkan 中进行任何操作(从绘制到纹理上传)基本都要将指令提交到队列。不同的队列族能够产生不同种类的队列,而每个队列族都只支持一部分指令。例如,一个队列族可能只允许处理计算指令,或者只允许处理内存传输相关的指令。
我们需要查询设备支持的队列族,并且找到一个支持我们所需指令的队列族。为此,我们添加一个新的结构体 QueueFamilyIndices 来存储我们需要的队列族的索引。
现在,我们只要找到一个支持图形指令的队列族就好了,那么 QueueFamilyIndices 结构体和它的 impl 块看起来就像这样:
#[derive(Copy, Clone, Debug)]
struct QueueFamilyIndices {
graphics: u32,
}
impl QueueFamilyIndices {
unsafe fn get(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<Self> {
let properties = instance
.get_physical_device_queue_family_properties(physical_device);
let graphics = properties
.iter()
.position(|p| p.queue_flags.contains(vk::QueueFlags::GRAPHICS))
.map(|i| i as u32);
if let Some(graphics) = graphics {
Ok(Self { graphics })
} else {
Err(anyhow!(SuitabilityError("Missing required queue families.")))
}
}
}get_physical_device_queue_familiy_properties 返回的队列属性包含了许多关于物理设备支持的队列族的细节,包括队列族支持的操作类型,以及基于这个队列族能创建多少队列。这里我们要找到第一个支持图形操作的队列族,这个队列族的标志是 vk::QueueFlags::GRAPHICS。
有了这个酷毙了的队列族查询方法,我们就可以在 check_physical_device 函数中使用它,来检查物理设备是否能够处理我们想要使用的指令:
unsafe fn check_physical_device(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
QueueFamilyIndices::get(instance, data, physical_device)?;
Ok(())
}最后,我们遍历所有物理设备,并选中第一个通过 check_physical_device 函数检测、符合我们要求的设备。我们更新 pick_physical_device 函数:
unsafe fn pick_physical_device(instance: &Instance, data: &mut AppData) -> Result<()> {
for physical_device in instance.enumerate_physical_devices()? {
let properties = instance.get_physical_device_properties(physical_device);
if let Err(error) = check_physical_device(instance, data, physical_device) {
warn!("Skipping physical device (`{}`): {}", properties.device_name, error);
} else {
info!("Selected physical device (`{}`).", properties.device_name);
data.physical_device = physical_device;
return Ok(());
}
}
Err(anyhow!("Failed to find suitable physical device."))
}好极了,这就是我们找到正确的物理设备所需要的一切!下一步是创建一个逻辑设备来与之交互。
逻辑设备与队列
原文链接:https://kylemayes.github.io/vulkanalia/setup/logical_device_and_queues.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
选择了要使用的物理设备之后,我们需要创建一个与之交互的逻辑设备。创建逻辑设备的过程与创建实例的过程相似,即描述我们希望使用的功能。既然我们已经查询了可用的队列族,我们还需要指定要创建哪些队列。如果你有不同的需求,甚至可以从同一个物理设备创建多个逻辑设备。
首先,在 App 中添加一个新的字段来存储逻辑设备:
struct App {
// ...
device: Device,
}接下来,在 App::create 中调用 create_logical_device 函数,并将得到的逻辑设备添加到 App 的构造器中:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
let device = create_logical_device(&entry, &instance, &mut data)?;
Ok(Self { entry, instance, data, device })
}
}
unsafe fn create_logical_device(
entry: &Entry,
instance: &Instance,
data: &mut AppData,
) -> Result<Device> {
}指定要创建的队列
创建逻辑设备需要再创建一堆结构体来指定一堆细节,首先是 vk::DeviceQueueCreateInfo。这个结构体描述了我们单个队列族需要的队列数量。现在,我们只对具备图形功能的队列感兴趣。
let indices = QueueFamilyIndices::get(instance, data, data.physical_device)?;
let queue_priorities = &[1.0];
let queue_info = vk::DeviceQueueCreateInfo::builder()
.queue_family_index(indices.graphics)
.queue_priorities(queue_priorities);当前可用的驱动程序只允许你为每个队列族创建少量队列,实际上你也确实不需要多个队列。因为你可以在多个线程上创建指令缓冲,然后在主线程上一次性提交它们,这样只需要一次低开销的调用。
Vulkan 允许你为队列分配优先级,使用介于 0.0 和 1.0 之间的浮点数来影响指令缓冲执行的调度。即使只创建一个队列,也需要指定优先级。
指定要启用的层
接下来要提供的信息与 vk::InstanceCreateInfo 结构体相似。同样地,我们需要指定要启用的任何校验层或扩展,但这次指定的扩展是设备特定的,而不是全局的。
一个设备特定扩展的例子是 VK_KHR_swapchain,它允许你将该设备渲染的图像呈现到窗口中。一些 Vulkan 设备,例如仅支持计算操作的设备,可能不具备此功能。我们将在交换链章节中再次提到这个扩展。
Vulkan 以前的实现区分了实例和设备特定的校验层,但现在不再是这样了。这意味着在最新的实现中,我们传递给 enabled_layer_names 的层名将被忽略。不过,为了与旧版本兼容,还是应该设置这些名称。
我们还不会启用任何设备特定的扩展。因此,如果启用了校验,我们将构建一个包含校验层的层名列表。
let layers = if VALIDATION_ENABLED {
vec![VALIDATION_LAYER.as_ptr()]
} else {
vec![]
};指定要启用的扩展
正如 实例 一章中所讨论的,对于使用不完全符合 Vulkan 规范的 Vulkan 实现的应用程序,必须启用某些 Vulkan 扩展。在本章中,我们启用了与这些不符合规范的实现兼容所需的实例扩展。在这里,我们将启用出于同样目的所需的设备扩展。
let mut extensions = vec![];
// Required by Vulkan SDK on macOS since 1.3.216.
if cfg!(target_os = "macos") && entry.version()? >= PORTABILITY_MACOS_VERSION {
extensions.push(vk::KHR_PORTABILITY_SUBSET_EXTENSION.name.as_ptr());
}指定使用的设备功能
下一个需要指定的信息是我们将要使用的设备特性。这些特性是我们在上一章中通过 get_physical_device_features 查询到的,比如几何着色器。现在我们不需要任何特殊的东西,所以我们可以简单地定义它,并将所有东西都保留为默认值(false)。一旦我们要开始使用 Vulkan 做更有趣的事情,我们会再回到这个结构。
let features = vk::PhysicalDeviceFeatures::builder();创建逻辑设备
有了前面两个结构体、启用的校验层(如果启用)以及设备扩展,我们可以填充最主要的 vk::DeviceCreateInfo 结构体。
let queue_infos = &[queue_info];
let info = vk::DeviceCreateInfo::builder()
.queue_create_infos(queue_infos)
.enabled_layer_names(&layers)
.enabled_extension_names(&extensions)
.enabled_features(&features);就是这样,我们现在可以调用名为 create_device 的方法来实例化逻辑设备了。
let device = instance.create_device(data.physical_device, &info, None)?;参数是要与逻辑设备交互的物理设备、我们刚刚指定的队列和使用信息,以及可选的分配回调。与实例创建函数类似,如果启用不存在的扩展或指定了不支持的功能,则此调用可能会返回错误。
设备应在 App::destroy 中被销毁:
unsafe fn destroy(&mut self) {
self.device.destroy_device(None);
// ...
}逻辑设备不直接与实例交互,因此不作为参数。
检索队列句柄
队列会随着逻辑设备的创建而自动创建,但我们还没有取得与它们交互所用的句柄。首先,在 AppData 中添加一个新的字段来存储图形队列的句柄:
struct AppData {
// ...
graphics_queue: vk::Queue,
}设备队列会在设备销毁时自动清理,所以我们不需要在 App::destroy 中做任何处理。
我们可以使用 get_device_queue 函数来检索每个队列族的队列句柄。参数是逻辑设备、队列族和队列序号。因为我们只从该族中创建一个队列,所以我们只需使用序号 0。
data.graphics_queue = device.get_device_queue(indices.graphics, 0);最后,在 create_logical_device 中返回创建的逻辑设备:
Ok(device)有了逻辑设备和队列句柄,我们现在就可以真正开始使用显卡来执行任务了!在接下来的几章中,我们将设置资源以将结果呈现给窗口系统。
窗口表面
原文链接:https://kylemayes.github.io/vulkanalia/presentation/window_surface.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
Vulkan 是一个平台无关的 API,因此它不能直接与窗口系统进行交互。要在屏幕上呈现结果,我们需要使用一系列 WSI(Window System Interface,窗口系统接口)扩展来建立 Vulkan 与窗口系统之间的连接。在本章中,我们将讨论第一个扩展,即 VK_KHR_surface。它暴露了一个 vk::SurfaceKHR 类型,表示一种用于呈现图像的抽象表面。我们程序中的窗口表面将由我们用 winit 打开的窗口来支持。
VK_KHR_surface 扩展是一个实例级扩展,我们实际上已经启用了它,因为它被包含在 vk_window::get_required_instance_extensions 返回的列表中。该列表还包含了我们将在接下来的几章中使用的其他 WSI 扩展。
窗口表面需要在创建实例之后立即创建,因为窗口表面实际上会影响物理设备的选择。我们之所以现在才讲窗口表面的创建,是因为窗口表面是“渲染目标与呈现”这一更大主题的一部分,在“基本设置”那部分里解释窗口表面会引起混乱。此外还要注意,窗口表面是 Vulkan 里一个完全可选的组件,如果你只需要离屏渲染,Vulkan 也可以在不创建窗口的情况下进行渲染(而 OpenGL 就必须用创建一个不可见窗口这种投机取巧的方式)。
要使用 VK_KHR_surface 扩展,我们除了要导入 vk::SurfaceKHR 类型,还需要导入 vulkanalia 的扩展 trait vk::KhrSurfaceExtension:
use vulkanalia::vk::SurfaceKHR
use vulkanalia::vk::KhrSurfaceExtension;创建窗口表面
首先,在 AppData 中,在其他字段的上面添加一个 surface 字段:
struct AppData {
surface: vk::SurfaceKHR,
// ...
}虽然 vk::SurfaceKHR 对象及其用法是与平台无关的,但创建它的过程不是,创建 vk::SurfaceKHR 的具体过程依赖于窗口系统的细节。例如在 Windows 上,创建 vk::SurfaceKHR 需要 HWND 和 HMODULE 句柄。因此,扩展中有一个特定于平台的附加部分,例如在 Windows 上,它是 VK_KHR_win32_surface。平台特定的附加部分也会被自动包含在 vk_window::get_required_instance_extensions 的列表中。
我将演示如何在 Windows 上使用这个特定于平台的扩展来创建表面,但实际上在本教程中我们不会使用它。vulkanalia 已经提供了 vk_window::create_surface,它可以处理平台之间的差异。不过在我们开始使用它之前,了解幕后的工作原理是很有好处的。
因为窗口表面是一个 Vulkan 对象,所以和其他 Vulkan 对象一样,创建它需要填充一个的 vk::Win32SurfaceCreateInfoKHR 结构体。它有两个重要的参数:hinstance 和 hwnd,分别是进程和窗口的句柄。
use winit::platform::windows::WindowExtWindows;
let info = vk::Win32SurfaceCreateInfoKHR::builder()
.hinstance(window.hinstance())
.hwnd(window.hwnd());WindowExtWindows 特性是从 winit 中导入的,它允许我们在 winit 的 Window 结构体上访问平台特定的方法。在这种情况下,它允许我们获取由 winit 创建的窗口所在进程的句柄(hinstance)和窗口的句柄(hwnd)。
之后使用 create_win32_surface_khr 创建表面,该函数包括用于表面创建的详细信息和自定义分配器的参数。从技术上讲,这是一个 WSI 扩展函数,但它的使用频率很高,所以标准的 Vulkan 加载器也会加载它,因而它不需要像其他扩展一样显式加载。不过我们还是需要为扩展 VK_KHR_win32_surface 导入 vulkanalia 的扩展 trait vk::KhrWin32SurfaceExtension。
use vk::KhrWin32SurfaceExtension;
let surface = instance.create_win32_surface_khr(&info, None).unwrap();在其他平台(如 Linux)上创建表面的过程也和上面类似。例如在 Linux 上需要使用 create_xcb_surface_khr 函数,该函数接受 XCB 连接和窗口,并在背后调用 X11 的 API。
vk_window::create_surface 函数在不同的平台上使用不同的实现执行完全相同的操作。现在,我们将其集成到程序中。在 App::create 中,在选择物理设备之前,调用该函数:
unsafe fn create(window: &Window) -> Result<Self> {
// ...
let instance = create_instance(window, &entry, &mut data)?;
data.surface = vk_window::create_surface(&instance, &window, &window)?;
pick_physical_device(&instance, &mut data)?;
// ...
}参数是 Vulkan 实例和 winit 窗口。一旦我们创建了表面,我们就需要在 App::destroy 中使用 Vulkan API 销毁它:
unsafe fn destroy(&mut self) {
// ...
self.instance.destroy_surface_khr(self.data.surface, None);
self.instance.destroy_instance(None);
}确保在销毁实例之前销毁表面。
查询呈现(presentation)支持
尽管 Vulkan 的实现可能支持窗口系统集成,但这并不意味着系统中的每个设备都支持。因此,我们需要扩展 pick_physical_device 函数的功能,以确保我们选择的设备能够向我们创建的表面呈现图像。因为呈现是与队列相关的功能,所以我们实际上是要找到一个支持向我们创建的表面进行呈现的队列族。
事实上,支持绘制指令的队列族和支持呈现的队列族可能并不重叠。因此,我们必须考虑呈现队列不同于图形队列的可能性,并修改 QueueFamilyIndices 结构体来解决此问题:
struct QueueFamilyIndices {
graphics: u32,
present: u32,
}接下来,我们将修改 QueueFamilyIndices::get 方法,以查找能向我们的窗口表面进行呈现的队列族。该方法使用 get_physical_device_surface_support_khr 函数,它以物理设备、队列族索引和表面为参数,并返回这个物理设备、队列族和表面的组合是否支持呈现:
let mut present = None;
for (index, properties) in properties.iter().enumerate() {
if instance.get_physical_device_surface_support_khr(
physical_device,
index as u32,
data.surface,
)? {
present = Some(index as u32);
break;
}
}我们还需要将 present 添加到最终的表达式中:
if let (Some(graphics), Some(present)) = (graphics, present) {
Ok(Self { graphics, present })
} else {
Err(anyhow!(SuitabilityError("Missing required queue families.")))
}请注意,这两个索引最终很可能指涉到相同的队列族,但在整个程序中,我们将把它们视为独立的队列,这样我们就可以用统一的方式来处理它们。你也可以添加逻辑来优先选择能在同一个队列中进行绘制和呈现的物理设备,以提高性能。
创建呈现队列
最后一件事是修改逻辑设备的创建过程,以创建呈现队列并取得其 vk::Queue 句柄。在 AppData 中添加一个字段来保存呈现队列的句柄:
struct AppData {
// ...
present_queue: vk::Queue,
}接下来,我们需要创建多个 vk::DeviceQueueCreateInfo 结构体来从两个队列族中创建队列。一种简单的方法是创建一个集合,用来去重并保存所有需要的队列族。我们将在 create_logical_device 函数中完成这个操作:
let indices = QueueFamilyIndices::get(instance, data, data.physical_device)?;
let mut unique_indices = HashSet::new();
unique_indices.insert(indices.graphics);
unique_indices.insert(indices.present);
let queue_priorities = &[1.0];
let queue_infos = unique_indices
.iter()
.map(|i| {
vk::DeviceQueueCreateInfo::builder()
.queue_family_index(*i)
.queue_priorities(queue_priorities)
})
.collect::<Vec<_>>();然后删除之前的 queue_infos 切片,并为 vk::DeviceCreateInfo 提供一个 queue_infos 列表的引用:
let info = vk::DeviceCreateInfo::builder()
.queue_create_infos(&queue_infos)
.enabled_layer_names(&layers)
.enabled_extension_names(&extensions)
.enabled_features(&features);最后,添加一个调用来获取队列句柄:
data.present_queue = device.get_device_queue(indices.present, 0);如果队列族相同,那么现在这两个句柄很可能具有相同的值。在下一章中,我们将讨论交换链以及它们如何使我们能够向表面呈现图像。
交换链
原文链接:https://kylemayes.github.io/vulkanalia/presentation/swapchain.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
Vulkan 没有“默认帧缓冲”(default framebuffer)的概念,因此,Vulkan 需要一个结构来持有我们将要绘制的帧缓冲,这个架构就是交换链。在 Vulkan 中,交换链必须被显式创建。交换链本质上就是一个队列,其中充满了等待呈现到屏幕上的图像。我们的应用程序每次会从这个队列中获取一张图像,在上面绘制,然后将它返还到队列中。交换链的设置决定了这个队列如何工作,以及何时呈现队列中的图像,但通常来说,交换链的目的是使图像的呈现与屏幕刷新率同步。
检测交换链支持
出于某些原因,不是所有的显卡都能直接向屏幕呈现图像,例如有些显卡是为服务器设计的,没有图像输出接口。其次,呈现图像和窗口系统以及与窗口系统关联的表面密切相关。因此,交换链不是 Vulkan 核心的一部分。你必须先查询设备对交换链扩展 VK_KHR_swapchain 的支持,然后启用它。
像之前一样,我们首先导入 vulkanalia 的扩展 trait vk::KhrSwapchainExtension:
use vulkanalia::vk::KhrSwapchainExtension;接着,我们扩展 check_physical_device 函数,增加对 VK_KHR_swapchain 扩展支持的检查。我们之前已经看过如何列出一个物理设备支持的扩展,所以这一步应该非常直观。
首先声明一个所需设备扩展的列表,这一步和启用校验层的列表类似:
const DEVICE_EXTENSIONS: &[vk::ExtensionName] = &[vk::KHR_SWAPCHAIN_EXTENSION.name];然后创建一个新函数 check_physical_device_extensions 作为 check_physical_device 的附加检查:
unsafe fn check_physical_device(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
QueueFamilyIndices::get(instance, data, physical_device)?;
check_physical_device_extensions(instance, physical_device)?;
Ok(())
}
unsafe fn check_physical_device_extensions(
instance: &Instance,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
Ok(())
}修改 check_physical_device_extensions 的函数体,枚举设备支持的所有扩展,并检查其中是否包含所有所需的扩展:
unsafe fn check_physical_device_extensions(
instance: &Instance,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
let extensions = instance
.enumerate_device_extension_properties(physical_device, None)?
.iter()
.map(|e| e.extension_name)
.collect::<HashSet<_>>();
if DEVICE_EXTENSIONS.iter().all(|e| extensions.contains(e)) {
Ok(())
} else {
Err(anyhow!(SuitabilityError("Missing required device extensions.")))
}
}现在运行代码,确保你的显卡支持交换链的创建。值得注意的是,我们在前一章检查呈现队列的可用性时,已经隐式地检查了交换链扩展的支持。不过显式地检查一下也好,而且交换链扩展必须显式地启用。
启用设备扩展
使用交换链需要先启用 VK_KHR_swapchain 扩展。启用扩展只需要在 create_logical_device 函数中对设备扩展列表进行一点小小的修改。使用 DEVICE_EXTENSIONS 构造一个由空结尾的字符串组成的列表,来初始化我们的设备扩展列表:
let mut extensions = DEVICE_EXTENSIONS
.iter()
.map(|n| n.as_ptr())
.collect::<Vec<_>>();查询交换链支持的细节
只检查交换链是否可用还不够,因为它不一定和我们的窗口表面兼容。创建交换链还需要更多的设置,因此在继续推进之前,我们需要查询更多的细节。
总的来说,我们需要检查三种基本属性:
- 基本的表面能力(交换链中图像的最小/最大数量,图像的最小/最大宽度和高度)
- 表面格式(像素格式,颜色空间)
- 可用的呈现模式
与 QueueFamilyIndices 类似,我们会使用一个结构体来存储这些细节:
#[derive(Clone, Debug)]
struct SwapchainSupport {
capabilities: vk::SurfaceCapabilitiesKHR,
formats: Vec<vk::SurfaceFormatKHR>,
present_modes: Vec<vk::PresentModeKHR>,
}现在我们创建一个新的方法 SwapchainSupport::get,用来初始化这个结构体,填充我们所需的所有字段:
impl SwapchainSupport {
unsafe fn get(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<Self> {
Ok(Self {
capabilities: instance
.get_physical_device_surface_capabilities_khr(
physical_device, data.surface)?,
formats: instance
.get_physical_device_surface_formats_khr(
physical_device, data.surface)?,
present_modes: instance
.get_physical_device_surface_present_modes_khr(
physical_device, data.surface)?,
})
}
}这些字段的含义以及它们包含的数据的确切含义将在下一节中讨论。
现在,所有细节都在这个结构体里了,让我们再扩展一次 check_physical_device 函数,用这个方法来验证交换链的支持是否足够。只要交换链支持至少一种图像格式,以及至少一种给定窗口表面的呈现模式,那么这个交换链就可以满足本教程的需求。
unsafe fn check_physical_device(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
// ...
let support = SwapchainSupport::get(instance, data, physical_device)?;
if support.formats.is_empty() || support.present_modes.is_empty() {
return Err(anyhow!(SuitabilityError("Insufficient swapchain support.")));
}
Ok(())
}注意我们必须在确认交换链扩展可用之后,再检查交换链支持。
为交换链选择正确的设置
如果交换链满足我们刚刚所说的那些条件,那么这个交换链肯定是够用了。但交换链支持的设置很多,我们还需要做到最好。我们现在要写一些函数来找到最佳的交换链设置。有三种类型的设置需要确定:
- 表面格式(颜色深度)
- 呈现模式(将图像“交换”到屏幕的条件)
- 交换范围(swap extent)(交换链中图像的分辨率)
每一种设置都有一个理想值,如果这个理想值可用,我们就使用它,否则我们就创建一些逻辑来找到次佳的值。
表面格式
我们从一个下面这样的函数开始,稍后我们会把 SwapchainSupport 结构体的 formats 字段传给它作参数:
fn get_swapchain_surface_format(
formats: &[vk::SurfaceFormatKHR],
) -> vk::SurfaceFormatKHR {
}vk::SurfaceFormatKHR 有 format 和 color_space 两个成员。format 指定颜色的通道数和类型。例如,vk::Format::B8G8R8A8_SRGB 表示我们按照 B、G、R 和 alpha 通道的顺序存储颜色,每个通道使用 8 位无符号整数,每像素总共 32 位。color_space 成员使用 vk::ColorSpaceKHR::SRGB_NONLINEAR 标志表示是否支持 sRGB 颜色空间。
因为 sRGB 颜色空间可以更准确地表示颜色,所以我们会优先使用它。它也是纹理等图像的标准颜色空间。因此,我们也应该优先使用 sRGB 颜色格式,其中最常见的一个就是 vk::Format::B8G8R8A8_SRGB。
让我们遍历 formats 列表,看看是否有我们想要的组合:
fn get_swapchain_surface_format(
formats: &[vk::SurfaceFormatKHR],
) -> vk::SurfaceFormatKHR {
formats
.iter()
.cloned()
.find(|f| {
f.format == vk::Format::B8G8R8A8_SRGB
&& f.color_space == vk::ColorSpaceKHR::SRGB_NONLINEAR
})
.unwrap_or_else(|| formats[0])
}如果没有,那么我们可以评估可用格式的优劣,然后选择一个最好的。但在大多数情况下,随遇而安地使用第一个格式也行,所以我们用 unwrap_or_else 方法来简化代码。
呈现模式
呈现模式可以说是交换链中最重要的设置,因为它决定了图像什么时候被交换到屏幕上。Vulkan 中有四种可能的呈现模式:
vk::PresentModeKHR::IMMEDIATE– 应用程序提交的图像会立即传输到屏幕上,这可能会导致撕裂。vk::PresentModeKHR::FIFO– 交换链是一个队列,当显示器刷新时,显示器会从队列的前端取出一张图像,应用程序会在队列的后端插入渲染好的图像。如果队列已满,应用程序就必须等待。这种模式最类似于现代游戏中的垂直同步(vertical sync)。显示器刷新的时刻被称为“垂直空白”(vertical blank)。vk::PresentModeKHR::FIFO_RELAXED– 这种模式与FIFO的区别在于,如果程序提交图像的速度比显示器刷新的速度慢,那么图像就会立即传输,而不是等待下一个垂直空白。这可能会导致撕裂。vk::PresentModeKHR::MAILBOX– 这是FIFO模式的另一种变体。如果程序提交图像的速度比显示器刷新的速度快,当队列已满时,队列中的图像会直接被新的图像替换,而不会阻塞应用程序。这种模式可以用来尽可能快地渲染帧,同时避免撕裂,因而比标准的垂直同步有更少的延迟。这通常被称为“三重缓冲”,尽管仅靠三个缓冲本身并不能让帧率不受限制。
只有 vk::PresentModeKHR::FIFO 模式是保证可用的,因此我们需要写一个函数来查找可用的最佳模式:
fn get_swapchain_present_mode(
present_modes: &[vk::PresentModeKHR],
) -> vk::PresentModeKHR {
}我个人认为,如果能耗不是问题的话,vk::PresentModeKHR::MAILBOX 是一个非常好的折中方案。它既能避免撕裂,同时又能保持尽可能低的延迟,因为它会在垂直空白之前渲染尽可能新的图像。在移动设备上,能耗更重要,那时候你可能会想使用 vk::PresentModeKHR::FIFO。现在,让我们遍历 present_modes 列表,看看 vk::PresentModeKHR::MAILBOX 是否可用:
fn get_swapchain_present_mode(
present_modes: &[vk::PresentModeKHR],
) -> vk::PresentModeKHR {
present_modes
.iter()
.cloned()
.find(|m| *m == vk::PresentModeKHR::MAILBOX)
.unwrap_or(vk::PresentModeKHR::FIFO)
}交换范围
现在就剩交换范围一个属性了,我们再为它写一个函数:
fn get_swapchain_extent(
window: &Window,
capabilities: vk::SurfaceCapabilitiesKHR.
) -> vk::Extent2D {
}交换范围就是交换链中图像的分辨率,它几乎总是等于我们正在绘制的窗口的分辨率。可用的分辨率范围在 vk::SurfaceCapabilitiesKHR 结构体中定义。Vulkan 通过 current_extent 成员来告知适合我们窗口的交换范围。一些窗口系统会将 current_extent 的宽和高设置为一个特殊值 —— u32 类型的最大值 —— 来表示允许我们自己选择对于窗口最合适的交换范围,在这种情况下我们需要在 min_image_extent 和 max_image_extent 的范围内选择一个最合适的分辨率。
fn get_swapchain_extent(
window: &Window,
capabilities: vk::SurfaceCapabilitiesKHR,
) -> vk::Extent2D {
if capabilities.current_extent.width != u32::MAX {
capabilities.current_extent
} else {
vk::Extent2D::builder()
.width(window.inner_size().width.clamp(
capabilities.min_image_extent.width,
capabilities.max_image_extent.width,
))
.height(window.inner_size().height.clamp(
capabilities.min_image_extent.height,
capabilities.max_image_extent.height,
))
.build()
}
}我们使用 clamp 函数来限制窗口的实际大小在 Vulkan 设备支持的范围内。
创建交换链
现在我们有了所有用来帮助我们在运行时做出决策的辅助函数,我们终于有了创建工作交换链所需的所有信息。
创建一个 create_swapchain 函数,它首先调用这些辅助函数并取得其结果。然后,在 App::create 中创建逻辑设备之后调用这个函数:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
let device = create_logical_device(&instance, &mut data)?;
create_swapchain(window, &instance, &device, &mut data)?;
// ...
}
}
unsafe fn create_swapchain(
window: &Window,
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let indices = QueueFamilyIndices::get(instance, data, data.physical_device)?;
let support = SwapchainSupport::get(instance, data, data.physical_device)?;
let surface_format = get_swapchain_surface_format(&support.formats);
let present_mode = get_swapchain_present_mode(&support.present_modes);
let extent = get_swapchain_extent(window, support.capabilities);
Ok(())
}除去这些属性之外,我们还需要决定交换链中图像的数量。交换链有一个工作所需的最小图像数量:
let image_count = support.capabilities.min_image_count;然而,仅仅满足这个最小值意味着我们有时候必须等待驱动程序完成内部操作,然后才能获取另一张图像来渲染。因此,建议至少请求比最小值多一张图像:
let image_count = support.capabilities.min_image_count + 1;我们也要确保我们请求的图像数量不超过最大值,其中 0 是一个特殊值,表示没有最大值:
let mut image_count = support.capabilities.min_image_count + 1;
if support.capabilities.max_image_count != 0
&& image_count > support.capabilities.max_image_count
{
image_count = support.capabilities.max_image_count;
}接下来,我们需要说明如何处理在多个队列族中使用的交换链图像。如果图形队列族与呈现队列族不同,我们的应用程序就要在图形队列上绘制交换链中的图像,然后在呈现队列上提交它们。在这种情况下,我们需要指定如何处理在多个队列族中使用的交换链图像:
vk::SharingMode::EXCLUSIVE– 一张图像同时只能被一个队列族持有,在另一个队列中使用它之前,必须显式地转移其所有权。这种方式能提供最好的性能。vk::SharingMode::CONCURRENT– 一张图像可以在多个队列族中使用,而不需要显式地转移所有权。
如果图形队列族和呈现队列族不同,我们的教程中会使用 CONCURRENT 模式,这样我们就不需要讲解所有权,毕竟这里面涉及的一些东西最好以后再详细解释。你必须使用 queue_family_indices 构建器方法提前指定哪些队列族之间可以共享交换链图像的所有权。如果图形队列族和呈现队列族相同 —— 大多数硬件都是这样的 —— 那么我们应该使用 EXCLUSIVE 模式,因为 CONCURRENT 模式要求你至少指定两个不同的队列族。
let mut queue_family_indices = vec![];
let image_sharing_mode = if indices.graphics != indices.present {
queue_family_indices.push(indices.graphics);
queue_family_indices.push(indices.present);
vk::SharingMode::CONCURRENT
} else {
vk::SharingMode::EXCLUSIVE
};和其他的 Vulkan 对象一样,创建交换链对象也要填充一个巨大的结构体。又是熟悉的开始:
let info = vk::SwapchainCreateInfoKHR::builder()
.surface(data.surface)
// continued...在指定交换链所绑定的表面之后,我们需要指定交换链图像的细节:
.min_image_count(image_count)
.image_format(surface_format.format)
.image_color_space(surface_format.color_space)
.image_extent(extent)
.image_array_layers(1)
.image_usage(vk::ImageUsageFlags::COLOR_ATTACHMENT)image_array_layers 指定每张图像的层(layer)数。除非你在开发一个立体 3D 应用程序,否则这个值总是 1。image_usage 位掩码指定我们会对交换链中的图像进行何种操作。在本教程中,我们将直接在图像上绘制,这意味着它们被用作颜色附件(color attachment)。先将图像渲染到另一个图像上、再执行后处理等操作也是可以的。在这种情况下,你可以使用 vk::ImageUsageFlags::TRANSFER_DST 这样的值,然后使用内存操作将渲染好的图像传输到交换链图像上。
.image_sharing_mode(image_sharing_mode)
.queue_family_indices(&queue_family_indices)接着我们提供图像共享模式,以及允许共享交换链图像的队列族的索引。
.pre_transform(support.capabilities.current_transform)我们可以为交换链中的图像指定一个受支持的的变换操作(capabilities 的 supported_transforms 中记录了受支持的变换),例如 90 度顺时针旋转或水平翻转。如果你不想进行任何变换,只需指定当前变换 current_transform 即可。
.composite_alpha(vk::CompositeAlphaFlagsKHR::OPAQUE)composite_alpha 方法指定是否应该使用 alpha 通道与窗口系统中的其他窗口进行混合。你几乎总是希望忽略 alpha 通道,因此使用 vk::CompositeAlphaFlagsKHR::OPAQUE。
.present_mode(present_mode)
.clipped(true)present_mode 的含义不言而喻。clipped 被设置为 true 来表示我们不关心被遮挡像素 —— 例如被窗口系统中其他窗口遮挡 —— 的颜色。除非你真的需要能够读取这些像素并获得可预测的结果,否则启用裁剪可以获得最佳性能。
.old_swapchain(vk::SwapchainKHR::null());还有最后一个方法,old_swapchain。你的交换链可能在应用程序运行时变得无效,或者不再是最优的 —— 例如当窗口大小改变的时候。在这种情况下,交换链实际上需要从头开始重建,而旧的交换链的引用必须在这个方法中指定。这是一个复杂的主题,我们将在以后的章节中讨论。现在我们假设我们只会创建一个交换链。我们可以省略这个调用,因为底层的字段默认就是一个空句柄,但为了完整起见,我们还是把它留在这里。
现在,向 AppData 中添加一个 vk::SwapchainKHR 字段来保存交换链对象:
struct AppData {
// ...
swapchain: vk::SwapchainKHR,
}创建交换链就像调用 create_swapchain_khr 方法一样简单:
data.swapchain = device.create_swapchain_khr(&info, None)?;不出所料,参数是交换链的创建信息和可选的自定义分配器。没有什么意外的。创建出的交换链需要在 App::destroy 中,在设备被销毁前清理掉:
unsafe fn destroy(&mut self) {
self.device.destroy_swapchain_khr(self.data.swapchain, None);
// ...
}现在运行程序,确保交换链创建成功。如果你在调用 vkCreateSwapchainKHR 的时候遇到了访问冲突错误,或者看到类似 Failed to find 'vkGetInstanceProcAddress' in layer SteamOverlayVulkanLayer.dll 的消息,那么请参考常见问题中关于 Steam 覆盖层的条目。
现在,不妨试试在校验层启用的情况下,在构造 vk::SwapchainCreationInfoKHR 结构体时去掉 .image_extent(extent) 这一行。你会发现,其中一个校验层立即就捕获到了错误,并打印出了一些有用的信息,指出 image_extent 的值非法:
获取交换链图像
交换链已经创建出来了,现在我们还要获取交换链中的图像 vk::Image 的句柄。我们将在后面的章节中使用这些句柄来创建渲染目标。我们将在 AppData 中添加一个 swapchain_images 字段来保存这些句柄:
struct AppData {
// ...
swapchain_images: Vec<vk::Image>,
}这些图像会随着交换链被创建出来,并且当交换链被销毁时被自动清理掉,因此我们不需要添加任何清理代码。
将下面的代码添加到 create_swapchain 函数的最后面,紧跟着 create_swapchain_khr 的调用,来获取这些句柄:
data.swapchain_images = device.get_swapchain_images_khr(data.swapchain)?;还有一件事,我们需要保存交换链中图像的格式和交换范围,因为我们将在后面的章节中用到它们。在 AppData 中添加两个字段:
struct AppData {
// ...
swapchain_format: vk::Format,
swapchain_extent: vk::Extent2D,
swapchain: vk::SwapchainKHR,
swapchain_images: Vec<vk::Image>,
}然后在 create_swapchain 中保存它们:
data.swapchain_format = surface_format.format;
data.swapchain_extent = extent;现在,我们有了一组可以绘制并呈现到屏幕上的图像。我们将在下一章中开始讨论如何将图像设置为渲染目标,然后开始使用图形管线和绘制指令来绘制图像!
图像视图 (Image views)
原文链接:https://kylemayes.github.io/vulkanalia/presentation/image_views.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
要在渲染管线中使用任何 vk::Image —— 包括交换链中的那些,我们都需要为其创建一个图像视图对象 vk::ImageView。图像视图就像它的名字所描述的那样,它描述了如何访问图像,以及访问图像的哪一部分。例如,图像视图可以用来表示“一张图像应该被视为一张没有多级渐远层级(mipmapping levels)的二维纹理”。
在本章中,我们会实现一个 create_swapchain_image_views 函数,来为交换链中的每张图像创建一个基本的图像视图,这样我们就可以在之后的章节中将它们用作渲染目标。
首先,在 AppData 结构体中添加一个字段,用来存储图像视图:
struct AppData {
// ...
swapchain_image_views: Vec<vk::ImageView>,
}
创建一个 create_swapchain_image_views 函数,并在 App::create 中创建完交换链之后调用它:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_swapchain(window, &instance, &device, &mut data)?;
create_swapchain_image_views(&device, &mut data)?;
// ...
}
}
unsafe fn create_swapchain_image_views(
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}接着,我们实现 create_swapchain_image_views 函数,遍历交换链图像,并为每一张图像创建图像视图:
unsafe fn create_swapchain_image_views(
device: &Device,
data: &mut AppData,
) -> Result<()> {
data.swapchain_image_views = data
.swapchain_images
.iter()
.map(|i| {
})
.collect::<Result<Vec<_>, _>>()?;
Ok(())
}对于我们要创建的每一个图像视图,我们首先定义它的颜色分量映射。这允许你对颜色通道进行重新排序。例如,你可以将所有通道映射到红色通道,从而创建一个单色纹理。你也可以将常量值 0 和 1 映射到通道上。在我们的例子中,我们将使用默认的映射:
let components = vk::ComponentMapping::builder()
.r(vk::ComponentSwizzle::IDENTITY)
.g(vk::ComponentSwizzle::IDENTITY)
.b(vk::ComponentSwizzle::IDENTITY)
.a(vk::ComponentSwizzle::IDENTITY);接着,我们为图像视图定义子资源(subresource)范围,它描述了图像的用途以及应该访问图像的哪一部分。这里,我们的图像将被用作没有多级渐远层级,也没有多个层次的颜色目标:
let subresource_range = vk::ImageSubresourceRange::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.base_mip_level(0)
.level_count(1)
.base_array_layer(0)
.layer_count(1);如果你在编写一个立体 3D 应用,那么你可以创建一个包含多个层次的交换链图像视图。然后你可以访问不同的层次,并分别为左眼和右眼的视角创建各自的图像视图。
现在,我们创建一个 vk::ImageViewCreateInfo 结构体来提供创建图像视图所需的参数:
let info = vk::ImageViewCreateInfo::builder()
.image(*i)
.view_type(vk::ImageViewType::_2D)
.format(data.swapchain_format)
.components(components)
.subresource_range(subresource_range);view_type 和 format 字段指定图像数据应该如何被解释。view_type 字段用于指定图像应该被视为一维纹理、二维纹理、三维纹理还是立方体贴图。
接下来就只要调用 create_image_view 函数了:
device.create_image_view(&info, None)不同于交换链中的图像,图像视图是由我们显式创建的,所以我们需要在 App::destroy 中添加一个类似的循环来销毁它们:
unsafe fn destroy(&mut self) {
self.data.swapchain_image_views
.iter()
.for_each(|v| self.device.destroy_image_view(*v, None));
// ...
}图像视图已经足以让我们把图像作为纹理使用了,但它还不能用作渲染目标。这还需要一个额外的间接步骤 —— 帧缓冲(framebuffer)。但在这之前我们需要先建立图形管线。
介绍
原文链接:https://kylemayes.github.io/vulkanalia/pipeline/introduction.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在接下来的几章中,我们会搭建图形管线。它会被用来画我们的第一个三角形。图形管线是一系列将我们提交的顶点与网格纹理转换为渲染目标中的像素点的操作。下面是一个简化版的流程图:

输入装配器(input assembler)从指定缓冲中收集原始顶点数据,并且也可以使用顶点缓冲来重复使用某些元素,而不需要复制那些元素。
顶点着色器(vertex shader)对每个顶点执行,将变换应用于顶点,例如将其顶点位置从模型空间转换至屏幕空间,然后将每个顶点的数据传输至图形管线的下一阶段。
曲面细分着色器(tessellation shader)使你能够根据特定规则细分几何图形,以提升网格(mesh)的质量。这通常用于使砖墙和楼梯之类的表面从附近看上去更粗糙。
几何着色器(geometry shader)以图元(primitive,例如三角形、线、点)为单位处理几何图形。它可以剔除图元或输出更多图元。这与曲面细分着色器类似,但更灵活。然而如今的程序很少使用几何着色器,因为它在 Intel 集成显卡之外的大部分显卡上性能不佳。
光栅化(rasterization)阶段将图元离散化(discretize)为片元(fragment)。片元用来在帧缓冲上填充像素。任何在屏幕外的片元会被丢弃,顶点着色器输出的属性会在片元之间进行插值,如上图所示。在经过深度测试(depth test)后,位于其它图元后面的片元也会被舍弃。
片元着色器(fragment shader)对每一个违背丢弃的片元执行。它会判断哪些片元要写入哪一些帧缓冲,并计算它们的颜色与深度值。它可以使用顶点着色器返回的插值后的数据,例如纹理坐标以及顶点的法线等。
混色(color blending)阶段会把在帧缓冲中同一个像素位置的不同片元进行混合。片元可以简单地覆盖彼此,也可以叠加或根据透明度混合。
标为绿色的阶段被称为固定功能(fixed-function)阶段。这些阶段所执行的工作是预定义的,但你可以通过参数对处理过程进行一定程度的配置。
标为橙色的阶段是可编程的(programmable)。你可以将自己的代码上传至显卡,并使它执行想要的操作。例如,你可以使用片元着色器来实现纹理、光照,甚至是光追。这些程序会在显卡的多个核心中同时执行来并行处理多个对象,例如顶点与片元。
如果你用过更早的 API,例如 OpenGL 和 Direct3D,你可能会对 glBlendFunc 或 OMSetBlendState 之类用于修改管线设置的函数比较熟悉。而 Vulkan 的图形管线几乎是完全不可变的,所以如果你想对渲染器进行修改,绑定其它帧缓冲,或是修改混合函数,那你必须重新创建整个管线。这么做的劣势在于你需要创建多个管线来满足你渲染所需的所有不同状态的组合。但是因为你在管线上所做的所有操作都已经事先可知,驱动就可以更好地优化你的管线。
根据需求不同,一些可编程阶段是可选的。比如,如果你只是想画简单的几何图形,那么密铺和几何着色器阶段是可以被禁用的。如果你只关心深度值,那你可以禁用片元着色器阶段。这在阴影贴图的生成上很有用。
在下一章中,我们会先创建显示三角形所必须的两个可编程阶段:顶点着色器与片元着色器。混合模式、视口、光栅化之类的固定功能的配置会在下一章中介绍。最后我们配置 Vulkan 渲染管线的最后一部分 —— 指定输入与输出的帧缓冲。
我们先创建一个 create_pipeline 函数,并且在 App::create 中调用 create_swapchain_image_views 后立刻调用新创建的 create_pipeline 函数。我们会在之后几章中修改并实现这个函数。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_swapchain_image_views(&device, &mut data)?;
create_pipeline(&device, &mut data)?;
// ...
}
}
unsafe fn create_pipeline(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}着色器模块
原文链接:https://kylemayes.github.io/vulkanalia/pipeline/shader_modules.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs | shader.vert | shader.frag
不同于以往的 API,Vulkan 中的着色器代码不是以 GLSL 或者 HLSL 这种形式指定的,而是以一种被称为 SPIR-V 的字节码格式指定的。Vulkan 和 OpenCL(都是 Knronos 的 API)都使用这种字节码格式。这种格式既可以用于图形着色器,也可以用于计算着色器,不过本书中我们会关注其中与图形管线有关的部分。
字节码格式的优势在于,GPU 厂商编写的将着色器代码转换为本地代码的编译器可以简单得多。过去的经验表明,如果使用 GLSL 这种人类可读的语法,一些 GPU 厂商对标准的解释是相当灵活的。如果你恰好使用了这些厂商的 GPU,编写了一些非平凡(non-trivial)的着色器,那么你的代码可能会因为语法错误而被其他厂商的驱动程序拒绝,或者可能更糟,由于编译器的 bug,你的着色器可能会以不同的方式运行。使用 SPIR-V 这种直接的字节码格式,这种情况有望得到避免。
不过,我们也不用手写字节码。Khronos 发行了他们的制造商无关的编译器,能够将 GLSL 编译为 SPIR-V 格式。该编译器能验证着色器代码符合标准,并生成 SPIR-V 二进制供你的程序使用。你也可以将这个编译期作为库引入你的程序,这样就能在运行时编译着色器代码了,不过在本教程中我们不这么做。
尽管我们可以直接通过 glslangValidator.exe 使用这个编译器,本教程中我们会使用由 Google 开发的 glslc.exe。glslc 的优势在于它与 GCC 和 Clang 这样的广为人知的编译器使用相同的命令行参数格式,并且支持一些额外的功能,例如 #include。这两个编译器都包含在 Vulkan SDK 中,所以你不需要额外下载任何东西。
GLSL 是一种使用类 C 语法的着色器语言。使用 GLSL 编写的程序包含了一个 main 函数,这一函数完成具体的运算操作。GLSL 使用全局变量进行输入输出,而不是使用参数和返回值。GLSL 语言本身包含了许多用于图形编程的特性,例如内建的向量和矩阵类型,用于叉乘和矩阵乘法的函数,以及用于计算反射向量的函数。
在 GLSL 中,向量类型使用 vec 加上一个表示向量元素的数字来命名。例如,一个三维空间中的位置可以用 vec 存储。可以通过 .x 这样的字段访问向量的单个分量,也可以通过一次性指定多个分量来创建一个新的向量。例如,表达式 vec3(1.0, 2.0, 3.0).xy 的结果是 vec2。向量的构造函数可以接受向量对象和标量值的组合。例如,可以使用 vec3(vec2(1.0, 2.0), 3.0) 来构造一个 vec3。
如我们在之前的章节中所提到的,要绘制一个三角形,我们需要编写一个顶点着色器和一个片元着色器。接下来的两节中我们会分别介绍这两个着色器的 GLSL 代码,之后我们会展示如何生成两个 SPIR-V 二进制文件,并将它们加载到程序中。
顶点着色器
顶点着色器处理每个传入的顶点。它以顶点的属性 —— 例如世界坐标、颜色、法线和纹理坐标 —— 作为输入,输出最终的裁剪坐标(clip coordinates)和需要传递给片元着色器的属性,例如颜色和纹理坐标。这些值将由光栅化器(rasterizer)在片元上进行插值,从而产生平滑的渐变。
裁剪坐标是一个顶点着色器输出的四维向量,它的四个分量会被除以第四个分量,从而产生一个标准化设备坐标(normalized device coordinate)。这些归一化设备坐标是 齐次坐标(homogeneous coordinates),它将帧缓冲映射到一个 [-1, 1] × [-1, 1] 的坐标系中,如下图所示:

如果你之前涉足过计算机图形学,你应该不会对这些东西感到陌生。而如果你曾使用过 OpenGL,那么你会注意到这里的 Y 轴和 OpenGL 是相反的,而 Z 轴则使用和 Direct3D 相同的范围,即从 0 到 1。
对于我们的第一个三角形,我们不会应用任何变换,而是直接指定三个顶点的标准化设备坐标,从而创建如下图所示的形状:

我们可以直接从顶点着色器输出标准化设备坐标 —— 只需要通过裁剪坐标将它们从顶点着色器输出,并将最后一个分量设置为 1,这样,将裁剪坐标转换为标准化设备坐标的除法就不会改变任何东西。
通常情况下,这些坐标应该存储在顶点缓冲(vertex buffer)中,但在 Vulkan 中创建并填充顶点缓冲并不是什么轻松的事。为了尽快让我们看到三角形,我们暂时将这些坐标直接包含在顶点着色器中。代码如下:
#version 450
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
}
main 函数会对每个顶点执行一次。GLSL 内建的 gl_VertexIndex 中存储了当前顶点的索引,这一索引通常是用来引用顶点缓冲中顶点数据的,不过这里我们用它来索引一个硬编码的顶点数据数组。每个顶点的位置从着色器中的常量数组中获取,并与 z 和 w 分量组合,从而产生一个裁剪坐标。最后,我们将顶点的位置通过 gl_Position 内建变量输出。
片元着色器
由顶点着色器输出的顶点位置组成的三角形将会填充屏幕上一定范围内片元。片元着色器会对每个片元运行,输出帧缓冲上对应位置的颜色和深度。一个简单的将整个三角形填充为红色的片元着色器如下所示:
#version 450
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(1.0, 0.0, 0.0, 1.0);
}
类似于顶点着色器的 main 函数,片元着色器的 main 函数会对每个片元执行一次。GLSL 中的颜色是一个四维向量,四个分量分别对应 R、G、B 和 alpha 四个通道,每个分量的取值范围都是 [0, 1]。不同于顶点着色器中的 gl_Position,片元着色器中没有用于输出颜色的内建变量。你必须为每个帧缓冲指定一个输出变量,并用layout 指定帧缓冲的索引。这里,我们将红色写入到 outColor 变量中,这一变量与索引为 0 的帧缓冲(也是唯一的帧缓冲)绑定。
逐顶点着色
整个三角形都是红色,一点都不好玩。你不觉得下面这样看起来更有趣吗?

我们修改一下两个着色器来实现这个效果。首先,我们为每个顶点指定各自的颜色。在顶点着色器中加入这样一个颜色数组:
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
接着,我们将这些顶点的颜色传递给片元着色器,片元着色器就能将插值后的颜色输出到帧缓冲。在顶点着色器中添加一个颜色输出变量,并在 main 函数中写入它:
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}
接着,我们在片元着色器中加入一个对应的输入变量:
layout(location = 0) in vec3 fragColor;
void main() {
outColor = vec4(fragColor, 1.0);
}
这个输入变量不一定要和顶点着色器中的输出变量使用相同的颜色,因为它们会根据 location 指令指定的索引被链接到一起。main 函数现在它会输出从 fragColor 读取的颜色和 alpha 值。如上图所示,fragColor 的值会自动在三个顶点之间进行插值,从而产生平滑的渐变。
编译着色器
在你工程的根目录里创建一个名为 shader 的文件夹(与 src 文件夹相邻),并将顶点着色器保存到 shader.vert 文件中,将片元着色器保存到 shader.frag 文件中。GLSL 着色器没有官方的文件扩展名,但是 .vert 和 .frag 这两个扩展名比较常用。
shader.vert 的内容如下:
#version 450
layout(location = 0) out vec3 fragColor;
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}
而 shader.frag 的内容如下:
#version 450
layout(location = 0) in vec3 fragColor;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragColor, 1.0);
}
接下来,我们使用 glslc 程序将这些着色器编译为 SPIR-V 字节码。
Windows
创建一个包含以下命令的 compile.bat 文件:
C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.vert -o vert.spv
C:/VulkanSDK/x.x.x.x/Bin32/glslc.exe shader.frag -o frag.spv
pause
把 glslc.exe 的路径替换为你安装 Vulkan SDK 的路径,双击这个文件来运行它。
Linux
创建一个包含以下命令的 compile.sh 文件:
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.vert -o vert.spv
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.frag -o frag.spv
将 glslc 的路径替换为你安装 Vulkan SDK 的路径。使用 chmod +x compile.sh 命令将这个脚本变得可执行,然后运行它。
MacOS
创建一个包含以下命令的 compile.sh 文件:
/User/user/VulkanSDK/x.x.x.x/macOS/bin/glslc shaders/shader.vert -o vert.spv
/User/user/VulkanSDK/x.x.x.x/macOS/bin/glslc shaders/shader.frag -o frag.spv
这两条命令告诉编译器从 GLSL 源文件中读取代码,并输出一个 SPIR-V 字节码文件。
如果你的着色器代码中有语法问题,编译器会告诉你问题所在。你可以试着故意遗漏一个逗号然后重新运行编译脚本。
你也可以在不带任何参数的情况下运行编译器,这样就能看到它支持的命令行参数。例如,它可以输出人类可读的字节码,这样你就能看到你的着色器在做什么,以及编译器对它做了哪些优化。
用命令行编译着色器是比较直观的方式,本教程中我们会一直沿用这种方式,不过你也可以在你的应用程序中直接编译着色器。Vulkan SDK 包含了 libshaderc,它是一个库,你的程序可以用它在运行时直接将 GLSL 代码编译为 SPIR-V 字节码。
加载着色器
现在我们有了创建 SPIR-V 着色器的方式,是时候把它们引入我们的程序中,并插入渲染管线了。我们会使用 Rust 标准库中的 include_bytes! 宏来将编译后的 SPIR-V 字节码包含进我们的程序中:
unsafe fn create_pipeline(device: &Device, data: &mut AppData) -> Result<()> {
let vert = include_bytes!("../shaders/vert.spv");
let frag = include_bytes!("../shaders/frag.spv");
Ok(())
}创建着色器模块
我们需要将着色器代码包装在一个 vk::ShaderModule 对象中才能将其传递给管线。让我们创建一个辅助函数 create_shader_module 来完成这一工作:
unsafe fn create_shader_module(
device: &Device,
bytecode: &[u8],
) -> Result<vk::ShaderModule> {
}这个函数接受一个包含字节码的切片作为参数,并使用我们的逻辑设备,用字节码创建一个 vk::ShaderModule 对象。
创建着色器模块很简单,只要指定字节码切片的长度和字节码切片本身就行。这些信息被包含在 vk::ShaderModuleCreateInfo 结构体中。唯一的问题是,字节码的长度是以字节为单位指定的,但是这个结构体中的字节码切片是 &[u32] 而不是 &[u8]。因此,我们需要先将 &[u8] 转换为 &[u32]。
vulkanalia 提供了一个名为 Bytecode 的辅助结构体,我们将会用这个辅助结构体来将着色器代码复制到一个具有 u32 对齐的缓冲中。首先导入这个辅助结构体:
use vulkanalia::bytecode::Bytecode;然后回到我们的 create_shader_module 函数,Bytecode::new 函数会在提供的字节切片长度不是 4 的整数倍,或者分配对齐的缓冲失败时返回错误。这里我们提供的字节码应该总是正确的,所以我们直接对结果调用 unwrap。
let bytecode = Bytecode::new(bytecode).unwrap();接着我们创建 vk::ShaderModuleCreateInfo 并用它调用 create_shader_module 来创建着色器模块:
let info = vk::ShaderModuleCreateInfo::builder()
.code_size(bytecode.code_size())
.code(bytecode.code());
Ok(device.create_shader_module(&info, None)?)这里的参数还是跟之前的对象创建函数一样:创建信息结构体和可选的自定义分配器。
着色器模块只是对我们从文件加载的着色器字节码的轻度封装。在图形管线创建的时候,这些 SPIR-V 字节码才会被编译链接为可以执行的机器码。也就是说,我们可以在渲染管线之后马上销毁着色器模块,这就使得我们可以把着色器模块写成 create_pipeline 函数中的局部变量,而不用放到 AppData 结构体中:
unsafe fn create_pipeline(device: &Device, data: &mut AppData) -> Result<()> {
let vert = include_bytes!("../shaders/vert.spv");
let frag = include_bytes!("../shaders/frag.spv");
let vert_shader_module = create_shader_module(device, &vert[..])?;
let frag_shader_module = create_shader_module(device, &frag[..])?;
// ...清理工作应该放在函数的最后,我们在这里添加两个对 destroy_shader_module 的调用。本章剩下的代码都会插入到这两行代码之前。
// ...
device.destroy_shader_module(vert_shader_module, None);
device.destroy_shader_module(frag_shader_module, None);
Ok(())
}创建着色器阶段(shader stages)
要使用这些着色器,我们要在创建管线的时候通过 vk::PipelineShaderStageCreationInfo 将它们分配给特定的管线阶段。
我们从顶点着色器开始,在 create_pipeline 函数中添加以下代码:
let vert_stage = vk::PipelineShaderStageCreateInfo::builder()
.stage(vk::ShaderStageFlags::VERTEX)
.module(vert_shader_module)
.name(b"main\0");第一步告诉 Vulkan 着色器将会在哪个管线阶段使用。每个可编程阶段都有一个对应的枚举变体。
接下来的两个字段指定了包含代码的着色器模块,以及要执行的函数,也就是入口点。这意味着你可以将多个片元着色器组合到一个着色器模块中,并使用不同的入口点来区分它们的行为。在这里我们仍然使用标准的 main。
还有一个可选的成员 specialization_info,这里我们不会用到它,但是值得讨论一下。它允许你为着色器常量指定值。你可以使用单个着色器模块,在管线创建的时候通过为其中的常量指定不同的值来配置它的行为。这比在渲染时使用变量来配置着色器更高效,因为编译器可以做一些优化,例如消除依赖于这些值的 if 语句。如果你没有这样的常量,那么你可以像我们这里一样跳过设置它。
仿照着再写一段用于片元着色器的代码就很简单了:
let frag_stage = vk::PipelineShaderStageCreateInfo::builder()
.stage(vk::ShaderStageFlags::FRAGMENT)
.module(frag_shader_module)
.name(b"main\0");这就是描述管线的可编程阶段的全部内容。在下一章中,我们会配置管线的固定功能阶段。
固定功能
原文链接:https://kylemayes.github.io/vulkanalia/pipeline/fixed_functions.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
旧的图形学 API 在渲染管线中为大部分阶段提供了默认状态。而在 Vulkan 中,你必须显式指定一切 —— 从视口大小到颜色混合函数。在本章中,我们会创建并填充配置这些固定功能操作所需的所有结构体。
顶点输入
vk::PipelineVertexInputStateCreationInfo 结构体大致上通过两种方式描述顶点数据的格式:
- 绑定(Bindings) – 数据之间的间隔,以及数据是逐顶点(per-vertex)还是逐个实例(per-instance)的(参见实例化)
- 属性描述(Attribute descriptions) – 顶点着色器接收的属性的类型,从哪个绑定中加载数据,以及从哪个偏移量开始加载
因为我们已经在顶点着色器中硬编码了数据,我们会将这个结构体的所有字段都保留默认值,表明我们不需要加载数据。我们会在顶点缓冲章节重新审视这个结构体。在 create_pipeline 函数中 vk::PipelineShaderStageCreateInfo 的后面添加以内容:
unsafe fn create_pipeline(device: &Device, data: &mut AppData) -> Result<()> {
// ...
let vertex_input_state = vk::PipelineVertexInputStateCreateInfo::builder();输入装配
vk::PipelineInputAssemblyStateCreateInfo 结构体指定了两件事:从顶点中绘制什么样的几何图形,以及是否启用了图元重启(primitive restart)。前者由 topology 字段指定,可以有以下值:
vk::PrimitiveTopology::POINT_LIST– 根据输入顶点绘制点vk::PrimitiveTopology::LINE_LIST– 每两个顶点绘制一条线,不重复使用顶点vk::PrimitiveTopology::LINE_STRIP– 每两个顶点绘制一条线,每条线的终点是下一条线的起点vk::PrimitiveTopology::TRIANGLE_LIST– 每三个顶点绘制一个三角形,不重复使用顶点vk::PrimitiveTopology::TRIANGLE_STRIP– 每三个顶点绘制一个三角形,每个三角形的第二个和第三个顶点是下一个三角形的第一和第二个顶点
通常情况下,我们从顶点缓冲中加载的顶点都是按索引顺序排列的,但你也可以使用*元素缓冲(element buffer)*自行指定索引顺序。这就允许你进行一些优化,例如复用顶点。
如果你将 primitive_restart_enable 字段设置为 true,那么你就可以使用特殊的索引 0xFFFF 或 0xFFFFFFFF 来打断 _STRIP 拓扑模式下的线和三角形。
我们的目的是绘制三角形,所以我们按照以下方式填充结构体:
let input_assembly_state = vk::PipelineInputAssemblyStateCreateInfo::builder()
.topology(vk::PrimitiveTopology::TRIANGLE_LIST)
.primitive_restart_enable(false);视口和裁剪
视口用于描述渲染结果将被输出到的帧缓冲域。视口几乎总是从 (0, 0) 到 (width, height),在本教程中也是如此。
let viewport = vk::Viewport::builder()
.x(0.0)
.y(0.0)
.width(data.swapchain_extent.width as f32)
.height(data.swapchain_extent.height as f32)
.min_depth(0.0)
.max_depth(1.0);交换链的尺寸和交换链图像的尺寸并不总是相同。因为我们之后是要将交换链图像用作帧缓冲,所以我们应该使用图像的尺寸。
min_depth 和 max_depth 值指定了帧缓冲的深度值范围。这些值必须在 [0.0, 1.0] 范围内,但 min_depth 可以比 max_depth 更大。如果你没在整什么骚活,那么你应该使用标准值 0.0 和 1.0。
视口定义了图像到帧缓冲的映射关系,而裁剪矩形(scissor rectangles)则定义了哪些像素会被实际地存储到帧缓冲中。与其说是变换,裁剪矩形更像是一个过滤器。下图展示了视口和裁剪矩形的区别。注意左边的裁剪矩形只是产生这张图像的可能性之一,只要它比视口大就行。

在本教程中,我们只想填充整个帧缓冲域,所以我们会指定一个覆盖整个帧缓冲域的裁剪矩形:
let scissor = vk::Rect2D::builder()
.offset(vk::Offset2D { x: 0, y: 0 })
.extent(data.swapchain_extent);视口和裁剪矩形的信息需要用 vk::PipelineViewportStateCreateInfo 结构体来组合在一起。在某些显卡上,你可以使用多个视口和裁剪矩形,所以这个结构体的成员是一个数组。使用多个视口需要启用一个 GPU 特性(参见逻辑设备创建)。
let viewports = &[viewport];
let scissors = &[scissor];
let viewport_state = vk::PipelineViewportStateCreateInfo::builder()
.viewports(viewports)
.scissors(scissors);光栅化
光栅化程序将来自顶点着色器的顶点构成的几何图元交给片元着色器。它也负责进行深度测试、背面剔除(face culling)和剪裁测试(scissor test),并且可以配置为输出填充整个多边形的片元还是只输出多边形的边缘(线框渲染)。所有这些都可以通过 vk::PipelineRasterizationStateCreateInfo 结构体来配置。
let rasterization_state = vk::PipelineRasterizationStateCreateInfo::builder()
.depth_clamp_enable(false)
// continued...如果 depth_clamp_enable 被设为 true,在近平面和远平面以外的片元都会被截断到这两个平面上,而不是被丢弃。这在一些特殊情况下很有用,例如生成阴影贴图的时候。使用这个选项需要启用一个 GPU 特性。
.rasterizer_discard_enable(false)如果 rasterizer_discard_enable 被设为 true,那么几何图元就永远不会通过光栅化程序阶段。这基本上就禁用了对帧缓冲的任何输出。
.polygon_mode(vk::PolygonMode::FILL)polygon_mode 字段决定了几何图元如何生成片元:
vk::PolygonMode::FILL– 用片元填充多边形的区域vk::PolygonMode::LINE– 用线段绘制多边形的边缘vk::PolygonMode::POINT– 用点绘制多边形的顶点
使用填充以外的模式都需要启用一个 GPU 特性。
.line_width(1.0)line_width 成员非常直白,它以图元为单位指定线条的宽度。支持的最大线宽取决于硬件,任何比 1.0 更宽的线条都需要启用一个 GPU 特性。
.cull_mode(vk::CullModeFlags::BACK)
.front_face(vk::FrontFace::CLOCKWISE)cull_mode 变量决定了使用哪种面剔除。你可以禁用剔除、剔除正面、剔除背面或同时剔除正面和背面。front_face 变量用于指定正面的顶点顺序,可以是顺时针或逆时针。
.depth_bias_enable(false);光栅化器可以通过添加一个常量值或者根据片元的斜率来改变深度值。这有时用于阴影贴图,但我们不会用到它。只需将 depth_bias_enable 设为 false 即可。
多重采样(multisampling)
vk::PipelineMultisampleStateCreateInfo 结构体用于配置多重采样 —— 一种抗锯齿的方式。它通过组合多个光栅化后的多边形的片元着色器结果来工作。这主要发生在边缘,也是锯齿伪影最明显的地方。因为如果只有一个多边形映射到一个像素,那么它就不需要运行多次片元着色器,所以它比简单地渲染到更高分辨率然后缩小要便宜得多。启用它需要启用一个 GPU 特性。
let multisample_state = vk::PipelineMultisampleStateCreateInfo::builder()
.sample_shading_enable(false)
.rasterization_samples(vk::SampleCountFlags::_1);我们会在后面的章节再讨论多重采样,现在我们先将它禁用。
深度测试和模板测试(stencil testing)
如果需要进行深度测试和模板测试,那么除了需要配置深度缓冲和模板缓冲之外,你还需要通过 vk::PipelineDepthStencilStateCreateInfo 结构体配置管线。我们现在还不需要这些,所以我们可以忽略它们。我们会在深度缓冲章节再讨论它们。
颜色混合
片元着色器返回的颜色需要与帧缓冲中已有的颜色进行混合。混合的方式有两种:
- 混合新值和旧值以产生最终颜色
- 使用位运算组合新值和旧值
有两种结构体可以用于配置颜色混合。vk::PipelineColorBlendAttachmentState 可以对每个帧缓冲进行单独的颜色配置,而 vk::PipelineColorBlendStateCreateInfo 则可以进行全局的颜色混合配置。我们的例子里只有一个帧缓冲:
let attachment = vk::PipelineColorBlendAttachmentState::builder()
.color_write_mask(vk::ColorComponentFlags::all())
.blend_enable(false)
.src_color_blend_factor(vk::BlendFactor::ONE) // 可选
.dst_color_blend_factor(vk::BlendFactor::ZERO) // 可选
.color_blend_op(vk::BlendOp::ADD) // 可选
.src_alpha_blend_factor(vk::BlendFactor::ONE) // 可选
.dst_alpha_blend_factor(vk::BlendFactor::ZERO) // 可选
.alpha_blend_op(vk::BlendOp::ADD); // 可选我们通过上面这个结构体为帧缓冲配置第一类颜色混合方式,这种方式的运算过程类似于下面的代码:
if blend_enable {
final_color.rgb = (src_color_blend_factor * new_color.rgb)
<color_blend_op> (dst_color_blend_factor * old_color.rgb);
final_color.a = (src_alpha_blend_factor * new_color.a)
<alpha_blend_op> (dst_alpha_blend_factor * old_color.a);
} else {
final_color = new_color;
}
final_color = final_color & color_write_mask;如果 blend_enable 被设为 false,那么片元着色器返回的新颜色会原封不动地传递到帧缓冲中。否则,这两种混合运算(color_blend_op 和 alpha_blend_op)会被执行,计算出一个新的颜色。最终的颜色会与 color_write_mask 进行位运算,以决定哪些通道会被实际地传递到帧缓冲中。
通常,我们使用颜色混合是为了进行阿尔法合成(alpha blending),基于透明度混合新旧颜色。这种情况下,final_color 的计算过程如下:
final_color.rgb = new_alpha * new_color + (1 - new_alpha) * old_color;
final_color.a = new_alpha.a;
这可以通过以下参数实现:
let attachment = vk::PipelineColorBlendAttachmentState::builder()
.color_write_mask(vk::ColorComponentFlags::all())
.blend_enable(true)
.src_color_blend_factor(vk::BlendFactor::SRC_ALPHA)
.dst_color_blend_factor(vk::BlendFactor::ONE_MINUS_SRC_ALPHA)
.color_blend_op(vk::BlendOp::ADD)
.src_alpha_blend_factor(vk::BlendFactor::ONE)
.dst_alpha_blend_factor(vk::BlendFactor::ZERO)
.alpha_blend_op(vk::BlendOp::ADD);你可以在 Vulkan 规范里 vk::BlendFactor 和 vk::BlendOp 枚举的文档(或者 vulkanalia 的文档)中找到所有可能的运算。
第二种结构体(vk::PipelineColorBlendStateCreateInfo)引用了所有帧缓冲,并且允许你设置混合常量,你可以在混合运算中使用这些常量。
let attachments = &[attachment];
let color_blend_state = vk::PipelineColorBlendStateCreateInfo::builder()
.logic_op_enable(false)
.logic_op(vk::LogicOp::COPY)
.attachments(attachments)
.blend_constants([0.0, 0.0, 0.0, 0.0]);如果你想使用第二种混合方式(位运算结合),你应该把 logic_op_enable 设为 true。位运算操作可由 logic_op 字段指定。注意这会自动禁用第一种混合方式,就好像你把所有帧缓冲的 blend_enable 都置为了 false!color_write_mask 在这种模式下也会被用到,以决定哪些通道会被实际地传递到帧缓冲中。你也可以同时禁用这两种模式,就像我们这里做的一样,这样片元颜色就会原封不动地传递到帧缓冲中。
动态状态(只是示例,不要添加到代码里)
有一部分状态是可以在不重新创建管线的情况下改变的。例如视口的大小、线宽和混合常量。如果你想这么做,那么你需要填充一个 vk::PipelineDynamicStateCreateInfo 结构体:
let dynamic_states = &[
vk::DynamicState::VIEWPORT,
vk::DynamicState::LINE_WIDTH,
];
let dynamic_state = vk::PipelineDynamicStateCreateInfo::builder()
.dynamic_states(dynamic_states);这会使得这些值(视口和线宽)的设置被忽略,你需要在绘制时指定这些值。我们会在后面的章节再讨论这个结构体。如果你没有任何动态状态,那么你可以忽略这个结构体。
管线布局
你可以在着色器中使用 uniform 值,它们类似于动态状态变量,可以在不重新创建着色器的前提下,在绘制时改变着色器的行为。它们通常用于将变换矩阵或是纹理采样器传递给顶点着色器。尽管我们在本章中不会使用它们,但我们仍然需要在管线创建时指定一个空的管线布局。
在 AppData 中添加一个 pipeline_layout 字段,因为我们会在别的函数中用到它:
struct AppData {
// ...
pipeline_layout: vk::PipelineLayout,
}然后在 create_pipeline 函数中,在调用 destroy_shader_module 之前创建这个对象:
+unsafe fn create_pipeline(device: &Device, data: &mut AppData) -> Result<()> {
// ...
let layout_info = vk::PipelineLayoutCreateInfo::builder();
data.pipeline_layout = device.create_pipeline_layout(&layout_info, None)?;
device.destroy_shader_module(vert_shader_module, None);
device.destroy_shader_module(frag_shader_module, None);
Ok(())
}这个结构体也用于指定推式常量 —— 另一种给着色器传递动态值的方式,我们会在后面的章节中介绍。
管线布局会在整个程序的生存期中被引用,所以它应该在 App::destroy 中被销毁:
unsafe fn destroy(&mut self) {
self.device.destroy_pipeline_layout(self.data.pipeline_layout, None);
// ...
}结论
这就是所有的固定功能状态!从零开始配置这些状态是一项很大的工作,但好处是我们现在几乎完全了解了图形管线中发生的一切!这降低了因为某些组件的默认状态与你期望的不同,而导致意外行为的可能性。
我们还要创建一样东西来完成图形管线,那就是渲染流程(render pass)。
渲染流程
原文链接:https://kylemayes.github.io/vulkanalia/pipeline/render_passes.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码 main.rs
在创建渲染管线之前,我们还需要设置渲染过程中将会使用的帧缓冲附件(framebuffer attachments)。我们需要指定有多少个颜色缓冲和深度缓冲,每个缓冲使用多少样本数,以及渲染操作将如何处理缓冲中的内容。所有这些信息都会被装进一个渲染流程对象中。我们将会创建一个新的函数 create_render_pass,并在 App::create 中 create_pipeline 之前调用它:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_render_pass(&instance, &device, &mut data)?;
create_pipeline(&device, &mut data)?;
// ...
}
}
unsafe fn create_render_pass(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}附件描述
在我们的场景中,我们只需要一个颜色附件。我们会在 create_render_pass 函数中创建一个 vk::AttachmentDescription 来表示它:
let color_attachment = vk::AttachmentDescription::builder()
.format(data.swapchain_format)
.samples(vk::SampleCountFlags::_1)
// continued...颜色附件的 format 字段需要与交换链图像的格式匹配。我们现在不会进行多重采样,所以我们只用 1 个样本。
.load_op(vk::AttachmentLoadOp::CLEAR)
.store_op(vk::AttachmentStoreOp::STORE)load_op 和 store_op 决定在渲染之前和之后对附件中的数据做什么。对于 load_op 我们有以下三种选择:
vk::AttachmentLoadOp::LOAD– 保留附件中已有的内容vk::AttachmentLoadOp::CLEAR– 在渲染开始前将附件清空,为每个像素设置一个常量值vk::AttachmentLoadOp::DONT_CARE– 附件中已有的内容是未定义的,我们不关心它们
在我们的场景下,我们希望在渲染新帧之前将帧缓冲清空为黑色。而 store_op 只有两种选择:
vk::AttachmentStoreOp::STORE– 渲染的内容将会被存储起来,以便之后读取vk::AttachmentStoreOp::DONT_CARE– 渲染结束后帧缓冲中的内容是未定义的
我们希望在屏幕上看到渲染出来的三角形,所以我们选择 STORE。
.stencil_load_op(vk::AttachmentLoadOp::DONT_CARE)
.stencil_store_op(vk::AttachmentStoreOp::DONT_CARE)load_op 和 store_op 对颜色和深度数据生效,而 stencil_load_op 和 stencil_store_op 对模板数据生效。我们的应用不会使用模板缓冲,所以加载和存储的结果并不重要。
.initial_layout(vk::ImageLayout::UNDEFINED)
.final_layout(vk::ImageLayout::PRESENT_SRC_KHR);在 Vulkan 中,纹理和帧缓冲是以具有特定像素格式的 vk::Image 对象来表示的。不过你可以根据你在对图像做的事情改变内存中像素的布局。
一些常见的布局包括:
vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL– 图像会被用作颜色附件vk::ImageLayout::PRESENT_SRC_KHR– 图像被用在交换链中进行呈现操作vk::ImageLayout::TRANSFER_DST_OPTIMAL– 图像用作赋值操作的目标
我们会在纹理章节中对这一主题进行更深入的探讨,不过现在我们只要知道图像需要先被转换到特定的布局,以便进行下一步的操作。
initial_layout 指定图像在渲染流程开始前所具有的布局,而 final_layout 指定图像在渲染流程结束后将会自动转换到的布局。我们将 initial_layout 设置为 vk::ImageLaout::UNDEFINED,表明我们不关心图像输入时的布局。这也意味着图像中的内容不一定会被保留,但没关系,反正我们也打算清空它了。而在渲染之后,我们希望图像可以被在交换链上呈现,所以我们将 final_layout 设置为 vk::ImageLayout::PRESENT_SRC_KHR。
子流程与附件引用
一个渲染流程可以由多个子流程组成。子流程是一系列的渲染操作,每个渲染操作都依赖于之前的子流程处理后帧缓冲中的内容。例如,许多后处理(post-processing)效果就是前面的处理结果上叠加一系列操作来实现的。如果你将这些渲染操作组合成一个渲染流程,Vulkan 就可以对这些操作进行重新排序,以便更好地利用内存带宽来提高性能。不过在我们的第一个三角形程序中,我们只需要一个子流程。
每个子流程都要引用一个或多个附件,这些附件通过 vk::AttachmentReference 结构体指定:
let color_attachment_ref = vk::AttachmentReference::builder()
.attachment(0)
.layout(vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL);attachment 参数通过附件描述符数组的索引指定要引用哪个附件。我们的附件描述数组中只有一个 vk::AttachmentDescription,所以我们将索引置为 0。layout 用于指定子流程开始时附件的布局,Vulkan 会在子流程开始时自动将附件转换到这个布局。我们打算将附件用作颜色缓冲,所以 vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL 布局会给我们最好的性能,正如它的名字所说的那样。
子流程使用 vk::SubpassDescription 结构体来描述:
let color_attachments = &[color_attachment_ref];
let subpass = vk::SubpassDescription::builder()
.pipeline_bind_point(vk::PipelineBindPoint::GRAPHICS)
.color_attachments(color_attachments);Vulkan 在将来也可能支持计算子流程,所以我们需要明确指定这是一个图形子流程。然后我们指定对颜色附件的引用。
这里设置的颜色附着将会被片元着色器使用,对应我们在片元着色器中的 layout(location = 0) out vec4 outColor 指令。
以下类型的附件也可以被子流程使用:
input_attachments– 可以被着色器读取的附件resolve_attachments– 用于多重采样颜色附件的附件depth_stencil_attachment– 用于深度和模板数据的附件preserve_attachments– 子流程不会使用的附件,但其中的数据必须被保留
渲染流程
现在,我们已经设置好了附件和与之关联的子流程,我们可以开始创建渲染流程了。在 AppData 中 pipeline_layout 字段的上面添加一个成员变量来存储 vk::RenderPass 对象:
struct AppData {
// ...
render_pass: vk::RenderPass,
pipeline_layout: vk::PipelineLayout,
}接着,我们就可以用附件和子流程数组填充 vk::RenderPassCreateInfo 结构体,来创建渲染渲染对象了:
let attachments = &[color_attachment];
let subpasses = &[subpass];
let info = vk::RenderPassCreateInfo::builder()
.attachments(attachments)
.subpasses(subpasses);
data.render_pass = device.create_render_pass(&info, None)?;和管线布局一样,渲染流程会在整个程序中被使用,所以我们只在 App::destroy 中清理它:
Just like the pipeline layout, the render pass will be referenced throughout the program, so it should only be cleaned up at the end in App::destroy:
unsafe fn destroy(&mut self) {
self.device.destroy_pipeline_layout(self.data.pipeline_layout, None);
self.device.destroy_render_pass(self.data.render_pass, None);
// ...
}到此为止我们已经做了很多工作,在下一章中,我们会将这些工作整合起来,最终创建出图形管线对象!
总结
原文链接:https://kylemayes.github.io/vulkanalia/pipeline/conclusion.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
现在我们可以开始组合前几章中创建的所有结构和对象来创建图形管线了!回顾一下我们现在有的对象:
- 着色器阶段 – 着色器单元定义的图形管线中的可编程阶段
- 固定功能状态 – 管线中所有定义固定功能阶段的结构,例如输入组装、光栅化器、视口和颜色混合
- 管线布局 – 定义着色器引用的可以在绘制时更新的
uniform值和推送常量 - 渲染流程 – 管线阶段中引用的附件,以及它们的用途
这些对象定义了图形管线的方方面面。现在我们可以在 create_pipeline 函数的末尾(但要在着色器模块销毁之前)开始填充 vk::GraphicsPipelineCreateInfo 了。
let stages = &[vert_stage, frag_stage];
let info = vk::GraphicsPipelineCreateInfo::builder()
.stages(stages)
// continued...我们首先提供一个 vk::PipelineShaderStageCreateInfo 结构体的数组。
.vertex_input_state(&vertex_input_state)
.input_assembly_state(&input_assembly_state)
.viewport_state(&viewport_state)
.rasterization_state(&rasterization_state)
.multisample_state(&multisample_state)
.color_blend_state(&color_blend_state)接着我们引用所有描述固定功能阶段的结构体。
.layout(data.pipeline_layout)然后是管线布局。
.render_pass(data.render_pass)
.subpass(0);最后引用之前创建的渲染流程,以及图形管线将要使用的子流程在子流程数组中的索引。在这个渲染管线上使用其他的渲染流程也是可以的,但这些渲染流程之间必须相互兼容。这里给出了关于兼容性的描述,不过本教程中我们不会使用这个特性。
.base_pipeline_handle(vk::Pipeline::null()) // 可选.
.base_pipeline_index(-1) // 可选.实际上还有两个参数:base_pipeline_handle 和 base_pipeline_index。Vulkan 允许你派生一个现有的图形管线来创建新的图形管线。管线派生的意义在于,如果新的管线和旧的管线有很多相似之处,这样做就能减少很多开销;在同一个亲代(parent)派生出的图形管线之间切换也更快。你可以使用 base_pipeline_handle 通过句柄来指定一个现有的管线,或者使用 base_pipeline_index 通过索引来指定一个即将创建的管线。现在我们只有一个管线,所以我们会简单地指定一个空句柄和一个无效索引。只有在 vk::GraphicsPipelineCreateInfo 的 flags 字段中也指定了 vk::PipelineCreateFlags::DERIVATIVE 标志时,这些值才会被使用。
现在,在 AppData 中添加一个字段来存储 vk::Pipeline 对象:
struct AppData {
// ...
pipeline: vk::Pipeline,
}然后在 App::create 中创建图形管线:
data.pipeline = device.create_graphics_pipelines(
vk::PipelineCache::null(), &[info], None)?.0[0];create_graphics_pipelines 函数的参数比 Vulkan 中通常的对象创建函数要多。它被设计为可以一次性接受多个 vk::GraphicsPipelineCreateInfo 对象并创建多个 vk::Pipeline 对象。
第一个参数是一个对 vk::PipelineCache 的引用,这个参数是可选的,我们为其传递 vk::PipelineCache::null()。管线缓存可以用来在多次调用 create_graphics_pipelines 时存储和重用管线创建相关的数据,甚至可以在程序执行结束后从文件中读取缓存。这样可以显著提高管线创建的速度。
图形管线会在所有的绘制操作中使用,所以它也应该在 App::destroy 中被销毁:
unsafe fn destroy(&mut self) {
self.device.destroy_pipeline(self.data.pipeline, None);
// ...
}现在运行程序,来确定我们一直以来的努力并非全部白费。现在,我们离看到屏幕上有东西出现不远了。在接下来的几章中,我们将设置交换链图像的实际帧缓冲,并准备绘制指令。
帧缓冲
原文链接:https://kylemayes.github.io/vulkanalia/drawing/framebuffers.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
我们在之前的几个章节中多次提到过帧缓冲。而现在我们已经建立了渲染流程,就差一个跟交换链图片格式相同的帧缓冲了。
在创建渲染流程时指定的附件需要被包装进帧缓冲对象 vk::Framebuffer 中进行绑定。一个帧缓冲对象引用了所有代表附件的 vk::ImageView 对象。在我们的例子中,我们只有一个颜色附件。但这并不意味着我们就只需要使用一张图像,因为我们需要为交换链中的每个图像都创建对应的帧缓冲,并在渲染时使用与从交换链取得的图像对应的帧缓冲。
为此,我们在 AppData 中创建另一个 Vec 字段来存放帧缓冲:
struct AppData {
// ...
framebuffers: Vec<vk::Framebuffer>,
}我们创建一个新的函数 create_framebuffers ,在 App::create 里创建完管线之后调用它。之后我们将会在这个函数里创建 vk::Framebuffer 对象并将它们存储在 framebuffers 数组中:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_pipeline(&device, &mut data)?;
create_framebuffers(&device, &mut data)?;
// ...
}
}
unsafe fn create_framebuffers(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}create_framebuffers 函数将遍历交换链中所有图像视图,为每个图像视图创建一个帧缓冲:
unsafe fn create_framebuffers(device: &Device, data: &mut AppData) -> Result<()> {
data.framebuffers = data
.swapchain_image_views
.iter()
.map(|i| {
let attachments = &[*i];
let create_info = vk::FramebufferCreateInfo::builder()
.render_pass(data.render_pass)
.attachments(attachments)
.width(data.swapchain_extent.width)
.height(data.swapchain_extent.height)
.layers(1);
device.create_framebuffer(&create_info, None)
})
.collect::<Result<Vec<_>, _>>()?;
Ok(())
}如你所见,创建帧缓冲的方式相当直白。首先我们需要指定帧缓冲要与哪个 render_pass 兼容。你只能在与一个帧缓冲兼容的渲染流程上使用它,这基本上就意味着渲染流程和帧缓冲有着相同数量和类型的附件。
attachments 字段指定了应绑定到渲染流程的 attachment 数组所对应的附件描述的 vk::ImageView 对象。
width 和 height 没什么好说的,就是宽度和高度,layers 则指的是图像的层数。我们交换链中的图像都是单个图像,所以层数为1。
我们应该在帧缓冲所基于的图像视图和渲染流程被销毁之前清理它:
unsafe fn destroy(&mut self) {
self.data.framebuffers
.iter()
.for_each(|f| self.device.destroy_framebuffer(*f, None));
// ...
}现在我们到达了一个里程碑,我们拥有了渲染所需的所有对象。在下一章中,我们将编写第一批实际的绘制指令。
指令缓冲(Command buffers)
原文链接:https://kylemayes.github.io/vulkanalia/drawing/command_buffers.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
Vulkan 中的指令 —— 例如绘制操作和内存传输操作 —— 并不是通过直接调用函数来执行的。你需要把你想执行的操作记录在指令缓冲对象中。这样做的优势在于绘制指令可以提前配置好,并且可以在多个线程中配置指令。在配置完指令缓冲之后,你只要在主循环中告诉 Vulkan 执行这些指令就可以了。
指令池(Command pools)
在创建指令缓冲之前,我们需要先创建一个指令池。指令池管理着用于存储指令缓冲的内存,我们将从指令池中分配指令缓冲。在 AppData 中添加一个新的字段 vk::CommandPool 来存储指令池:
struct AppData {
// ...
command_pool: vk::CommandPool,
}接着创建一个新的函数 create_command_pool 并在 App::create 中创建完帧缓冲后调用它:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_framebuffers(&device, &mut data)?;
create_command_pool(&instance, &device, &mut data)?;
// ...
}
}
unsafe fn create_command_pool(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}创建指令池只需要两个参数:
let indices = QueueFamilyIndices::get(instance, data, data.physical_device)?;
let info = vk::CommandPoolCreateInfo::builder()
.flags(vk::CommandPoolCreateFlags::empty()) // 可选
.queue_family_index(indices.graphics);指令缓冲是通过提交到一个设备队列 —— 例如图形队列或呈现队列 —— 来执行的。每个指令池分配的指令缓冲只能提交到一种队列。这里我们要记录用于绘制的指令,所以我们选择图形队列族。
指令池可以有三个标志:
vk::CommandPoolCreateFlags::TRANSIENT– 提示指令缓冲会经常被重新记录(可能会改变内存分配行为)vk::CommandPoolCreateFlags::RESET_COMMAND_BUFFER– 允许单独重新记录指令缓冲,如果没有这个标志,所有指令缓冲都必须一起重置vk::CommandPoolCreateFlags::PROTECTED– 创建“受保护”的指令缓冲,它们存储在“受保护”内存中,Vulkan 会阻止对该内存未授权的访问
我们只在程序开始的时候记录指令缓冲,然后在主循环中重复执行它们,并且我们也不需要使用 DRM 来保护我们的三角形,所以我们不使用任何标志。
data.command_pool = device.create_command_pool(&info, None)?;从指令池分配的指令缓冲会在整个程序中被使用,所以缓冲池应该在程序结束时销毁:
unsafe fn destroy(&mut self) {
self.device.destroy_command_pool(self.data.command_pool, None);
// ...
}分配指令缓冲
现在我们可以开始分配指令缓冲,并在其中记录绘制指令了。因为某个绘制指令涉及到绑定正确的 vk::Framebuffer,所以我们实际上要为交换链中的每张图像都记录一个指令缓冲。为此,我们在 AppData 中创建一个 vk::CommandBuffer 对象的列表。指令缓冲会在它们所属的指令池被销毁时自动释放,所以我们不需要进行显式的清理。
struct AppData {
// ...
command_buffers: Vec<vk::CommandBuffer>,
}接下来我们开始实现用于分配并记录指令缓冲的 create_command_buffers 函数。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_command_pool(&instance, &device, &mut data)?;
create_command_buffers(&device, &mut data)?;
// ...
}
}
unsafe fn create_command_buffers(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}指令缓冲由 allocate_command_buffers 函数分配,它接受一个 vk::CommandBufferAllocateInfo 结构体作为参数,这个结构体指定了指令池和要分配的指令缓冲的数量:
let allocate_info = vk::CommandBufferAllocateInfo::builder()
.command_pool(data.command_pool)
.level(vk::CommandBufferLevel::PRIMARY)
.command_buffer_count(data.framebuffers.len() as u32);
data.command_buffers = device.allocate_command_buffers(&allocate_info)?;level 参数指定了分配的指令缓冲是主指令缓冲还是次级指令缓冲。
vk::CommandBufferLevel::PRIMARY– 可以提交到队列执行,但不能从其他指令缓冲中调用vk::CommandBufferLevel::SECONDARY– 不能直接提交,但可以从主指令缓冲中调用
这里我们用不到次级指令缓冲,不过不过你能想到,次级指令缓冲对于复用主指令缓冲中的常用操作很有帮助。
开始记录指令缓冲
我们调用 begin_command_buffer 函数来开始记录指令缓冲,它接受一个 vk::CommandBufferBeginInfo 结构体作为参数,这个结构体指定一些有关指令缓冲使用方式的细节。
for (i, command_buffer) in data.command_buffers.iter().enumerate() {
let inheritance = vk::CommandBufferInheritanceInfo::builder();
let info = vk::CommandBufferBeginInfo::builder()
.flags(vk::CommandBufferUsageFlags::empty()) // 可选
.inheritance_info(&inheritance); // 可选
device.begin_command_buffer(*command_buffer, &info)?;
}flag 参数指定了我们将要如何使用这个指令缓冲,它可以有以下取值:
vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT– 指令缓冲会在执行一次之后重新记录vk::CommandBufferUsageFlags::RENDER_PASS_CONTINUE– 这是一个次级指令缓冲,它会完全在一个渲染流程中执行vk::CommandBufferUsageFlags::SIMULTANEOUS_USE– 指令缓冲可以在它还在等待执行的时候被重新提交
目前我们还不需要这些标志。
inheritance_info 参数只用于次级指令缓冲,它指定了要从调用它的主指令缓冲中继承哪些状态。
如果指令缓冲已经被记录过一次,调用 begin_command_buffer 会隐式地重置它。一旦记录完成,就不能再向指令缓冲中追加指令了。
开始渲染流程
在我们开始渲染流程之前,我们需要先构建一些参数。
let render_area = vk::Rect2D::builder()
.offset(vk::Offset2D::default())
.extent(data.swapchain_extent);这里我们定义了渲染区域的大小。渲染区域定义了在渲染流程执行期间着色器会在哪里加载和存储像素。渲染区域之外的像素的值是未定义的。渲染区域应该和附件的大小匹配以获得最佳性能。
let color_clear_value = vk::ClearValue {
color: vk::ClearColorValue {
float32: [0.0, 0.0, 0.0, 1.0],
},
};接着我们定义一个清除值,它会被用来在渲染流程开始时清空帧缓冲(因为我们在创建渲染流程的时候指定了 vk::AttachmentLoadOp::CLEAR)。vk::ClearValue 是一个联合体(union),它可以用来设置颜色附件的清除值,也可以用来设置深度/模板附件的清除值。这里我们设置了 vk::ClearColorValue 类型的 color 字段,用来将清除颜色设为不透明的黑色。
绘制以 cmd_begin_render_pass 启动渲染流程开始,渲染流程由 vk::RenderPassBeginInfo 结构体来配置:
let clear_values = &[color_clear_value];
let info = vk::RenderPassBeginInfo::builder()
.render_pass(data.render_pass)
.framebuffer(data.framebuffers[i])
.render_area(render_area)
.clear_values(clear_values);首先我们提供渲染流程和将要绑定的附件。之前,我们为交换链中的每个图像都创建了一个帧缓冲,用作颜色附件。然后我们提供刚才创建的渲染区域和清除值。
device.cmd_begin_render_pass(
*command_buffer, &info, vk::SubpassContents::INLINE);现在渲染流程可以开始了。所有记录指令的函数都以 cmd_ 前缀开头。它们都返回 (),所以所以我们在完成记录之前都不需要进行错误处理。
每个记录指令的函数的第一个参数都是用来记录指令的指令缓冲。第二个参数指定刚才提供的的渲染流程的细节。最后一个参数控制渲染流程中的绘制指令是如何提供的。它可以有以下两个值:
vk::SubpassContents::INLINE– 渲染流程中的指令会被嵌入到主指令缓冲中,不会执行任何次级指令缓冲vk::SubpassContents::SECONDARY_COMMAND_BUFFERS– 渲染流程中的指令会被从次级指令缓冲中执行
我们不会使用次级指令缓冲,所以我们选择第一个选项。
基本绘制指令
现在我们可以绑定图形管线:
device.cmd_bind_pipeline(
*command_buffer, vk::PipelineBindPoint::GRAPHICS, data.pipeline);第二个参数指定了管线对象是图形管线还是计算管线。至此,我们已经告诉 Vulkan 在图形管线中执行哪些操作,以及在片元着色器中使用哪个附件,剩下的就是告诉它绘制三角形:
device.cmd_draw(*command_buffer, 3, 1, 0, 0);这个实际的绘制函数有点虎头蛇尾。我们之前提供了那么多信息,实际的绘制函数却如此简单。除了指令缓冲之外,它还有以下参数:
vertex_count– 尽管我们没有顶点缓冲,技术上来说,我们是要绘制 3 个顶点。instance_count– 用于实例化渲染,如果你没在进行实例化渲染,就把它设为1。first_vertex– 顶点缓冲的偏移量,定义了gl_VertexIndex的最小值。first_instance– 实例化渲染的偏移量,定义了gl_InstanceIndex的最小值。
完成
最后,我们调用 cmd_end_render_pass 函数结束渲染流程:
device.cmd_end_render_pass(*command_buffer);并调用 end_command_buffer 结束记录指令缓冲:
device.end_command_buffer(*command_buffer)?;在下一章中,我们将编写主循环的代码,它将从交换链中获取图像,执行正确的指令缓冲,并将完成的图像返回给交换链。
渲染与呈现
原文链接:https://kylemayes.github.io/vulkanalia/drawing/rendering_and_presentation.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在本章中我们会把所有东西组合起来。我们将实现 App::render 函数,该函数会由主循环调用,将三角形渲染到屏幕上。
同步
App::render 函数会进行以下操作:
- 从交换链获取一张图像
- 使用该图像作为帧缓冲的附件,执行指令缓冲
- 将该图像返还到交换链,以供呈现
每个操作都是通过单个函数调用来启动的,但它们会异步地(asynchronously)执行。函数调用会在操作实际完成之前返回,且操作之间的执行顺序也是不确定的。然而很不幸的是,我们的每一步操作实际上都依赖于前一步操作的完成。
有两种方法可以用于同步交换链事件:信号量(semaphores)和栅栏(fences)。它们都是可以用于协调操作的对象,这是通过让一个操作发出信号、另一个操作等待信号量或栅栏的状态从未发出信号(unsignaled)变为已发出信号(signaled)来实现的。
区别在于,栅栏的状态可以通过 wait_for_fences 等函数从程序中访问,而信号量则不行。栅栏主要用于同步应用程序本身与渲染操作,而信号量则用于同步指令队列内或跨队列的操作。我们希望同步绘制指令和呈现操作,因此信号量是最佳选择。
信号量
我们需要两个信号量,一个用于传递图像已被获取并可以用于渲染的信号,另一个用于传递渲染已完成并可以进行呈现的信号。在 AppData 中创建两个字段来存储这些信号量对象:
struct AppData {
// ...
image_available_semaphore: vk::Semaphore,
render_finished_semaphore: vk::Semaphore,
}添加一个 create_sync_objects 函数来创建信号量:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_command_buffers(&device, &mut data)?;
create_sync_objects(&device, &mut data)?;
// ...
}
}
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}创建信号量需要填充 vk::SemaphoreCreateInfo 结构体,不过在当前版本的 API 中它并没有任何必填字段。
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
let semaphore_info = vk::SemaphoreCreateInfo::builder();
Ok(())
}未来的 Vulkan API 或者扩展可能会为 flags 和 p_next 参数添加功能,就像它为其他结构体所做的那样。信号量的创建也是熟悉的模式:
data.image_available_semaphore = device.create_semaphore(&semaphore_info, None)?;
data.render_finished_semaphore = device.create_semaphore(&semaphore_info, None)?;信号量应该在程序结束时清理,这时候所有指令都已经完成,用不着再进行同步了:
unsafe fn destroy(&mut self) {
self.device.destroy_semaphore(self.data.render_finished_semaphore, None);
self.device.destroy_semaphore(self.data.image_available_semaphore, None);
// ...
}从交换链获取图像
正如我们之前所提到的,在 App::render 函数中要做的第一件事就是从交换链取得一张图像。回想一下,交换链是一个扩展特性,所以我们要用的函数带有 _khr 后缀。
unsafe fn render(&mut self, window: &Window) -> Result<()> {
let image_index = self
.device
.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphore,
vk::Fence::null(),
)?
.0 as usize;
Ok(())
}acquire_next_image_khr 的第一个参数是我们将要从中获取图像的交换链。第二个参数指定了一个以纳秒为单位的超时时间,使用 64 位无符号整数的最大值可以禁用超时。
下一个参数指定了在呈现引擎使用完图像后要发出信号的同步对象,可以是信号量或者栅栏,也可以两者都指定。我们将在这里使用 image_available_semaphore,它发出信号的时刻就是我们可以开始绘制的时候。
这个函数返回将会被获取的交换链图像的索引。这个索引指向 swapchain_images 数组中的 vk::Image。我们将使用这个索引来选择正确的指令缓冲。
提交指令缓冲
队列的提交和同步是通过 vk::SubmitInfo 结构体来配置的:
let wait_semaphores = &[self.data.image_available_semaphore];
let wait_stages = &[vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT];
let command_buffers = &[self.data.command_buffers[image_index as usize]];
let signal_semaphores = &[self.data.render_finished_semaphore];
let submit_info = vk::SubmitInfo::builder()
.wait_semaphores(wait_semaphores)
.wait_dst_stage_mask(wait_stages)
.command_buffers(command_buffers)
.signal_semaphores(signal_semaphores);前两个参数 wait_semaphores 和 wait_dst_stage_mask 指定在指令缓冲执行前要等待的信号量,以及在管线的哪个阶段等待。我们希望在图像可用之前不要写入颜色,因此我们指定了写入颜色附件的管线阶段。这意味着理论上来说实现可以进行若干优化,例如可以在图像还不可用的时候就开始执行我们的顶点着色器。wait_stages 数组中的每个条目都对应于 wait_semaphores 中相同索引的信号量。
下一个参数,command_buffers,指定了要提交执行的指令缓冲。正如之前提到的,我们应该提交绑定了我们刚获取的交换链图像的指令缓冲。
最后一个参数 signal_semaphores 指定了在指令缓冲执行完毕后要发出信号的信号量。在我们的例子中,我们使用 render_finished_semaphore。
self.device.queue_submit(
self.data.graphics_queue, &[submit_info], vk::Fence::null())?;现在我们可以用 queue_submit 来将指令缓冲提交到图形队列了。这个函数接受一个 vk::SubmitInfo 结构体的数组作为参数,这样做是为了在工作量很大的时候提高效率。最后一个参数引用了一个可选的栅栏,当指令缓冲执行完毕时会发出信号。我们已经在用信号量来进行同步了,因此我们只传递一个 vk::Fence::null()。
子流程依赖
还记得渲染流程中自动进行图像布局转换的子流程吗?这些转换是由子流程依赖(subpass dependencies)控制的,它们指定了子流程之间的内存和执行依赖关系。我们现在只有一个子流程,但是在这个子流程之前和之后的操作也被视为隐式的“子流程”。
有两个内建的子流程依赖能在渲染流程开始前和结束后进行布局转换,但前者进行转换的时机并不正确 —— 它假设转换发生在管线开始的时候,但在那个时候我们还没有获取到图像!有两种方法可以解决这个问题。我们可以将 image_available_semaphore 的 wait_stages 改为 vk::PipelineStageFlags::TOP_OF_PIPE,以确保图像可用之前渲染流程不会开始。或者,我们可以让渲染流程等待 vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT 阶段。我决定在这里使用第二种方法,因为这是个了解子流程依赖的工作原理的好机会。
子流程依赖是由 vk::SubpassDependency 结构体来指定的。在 create_render_pass 函数中添加一个:
let dependency = vk::SubpassDependency::builder()
.src_subpass(vk::SUBPASS_EXTERNAL)
.dst_subpass(0)
// continued...前两个字段 src_subpass 和 dst_subpass 指定了依赖和被依赖的子流程的索引。特殊值 vk::SUBPASS_EXTERNAL 指的是隐式子流程,它位于渲染流程开始前或结束后,具体的语义取决于它是在 src_subpass 还是 dst_subpass 中指定的。索引 0 指的是我们的子流程,也是唯一的子流程。dst_subpass 必须始终大于 src_subpass,以防止依赖图中出现循环(除非其中一个子流程是 vk::SUBPASS_EXTERNAL)。
.src_stage_mask(vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT)
.src_access_mask(vk::AccessFlags::empty())接下来的两个字段 src_stage_mask 和 src_access_mask 指定了要等待的操作,以及这些操作会在哪个阶段发生。我们需要等待交换链完成对图像的读取,然后才能访问它。这可以通过等待颜色附件输出阶段本身来实现。
.dst_stage_mask(vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT)
.dst_access_mask(vk::AccessFlags::COLOR_ATTACHMENT_WRITE);最后两个字段 dst_stage_mask 和 dst_access_mask 指定了哪些操作会等待这个子流程依赖,以及这些操作会在哪个阶段发生。上面的设置会阻止转换发生,直到我们真正需要(且允许)它发生的时候:当我们想要开始向图像写入颜色的时候。
let attachments = &[color_attachment];
let subpasses = &[subpass];
let dependencies = &[dependency];
let info = vk::RenderPassCreateInfo::builder()
.attachments(attachments)
.subpasses(subpasses)
.dependencies(dependencies);最后在 vk::RenderPassCreateInfo 的 dependencies 字段中指定这个依赖。
呈现
绘制一帧的最后异步就是将结果提交回交换链,让它最终显示在屏幕上。我们在 App::render 函数末尾添加一个 vk::PresentInfoKHR 结构体来配置呈现:
let swapchains = &[self.data.swapchain];
let image_indices = &[image_index as u32];
let present_info = vk::PresentInfoKHR::builder()
.wait_semaphores(signal_semaphores)
.swapchains(swapchains)
.image_indices(image_indices);第一个参数指定了在呈现之前要等待的信号量,就像 vk::SubmitInfo 一样。
接下来的两个参数指定了要呈现图像的交换链,以及交换链的图像索引。这里几乎总是只有一张交换链图像。
还有一个可选的 result 参数,可以指定一个 vk::Result 数组,用于检查每个交换链的呈现是否成功。如果你只使用单个交换链,那么这个参数是不必要的,因为你可以直接使用呈现函数的返回值。
self.device.queue_present_khr(self.data.present_queue, &present_info)?;queue_present_khr 函数提交了一个请求,要求将图像呈现到交换链中。我们将在下一章修改 acquire_next_image_khr 和 queue_present_khr 的错误处理,因为它们的失败并不一定意味着应该终止程序,这与我们迄今为止所见到的函数不同。
如果你之前的工作都没有问题,那么现在你应该可以看到类似下面这样的东西:
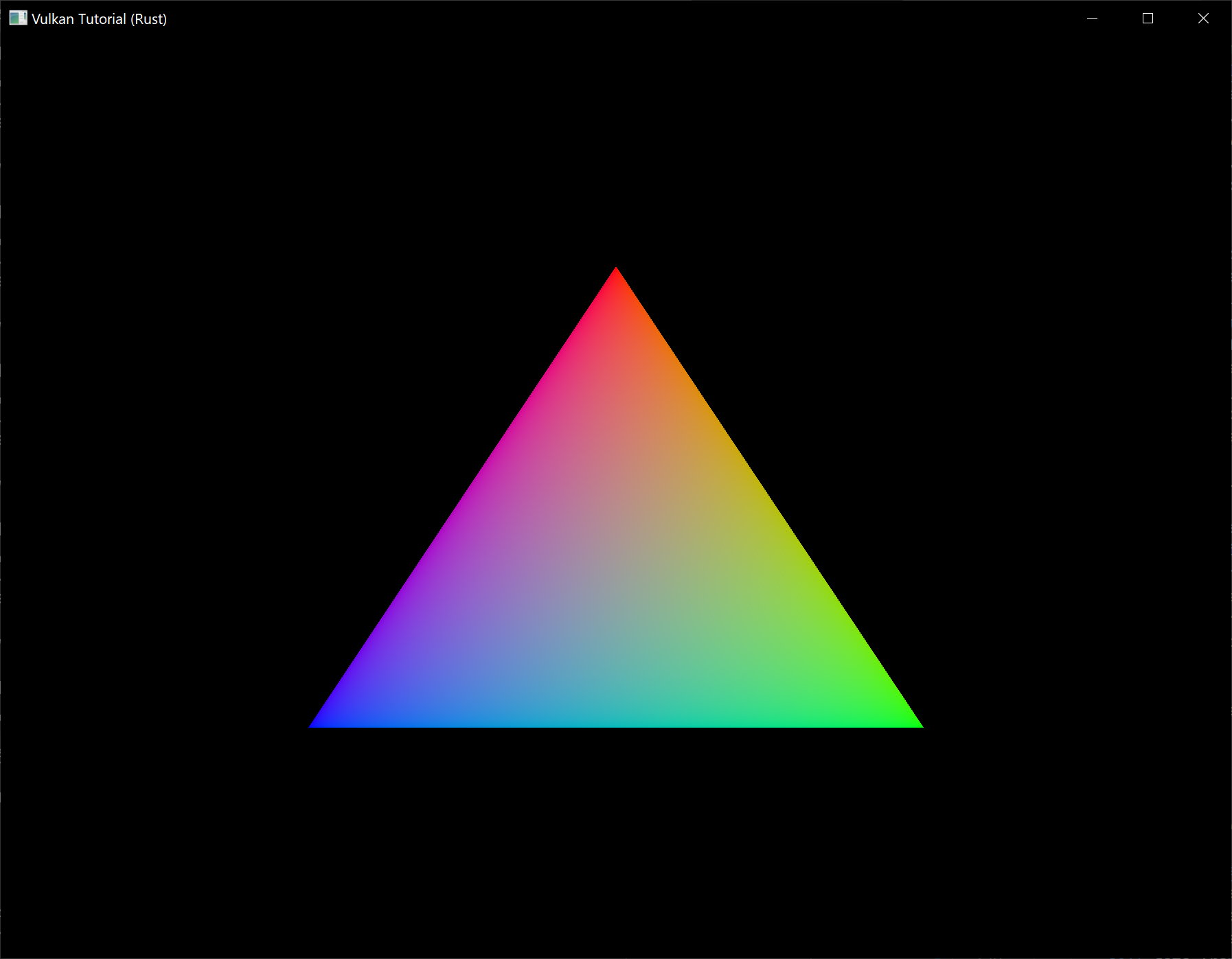
这个彩色三角形看上去可能和你在其他图形学教程中看到过的略有不同。这是因为本教程让着色器在线性颜色空间中进行插值,然后再转换到 sRGB 颜色空间。参见这篇博客来了解这两种颜色空间的区别。
好耶!然而不幸的是,当启用校验层时,程序在你关闭它的时候会崩溃。从 debug_callback 打印到终端的消息告诉了我们原因:

还记得吗?我们说过 App::render 中的所有操作都是异步的。也就是说,当我们在 main 函数中的循环退出之前调用 App::destroy 的时候,绘制和呈现操作可能仍在进行。在这种情况下清理资源可不是个好主意。
要修复这一问题,我们应该在 App::destroy 中调用 device_wait_idle 来等待逻辑设备完成操作:
Event::WindowEvent { event: WindowEvent::CloseRequested, .. } => {
destroying = true;
*control_flow = ControlFlow::Exit;
unsafe { app.device.device_wait_idle().unwrap(); }
unsafe { app.destroy(); }
}你也可以用 queue_wait_idle 来等待某个特定指令队列中的操作完成。这些函数可以用作一种非常简单的同步方式。你会发现当你关闭窗口时程序不再崩溃(不过如果你启用了校验层的话,你会看到一些与同步相关的错误)。
多帧并行渲染
如果你启用校验层并运行应用程序,你会看到一些错误信息,或者观察到内存使用量在缓慢增长。这是因为应用程序在 App::render 函数中快速提交了大量工作,但实际上并没有等待它们完成。如果 CPU 提交工作的速度比 GPU 处理工作的速度快,那么队列就会慢慢地被工作填满。更糟糕的是,我们同时还在重复使用 image_available_semaphore 和 render_finished_semaphore 信号量,以及指令缓冲。
最简单的解决方式就是在提交之后等待工作完成,例如使用 queue_wait_idle(注意:不要真的这么做):
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.device.queue_present_khr(self.data.present_queue, &present_info)?;
self.device.queue_wait_idle(self.data.present_queue)?;
Ok(())
}但这并不是使用 GPU 的最佳方式,因为如果这么做的话,整个图形管线只能同时渲染一帧了。然而当前帧已经完成的阶段是空闲的,可以用来渲染下一帧。我们现在将扩展我们的应用程序,允许多帧同时进行,同时限制积压的工作量。
首先在程序顶部添加一个常量,用于定义可以并行处理多少帧:
const MAX_FRAMES_IN_FLIGHT: usize = 2;每一帧都应该有自己的信号量,存储在 AppData 中:
struct AppData {
// ...
image_available_semaphores: Vec<vk::Semaphore>,
render_finished_semaphores: Vec<vk::Semaphore>,
}然后修改 create_sync_objects 函数,创建这些信号量:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
let semaphore_info = vk::SemaphoreCreateInfo::builder();
for _ in 0..MAX_FRAMES_IN_FLIGHT {
data.image_available_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
data.render_finished_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
}
Ok(())
}类似地,这些信号量也应该被清理:
unsafe fn destroy(&mut self) {
self.data.render_finished_semaphores
.iter()
.for_each(|s| self.device.destroy_semaphore(*s, None));
self.data.image_available_semaphores
.iter()
.for_each(|s| self.device.destroy_semaphore(*s, None));
// ...
}要确保每次都使用正确的信号量,我们需要跟踪当前帧。我们将使用一个帧索引来实现,我们把它添加到 App 中(在 App::create 中将其初始化为 0):
struct App {
// ...
frame: usize,
}然后修改 App::render 函数,使用正确的信号量对象:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
let image_index = self
.device
.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphores[self.frame],
vk::Fence::null(),
)?
.0 as usize;
// ...
let wait_semaphores = &[self.data.image_available_semaphores[self.frame]];
// ...
let signal_semaphores = &[self.data.render_finished_semaphores[self.frame]];
// ...
Ok(())
}当然,记得每次都要前进到下一帧:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.frame = (self.frame + 1) % MAX_FRAMES_IN_FLIGHT;
Ok(())
}使用取余(%)运算符,我们可以确保在每次入队 MAX_FRAMES_IN_FLIGHT 帧之后,帧索引都会绕回到 0。
尽管我们现在已经设置了所需的对象来同时处理多帧,但我们仍然没有真正阻止多于 MAX_FRAMES_IN_FLIGHT 的帧被提交。现在只有 GPU-GPU 同步,没有 CPU-GPU 同步来跟踪工作的进度。我们可能在帧 #0 还在飞行的时候就使用了与帧 #0 关联的对象!
要进行 CPU-GPU 同步,Vulkan 提供了第二种同步原语 —— 栅栏。栅栏与信号量类似,栅栏可以发出信号,也可以等待栅栏发出的信号。但这次我们实际上要在自己的代码中等待。我们首先为 AppData 中的每一帧创建一个栅栏:
struct AppData {
// ...
in_flight_fences: Vec<vk::Fence>,
}我们会在 create_sync_objects 函数中一起创建信号量和栅栏:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
let semaphore_info = vk::SemaphoreCreateInfo::builder();
let fence_info = vk::FenceCreateInfo::builder();
for _ in 0..MAX_FRAMES_IN_FLIGHT {
data.image_available_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
data.render_finished_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
data.in_flight_fences.push(device.create_fence(&fence_info, None)?);
}
Ok(())
}创建栅栏(vk::Fence)的方式与创建信号量非常相似。同样,确保在 App::destroy 中清理栅栏:
unsafe fn destroy(&mut self) {
self.data.in_flight_fences
.iter()
.for_each(|f| self.device.destroy_fence(*f, None));
// ...
}现在我们修改 App::render 函数并将栅栏用于同步。queue_submit 调用包含一个可选的参数,为其传递一个栅栏,当指令缓冲执行完毕时该栅栏会发出信号。我们可以使用这个来发出帧已经完成的信号。
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.device.queue_submit(
self.data.graphics_queue,
&[submit_info],
self.data.in_flight_fences[self.frame],
)?;
// ...
}现在剩下的就是修改 App::render 的开头,等待帧完成:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
self.device.wait_for_fences(
&[self.data.in_flight_fences[self.frame]],
true,
u64::MAX,
)?;
self.device.reset_fences(&[self.data.in_flight_fences[self.frame]])?;
// ...
}wait_for_fences 函数接受一个栅栏数组,并等待其中任意一个或全部栅栏发出信号后再返回。我们传递的 true 参数表示我们想要等待所有栅栏,但是在只有一个栅栏的情况下,这显然并不重要。与 acquire_next_image_khr 一样,这个函数也接受一个超时参数。与信号量不同,我们需要调用 reset_fences 函数手动将栅栏重置到未发出信号的状态。
如果你现在运行程序,你会发现一些奇怪的事情。应用程序似乎不再渲染任何东西,甚至可能会卡死。
这就意味着我们正在等待一个还没有发出信号的栅栏。问题在于,默认情况下,栅栏在创建之后处于未发出信号的状态。这意味着如果我们之前没有使用过栅栏,wait_for_fences 就会永远等待。要解决这个问题,我们可以修改栅栏的创建方式,将其初始化为已经发出信号的状态,就好像我们已经渲染了一帧:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
// ...
let fence_info = vk::FenceCreateInfo::builder()
.flags(vk::FenceCreateFlags::SIGNALED);
// ...
}现在就没有内存泄漏的问题了,但程序还不能正常工作。如果 MAX_FRAMES_IN_FLIGHT 大于交换链图像的数量,或者 acquire_next_image_khr 返回的图像是无序的,那么我们可能会开始渲染一个已经在飞行中(in flight)的交换链图像。为了避免这种情况,我们需要跟踪每个交换链图像是否有一个正在使用它的帧。这个映射将通过它们的栅栏来引用飞行帧,因此我们将立即拥有一个同步对象来等待,直到新的帧可以使用该图像。
首先在 AppData 中添加一个名为 images_in_flight 的新列表来跟踪正在使用的图像:
struct AppData {
// ...
in_flight_fences: Vec<vk::Fence>,
images_in_flight: Vec<vk::Fence>,
}并在 create_sync_objects 中初始化它:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
// ...
data.images_in_flight = data.swapchain_images
.iter()
.map(|_| vk::Fence::null())
.collect();
Ok(())
}在最开始的时候,没有帧在使用图像,因此我们显式地将其初始化为没有栅栏(no fence)。现在我们将修改 App::render,等待任何正在使用我们刚刚为新帧分配的图像的上一帧:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
let image_index = self
.device
.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphores[self.frame],
vk::Fence::null(),
)?
.0 as usize;
if !self.data.images_in_flight[image_index as usize].is_null() {
self.device.wait_for_fences(
&[self.data.images_in_flight[image_index as usize]],
true,
u64::MAX,
)?;
}
self.data.images_in_flight[image_index as usize] =
self.data.in_flight_fences[self.frame];
// ...
}因为我们现在有多个 wait_for_fences 调用,reset_fences 的调用也应该相应地改变。最好在实际使用栅栏之前再调用它:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.device.reset_fences(&[self.data.in_flight_fences[self.frame]])?;
self.device.queue_submit(
self.data.graphics_queue,
&[submit_info],
self.data.in_flight_fences[self.frame],
)?;
// ...
}现在我们实现了所需的所有同步机制,确保没有两帧以上的工作被排入队列,并且排入队列的两帧不会使用同一张图像。代码中的其他部分,例如最终的清理工作,仍然可以依赖于 device_wait_idle 这类更粗略的同步机制。你应该基于性能需求选择使用哪种方式。
要通过示例学习更多关于同步机制的知识,请参阅 Khronos 编写的这篇全面概述。
结论
在编写了大概 600 行代码之后,我们终于看到有东西在屏幕上显示出来了!从零开始编写一个 Vulkan 程序显然是一项艰巨的任务,但要点是,Vulkan 通过其明确性为你提供了巨大的控制权。我建议你花些时间重读代码,并建立程序中所有 Vulkan 对象以及对象之间关系的思维模型。从现在开始,我们将以这些知识为基石,扩展我们程序的功能。
在下一章中,我们将处理良好的 Vulkan 程序需要的一点小事。
重建交换链
原文链接:https://kylemayes.github.io/vulkanalia/swapchain/recreation.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
现在应用程序能画出三角形了,但它还没有正确处理一些情况。窗口表面可能会发生变化,使得交换链不再与之兼容。导致这种情况发生的原因之一是窗口的大小发生了变化。我们必须捕获这些事件并重新创建交换链。
重建交换链
添加一个 App::recreate_swapchain 方法,它调用 create_swapchain 来创建交换链,并调用所有依赖于交换链或者窗口大小的对象的创建函数:
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
self.device.device_wait_idle()?;
create_swapchain(window, &self.instance, &self.device, &mut self.data)?;
create_swapchain_image_views(&self.device, &mut self.data)?;
create_render_pass(&self.instance, &self.device, &mut self.data)?;
create_pipeline(&self.device, &mut self.data)?;
create_framebuffers(&self.device, &mut self.data)?;
create_command_buffers(&self.device, &mut self.data)?;
self.data
.images_in_flight
.resize(self.data.swapchain_images.len(), vk::Fence::null());
Ok(())
}和上一章一样,我们首先调用 device_wait_idle,因为我们不能在资源正在被使用时修改它们。显然,我们要做的第一件事就是重建交换链本身。因为图像视图直接基于交换链图像,所以图像视图也需要被重建。因为渲染流程依赖于交换链图像的格式,所以渲染流程也需要被重建。在像窗口大小调整这样的操作中,交换链图像的格式改变的可能性很小,但是我们仍然需要处理这种情况。视口和裁剪矩形的大小在图形管线创建时指定,所以图形管线也需要被重建。使用动态状态来指定视口和裁剪矩形可以避免这种情况。然后,帧缓冲和指令缓冲也直接依赖于交换链图像。最后,我们调整了交换链图像的信号量列表的大小,因为重建后交换链图像的数量可能会发生变化。
为了确保在重建这些对象之前清理旧对象,我们应该将清理这些对象的代码从 App::destroy 方法中提取出来,移动到一个单独的 App::destroy_swapchain 方法中
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
self.device.device_wait_idle()?;
self.destroy_swapchain();
// ...
}
unsafe fn destroy_swapchain(&mut self) {
}然后我们将所有在交换链刷新时重建的对象的清理代码从 App::destroy 移动到 App::destroy_swapchain 中:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.data.in_flight_fences
.iter()
.for_each(|f| self.device.destroy_fence(*f, None));
self.data.render_finished_semaphores
.iter()
.for_each(|s| self.device.destroy_semaphore(*s, None));
self.data.image_available_semaphores
.iter()
.for_each(|s| self.device.destroy_semaphore(*s, None));
self.device.destroy_command_pool(self.data.command_pool, None);
self.device.destroy_device(None);
self.instance.destroy_surface_khr(self.data.surface, None);
if VALIDATION_ENABLED {
self.instance.destroy_debug_utils_messenger_ext(self.data.messenger, None);
}
self.instance.destroy_instance(None);
}
unsafe fn destroy_swapchain(&mut self) {
self.data.framebuffers
.iter()
.for_each(|f| self.device.destroy_framebuffer(*f, None));
self.device.free_command_buffers(self.data.command_pool, &self.data.command_buffers);
self.device.destroy_pipeline(self.data.pipeline, None);
self.device.destroy_pipeline_layout(self.data.pipeline_layout, None);
self.device.destroy_render_pass(self.data.render_pass, None);
self.data.swapchain_image_views
.iter()
.for_each(|v| self.device.destroy_image_view(*v, None));
self.device.destroy_swapchain_khr(self.data.swapchain, None);
}我们也可以从头开始重建指令池,不过那样就太浪费了。因此我选择使用 free_command_buffers 函数清理现有的指令缓冲。这样我们就可以重用现有的指令池来分配新的指令缓冲。
这就是重建交换链所需的所有操作!然而,这样做的缺陷就是我们需要在创建新的交换链之前停止所有渲染操作。在旧交换链的图像上的绘制指令仍在执行时创建新的交换链是可能的。你需要将旧交换链传递给 vk::SwapchainCreateInfoKHR 结构体中的 old_swapchain 字段,并在使用完旧交换链后立即销毁它。
检测次优或过时的交换链
现在我们只需要确定什么时候必须重建交换链,并且调用 App::recreate_swapchain 方法。幸运地是,Vulkan 通常会在交换链不再适用时告诉我们。acquire_next_image_khr 和 queue_present_khr 函数可以返回以下特殊值来指示这一点。
vk::ErrorCode::OUT_OF_DATE_KHR– 交换链与表面不再兼容,不能再用于渲染。通常发生在窗口大小调整之后。vk::SuccessCode::SUBOPTIMAL_KHR– 交换链仍然能向表面呈现内容,但是表面的属性不再与交换链完全匹配。
let result = self.device.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphores[self.frame],
vk::Fence::null(),
);
let image_index = match result {
Ok((image_index, _)) => image_index as usize,
Err(vk::ErrorCode::OUT_OF_DATE_KHR) => return self.recreate_swapchain(window),
Err(e) => return Err(anyhow!(e)),
};如果在尝试从交换链获取图像时发现交换链已经过时,那么就不能再向它呈现内容了。因此我们应该立即重建交换链,并在下一次 App::render 调用时再次尝试。
你也可以选择在交换链不再最优时重建交换链,但我选择在这种情况下继续进行渲染,因为我们已经获取了一个图像。因为 vk::SuccessCode::SUBOPTIMAL_KHR 被认为是一个成功的代码而不是一个错误代码,所以它将被 match 块中的 Ok 分支处理。
let result = self.device.queue_present_khr(self.data.present_queue, &present_info);
let changed = result == Ok(vk::SuccessCode::SUBOPTIMAL_KHR)
|| result == Err(vk::ErrorCode::OUT_OF_DATE_KHR);
if changed {
self.recreate_swapchain(window)?;
} else if let Err(e) = result {
return Err(anyhow!(e));
}queue_present_khr 函数返回和 acquire_next_image_khr 相同的值,意义也相同。在这种情况下,如果交换链是次优的,我们也会重建交换链,因为我们想要最好的结果。
显式地处理窗口大小变化
尽管许多平台和驱动程序都会在窗口大小改变后自动触发 vk::ErrorCode::OUT_OF_DATE_KHR,但并不保证如此。这就是为什么我们要添加一些额外的代码来显式地处理窗口大小变化。首先在 App 结构体中添加一个新字段来追踪窗口大小是否发生了改变:
struct App {
// ...
resized: bool,
}记得在 App::create 中将这个新字段初始化为 false。然后在 App::render 方法中,在调用 queue_present_khr 之后也检查这个标志:
let result = self.device.queue_present_khr(self.data.present_queue, &present_info);
let changed = result == Ok(vk::SuccessCode::SUBOPTIMAL_KHR)
|| result == Err(vk::ErrorCode::OUT_OF_DATE_KHR);
if self.resized || changed {
self.resized = false;
self.recreate_swapchain(window)?;
} else if let Err(e) = result {
return Err(anyhow!(e));
}注意要在 queue_present_khr 之后执行这个操作,以确保信号量处于一致的状态,否则一个已经发出信号的信号量可能永远不会被正确地等待。现在我们可以在 main 中的窗口事件 match 块中添加一个分支来实际检测调整大小:
match event {
// ...
Event::WindowEvent { event: WindowEvent::Resized(_), .. } => app.resized = true,
// ...
}现在尝试运行程序并调整窗口大小,看看帧缓冲是否确实与窗口一起正确调整大小。
处理窗口最小化
还有一种特殊的情况会导致交换链过时,那就是一种特殊的窗口调整大小:窗口最小化。这种情况很特殊,因为它会导致帧缓冲大小为 0。在本教程中,我们将通过在窗口最小化时不渲染帧来处理这种情况:
let mut app = unsafe { App::create(&window)? };
let mut minimized = false;
event_loop.run(move |event,elwt| {
match event {
// ...
Event::WindowEvent { event, .. } => match event {
WindowEvent::RedrawRequested if !elwt.exiting() && !minimized => {
unsafe { app.render(&window) }.unwrap();
},
WindowEvent::Resized(size) => {
if size.width == 0 || size.height == 0 {
minimized = true;
} else {
minimized = false;
app.resized = true;
}
}
// ...
}
// ...
}
})?;恭喜你,你已经完成了你的第一个行为良好的 Vulkan 程序!在下一章中,我们会避免在顶点着色器中硬编码顶点,并实际地使用一个顶点缓冲。
描述顶点输入
原文链接:https://kylemayes.github.io/vulkanalia/vertex/vertex_input_description.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs | shader.vert | shader.frag
在接下来的几章中,我们将用内存中的顶点缓冲替换顶点着色器中硬编码的顶点数据。我们将从最简单的方法开始,即创建一个对 CPU 可见的缓冲,并直接将顶点数据复制到其中。之后,我们将学习如何使用暂存缓冲将顶点数据复制到高性能内存中。
顶点着色器
首先修改顶点着色器,不再在着色器代码本身中包含顶点数据。顶点着色器将使用 in 关键字从顶点缓冲中获取输入。
#version 450
layout(location = 0) in vec2 inPosition;
layout(location = 1) in vec3 inColor;
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
}
inPosition 和 inColor 变量是顶点属性。它们是在顶点缓冲中为每个顶点指定的属性,就像我们之前手动使用两个数组为每个顶点指定了位置和颜色一样。记得重新编译顶点着色器!
与 fragColor 类似,layout(location = x) 注解为输入变量分配了索引,我们稍后可以用索引来引用这些变量。重要的是要知道,某些类型(例如 64 位的 dvec3 向量)使用多个槽位。这意味着在它之后的索引必须至少 +2:
layout(location = 0) in dvec3 inPosition;
layout(location = 2) in vec3 inColor;
你可以在 OpenGL wiki 中找到关于布局限定符的更多信息。
顶点数据
我们将从着色器代码中将顶点数据移到程序代码的数组中。首先,向我们的程序添加几个导入项和一些类型别名。
use std::mem::size_of;
use cgmath::{vec2, vec3};
type Vec2 = cgmath::Vector2<f32>;
type Vec3 = cgmath::Vector3<f32>;size_of 函数将用于计算我们将要定义的顶点数据的大小,而 cgmath 则定义了我们需要的向量类型。
接下来,创建一个名为 Vertex 的 #[repr(C)] 结构体,其中包含我们将在顶点着色器中使用的两个属性,并添加一个简单的构造函数:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct Vertex {
pos: Vec2,
color: Vec3,
}
impl Vertex {
const fn new(pos: Vec2, color: Vec3) -> Self {
Self { pos, color }
}
}cgmath 提供了与着色器语言中使用的向量类型完全匹配的 Rust 类型。
static VERTICES: [Vertex; 3] = [
Vertex::new(vec2(0.0, -0.5), vec3(1.0, 0.0, 0.0)),
Vertex::new(vec2(0.5, 0.5), vec3(0.0, 1.0, 0.0)),
Vertex::new(vec2(-0.5, 0.5), vec3(0.0, 0.0, 1.0)),
];现在我们可以使用 Vertex 结构体来定义顶点数据了。我们使用了与之前完全相同的位置和颜色值,但现在顶点位置和颜色数据被合并进一个顶点数组中。这种定义顶点数据的方式也被称为交错顶点属性(interleaving vertex attributes)。
绑定描述
接下来的步骤是告诉 Vulkan 在顶点数据上传到 GPU 内存后如何将这些数据传递给顶点着色器。我们需要两种结构体来传递这些信息。
第一种结构体是顶点绑定 vk::VertexInputBindingDescription,我们为 Vertex 结构体添加一个方法来填充它:
impl Vertex {
fn binding_description() -> vk::VertexInputBindingDescription {
}
}顶点绑定描述了从内存中加载数据的方式:它指定了数据条目之间的字节数,以及是在每个顶点后移动到下一个数据条目,还是在每个实例后移动到下一个数据条目。
vk::VertexInputBindingDescription::builder()
.binding(0)
.stride(size_of::<Vertex>() as u32)
.input_rate(vk::VertexInputRate::VERTEX)
.build()我们的每个顶点的数据都被紧密地打包在一个数组中,因此我们只会有一个绑定。binding 参数指定绑定在绑定数组中的索引。stride 参数指定从一个条目到下一个条目的字节数,而 input_rate 参数可以有以下值之一:
vk::VertexInputRate::VERTEX– 在每个顶点后移动到下一个数据条目vk::VertexInputRate::INSTANCE– 在每个实例后移动到下一个数据条目
由于我们不会使用实例化渲染(instanced rendering),因此我们将使用每个顶点的数据。
属性描述
第二种结构体是 vk::VertexInputAttributeDescription,它用于描述顶点输入。我们将为 Vertex 结构体添加另一个辅助方法来填充这些结构。
impl Vertex {
fn attribute_descriptions() -> [vk::VertexInputAttributeDescription; 2] {
}
}如函数原型所示,我们将会创建两个这样的结构体。这个结构体描述了如何从顶点绑定产生的顶点数据块中提取顶点属性。我们有两个属性:位置和颜色,因此我们需要两个结构体。
let pos = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(0)
.format(vk::Format::R32G32_SFLOAT)
.offset(0)
.build();binding 参数告诉 Vulkan 顶点数据来自哪个绑定。location 参数引用了顶点着色器中输入的 location 指令。顶点着色器中顶点位置的 location 是 0,它有两个 32 位浮点分量。
format 参数描述属性的数据类型。有点混淆的是,format 字段使用与颜色格式相同的枚举类型。以下是常见的着色器类型和对应的颜色格式枚举:
f32–vk::Format::R32_SFLOATcgmath::Vector2<f32>(我们的Vec2) –vk::Format::R32G32_SFLOATcgmath::Vector3<f32>(我们的Vec3) –vk::Format::R32G32B32_SFLOATcgmath::Vector4<f32>–vk::Format::R32G32B32A32_SFLOAT
如你所见,颜色格式的颜色通道数量应与着色器数据类型的分量数量相匹配。颜色格式的通道数量比着色器数据类型的分量数量多也是可以的,但多余的通道将被静默丢弃。如果通道数量少于分量数量,则 BGA 分量将使用默认值 (0, 0, 1) 。颜色类型( SFLOAT ,UINT ,SINT )和位宽度也应与着色器数据类型匹配。请参阅以下示例:
cgmath::Vector2<i32>–vk::Format::R32G32_SINT,包含i32的 2 分量向量cgmath::Vector4<u32>–vk::Format::R32G32B32A32_UINT,包含u32的 4 分量向量f64–vk::Format::R64_SFLOAT,双精度(64位)浮点数
format 参数隐式地定义了属性数据的字节大小,而 offset 参数指定从顶点数据开始的字节数:绑定每次加载一个 Vertex,位置属性(pos)从该结构体的开始处偏移 0 字节。
let color = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(1)
.format(vk::Format::R32G32B32_SFLOAT)
.offset(size_of::<Vec2>() as u32)
.build();颜色属性的描述方式基本相同。
最后,构造要从辅助方法返回的数组:
[pos, color]管线顶点输入
现在我们需要在 create_pipeline 中引用这两个描述结构体,以让图形管线接受这种格式的顶点数据。找到 vertex_input_state 结构并修改它,让它引用这两个描述结构体:
let binding_descriptions = &[Vertex::binding_description()];
let attribute_descriptions = Vertex::attribute_descriptions();
let vertex_input_state = vk::PipelineVertexInputStateCreateInfo::builder()
.vertex_binding_descriptions(binding_descriptions)
.vertex_attribute_descriptions(&attribute_descriptions);现在,管线已准备好接受 vertices 容器格式的顶点数据,并将其传递给我们的顶点着色器。如果你现在启用了校验层并运行程序,你会看到它抱怨没有顶点缓冲被绑定到绑定点。接下来的步骤是创建一个顶点缓冲,并将顶点数据移到其中,以便 GPU 能够访问它。
创建顶点缓冲
原文链接:https://kylemayes.github.io/vulkanalia/vertex/vertex_buffer_creation.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在 Vulkan 中,缓冲是用于存储可被显卡读取的任意数据的内存区域。我们会在本章中用它们来存储顶点数据,但它们也可以用于许多其他目的,这些将在以后的章节中探讨。与我们到目前为止见过的 Vulkan 对象不同,缓冲不会自动为自己分配内存。前面章节中的工作已经表明,Vulkan API 将几乎所有事物置于程序员的控制下,内存管理就是其中之一。
尽管本教程只使用 Vulkan API 管理内存, 但现实世界中的许多 Vulkan 应用程序使用更高级的抽象,例如 Vulkan 内存分配器(VMA)。VMA 是一个库,它封装了 Vulkan API,并使内存管理变得更加简单和容易。
vulkanalia-vmacrate(vulkanalia项目的一部分)提供了 VMA 与vulkanalia的集成。
创建缓冲
首先,我们创建一个名为 create_vertex_buffer 的新函数,并在 App::create 函数中,在 create_command_buffers 之前调用它。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_vertex_buffer(&instance, &device, &mut data)?;
create_command_buffers(&device, &mut data)?;
// ...
}
}
unsafe fn create_vertex_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}创建缓冲需要填充一个 vk::BufferCreateInfo 结构体。
let buffer_info = vk::BufferCreateInfo::builder()
.size((size_of::<Vertex>() * VERTICES.len()) as u64)
// continued...结构体的第一个字段是 size ,它指定缓冲的大小,以字节为单位。使用 size_of 可以很容易地计算出顶点数据的大小。
.usage(vk::BufferUsageFlags::VERTEX_BUFFER)结构体的第二个字段是 usage,它表示缓冲中的数据将用于哪些目的。使用按位或可以指定多个目的。在当前的场景下我们会将缓冲用作顶点缓冲,关于其他类型的用法将在以后的章节中讨论。
.sharing_mode(vk::SharingMode::EXCLUSIVE);和交换链中的图像一样,缓冲也既可以由特定的队列族拥有,或者在多个队列族之间共享。由于缓冲仅将在图形队列中使用,因此我们可以使用独占访问。
.flags(vk::BufferCreateFlags::empty()); // 可选flags 参数用于配置稀疏缓冲内存(sparse buffer memory),现在我们还不用关心这个。你可以省略这个字段,它会被自动设置为默认值(空标志集)。
现在,我们可以使用 create_buffer 创建缓冲。首先在 AppData 中添加一个 vertex_buffer 字段来保存缓冲句柄。
struct AppData {
// ...
vertex_buffer: vk::Buffer,
}接下来在 create_vertex_buffer 中调用 create_buffer:
unsafe fn create_vertex_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let buffer_info = vk::BufferCreateInfo::builder()
.size((size_of::<Vertex>() * VERTICES.len()) as u64)
.usage(vk::BufferUsageFlags::VERTEX_BUFFER)
.sharing_mode(vk::SharingMode::EXCLUSIVE);
data.vertex_buffer = device.create_buffer(&buffer_info, None)?;
Ok(())
}缓冲应该在程序结束之前在渲染指令中保持可用,并且缓冲不依赖于交换链,因此我们将在 App::destroy 方法中清理它:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_buffer(self.data.vertex_buffer, None);
// ...
}内存需求
缓冲已经创建了,但实际上我们还没有为其分配任何内存。为缓冲分配内存的第一步是使用 get_buffer_memory_requirements 函数查询其内存需求。
let requirements = device.get_buffer_memory_requirements(data.vertex_buffer);这个函数返回的 vk::MemoryRequirements 结构体有三个字段:
size– 所需内存大小(以字节为单位),可能与buffer_info.size不同。alignment– 缓冲在内存分配的区域中开始的偏移量(以字节为单位),取决于buffer_info.usage和buffer_info.flags。memory_type_bits– 适用于缓冲的内存类型。
显卡可以分配不同类型的内存,每种类型的内存在允许的操作和性能特性方面各不相同。我们需要将缓冲的需求(vk::MemoryRequirements)和我们应用程序的需求结合起来,找到合适的内存类型。为此,我们创建一个新函数 get_memory_type_index。
unsafe fn get_memory_type_index(
instance: &Instance,
data: &AppData,
properties: vk::MemoryPropertyFlags,
requirements: vk::MemoryRequirements,
) -> Result<u32> {
}首先,我们需要使用 get_physical_device_memory_properties 查询设备上可用的内存类型。
let memory = instance.get_physical_device_memory_properties(data.physical_device);返回的 vk::PhysicalDeviceMemoryProperties 结构体有两个数组 memory_types 和 memory_heaps。内存堆代表不同的内存资源,比如专用的 VRAM 和在 VRAM 耗尽时 RAM 中的交换空间。这些堆中有不同类型的内存。现在我们只关注内存类型,而不关注内存来自哪个堆,但你应该能想到不同的堆会影响性能。
首先,让我们找到一个对缓冲本身合适的内存类型:
(0..memory.memory_type_count)
.find(|i| (requirements.memory_type_bits & (1 << i)) != 0)
.ok_or_else(|| anyhow!("Failed to find suitable memory type."))requirements 参数中的 memory_type_bits 字段将被用于指定适合的内存类型。这意味着我们可以通过简单地迭代并检查相应的位是否设置为 1 来找到适合的内存类型的索引。
然而,内存类型不仅要对顶点缓冲合适,我们还需要能够将顶点数据写入该内存。memory_types 数组由 vk::MemoryType 结构体组成,该结构体指定每种类型内存的堆(heap)和属性(properties)。属性定义了内存的特殊特性,例如能否从 CPU 映射它以便我们从 CPU 写入数据 —— 这个属性通过 vk::MemoryPropertyFlags::HOST_VISIBLE 来指示。我们还需要使用 vk::MemoryPropertyFlags::HOST_COHERENT 属性。我们将在映射内存时看到为什么需要这样做。
现在,修改循环以检查此属性的支持:
(0..memory.memory_type_count)
.find(|i| {
let suitable = (requirements.memory_type_bits & (1 << i)) != 0;
let memory_type = memory.memory_types[*i as usize];
suitable && memory_type.property_flags.contains(properties)
})
.ok_or_else(|| anyhow!("Failed to find suitable memory type."))如果存在适合缓冲的内存类型,并且该内存类型具有我们所需的所有属性,则返回其索引;否则返回错误。
内存分配
现在我们已经有了确定正确内存类型的方法,我们可以填充 vk::MemoryAllocateInfo 结构体来实际分配内存了。
let memory_info = vk::MemoryAllocateInfo::builder()
.allocation_size(requirements.size)
.memory_type_index(get_memory_type_index(
instance,
data,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
requirements,
)?);内存分配就是简单地指定大小和类型,这两者都来自于顶点缓冲的内存需求和所需的属性。在 AppData 中添加一个字段来存储内存句柄:
struct AppData {
// ...
vertex_buffer: vk::Buffer,
vertex_buffer_memory: vk::DeviceMemory,
}调用 allocate_memory 来填充这个新字段:
data.vertex_buffer_memory = device.allocate_memory(&memory_info, None)?;如果内存分配成功,我们就可以使用 bind_buffer_memory 将内存与缓冲关联起来:
device.bind_buffer_memory(data.vertex_buffer, data.vertex_buffer_memory, 0)?;前两个参数不言自明,第三个参数是顶点数据在内存区域内的偏移量。由于此内存专门为顶点缓冲分配,因此偏移量是 0。如果我们要提供非零的偏移量,则这个值必须可被 requirements.alignment 整除。
当然,就像在 C 语言中动态分配的内存一样,内存应该在某个时候被释放。绑定到缓冲对象的内存在缓冲不再被使用时可以被释放,所以让我们在缓冲被销毁后释放它:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_buffer(self.data.vertex_buffer, None);
self.device.free_memory(self.data.vertex_buffer_memory, None);
// ...
}填充顶点缓冲
现在是时候将顶点数据复制到缓冲了,这是使用 map_memory 函数通过将缓冲内存映射到 CPU 可访问的内存中来完成的。
let memory = device.map_memory(
data.vertex_buffer_memory,
0,
buffer_info.size,
vk::MemoryMapFlags::empty(),
)?;该函数允许我们访问由偏移量和大小指定的内存区域。在这里,偏移量和大小分别为 0 和 buffer_info.size。还可以使用特殊值 vk::WHOLE_SIZE 来映射所有内存。最后一个参数可用于指定标志,但当前 API 中还没有任何可用的标志。它必须设置为空标志集。返回的值是映射值的指针。
在继续之前,我们需要一个将顶点列表的内存复制到映射内存中的函数。在程序中添加这个导入:
use std::ptr::copy_nonoverlapping as memcpy;现在我们可以将顶点数据复制到缓冲内存中,然后使用 unmap_memory 取消映射。
memcpy(VERTICES.as_ptr(), memory.cast(), VERTICES.len());
device.unmap_memory(data.vertex_buffer_memory);不幸的是,出于诸如缓存(caching)的原因,驱动程序可能不会立即将数据复制到缓冲内存中。写入缓冲的数据亦可能在映射内存中尚不可见。有两种方法可以解决这个问题:
- 使用主机一致(host coherent)的内存堆,这种堆使用
vk::MemoryPropertyFlags::HOST_COHERENT表示 - 在写入映射内存后调用
flush_mapped_memory_ranges,并在读取映射内存之前调用invalidate_mapped_memory_ranges
我们采用了第一种方法,这样可以确保映射内存始终与分配的内存内容相匹配。相较于冲刷(flush)内存而言,这样做性能稍差,但我们将在下一章看到为什么这没关系。
冲刷内存范围或使用一致性内存堆意味着驱动程序将知道我们对缓冲的写入,但这并不意味着我们写入的数据实际上已经在 GPU 上可见。将数据传输到 GPU 是在后台进行的操作,规范仅保证这个操作在我们下一次调用 queue_submit 时是完成的。
绑定顶点缓冲
现在,仅剩的任务是在渲染操作期间绑定顶点缓冲。我们将扩展 create_command_buffers 函数来完成这个任务。
// ...
device.cmd_bind_vertex_buffers(*command_buffer, 0, &[data.vertex_buffer], &[0]);
device.cmd_draw(*command_buffer, VERTICES.len() as u32, 1, 0, 0);
// ...cmd_bind_vertex_buffers 函数用于将顶点缓冲绑定到绑定点,就像我们在上一章中设置的那样。第二个参数指定我们正在使用的顶点输入绑定的索引。最后两个参数指定要绑定的顶点缓冲和从中开始读取顶点数据的字节偏移量。你还应该更改对 cmd_draw 的调用,将缓冲中的顶点数传递给该函数,代替原先硬编码的数字 3。
现在运行程序,你应该会再次看到熟悉的三角形:

通过修改 VERTICES 列表,将顶点的颜色更改为白色,可以尝试修改三角形的顶点颜色:
static VERTICES: [Vertex; 3] = [
Vertex::new(vec2(0.0, -0.5), vec3(1.0, 1.0, 1.0)),
Vertex::new(vec2(0.5, 0.5), vec3(0.0, 1.0, 0.0)),
Vertex::new(vec2(-0.5, 0.5), vec3(0.0, 0.0, 1.0)),
];再次运行程序,你应该会看到以下效果:
在下一章中,我们将介绍另一种将顶点数据复制到顶点缓冲的方法。这种方法能带来更好的性能,但需要更多的工作。
暂存缓冲
原文链接:https://kylemayes.github.io/vulkanalia/vertex/staging_buffer.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
目前我们的顶点缓冲可以正常工作,但是能直接从 CPU 访问的内存对于从显卡读取而言可能并不是最优的。最优内存具有 vk::MemoryPropertyFlags::DEVICE_LOCAL 标志,通常位于独立显卡上,无法由 CPU 访问。在本章中,我们将创建两个顶点缓冲。首先是位于 CPU 可访问内存中的暂存缓冲,用于将顶点数组中的数据上传至其中;然后是位于设备本地内存中的最终顶点缓冲。接着,我们将使用缓冲复制指令将数据从暂存缓冲复制到实际的顶点缓冲中。
传输队列
缓冲复制指令需要一个支持传输操作的队列族,这种队列族具有 vk::QueueFlags::TRANSFER 标志。好消息是,任何具有 vk::QueueFlags::GRAPHICS 或 vk::QueueFlags::COMPUTE 能力的队列族已经隐式地支持 vk::QueueFlags::TRANSFER 操作。在这种情况下,实现不需要在 queue_flags 中显式列出这个标志。
如果你愿意接受挑战,你仍然可以尝试为传输操作使用不同的队列族。这将需要你对程序进行以下修改:
- 修改
QueueFamilyIndices和QueueFamilyIndices::get,以明确寻找具有vk::QueueFlags::TRANSFER标志但不具有vk::QueueFlags::GRAPHICS的队列族。 - 修改
create_logical_device,以请求传输队列的句柄。 - 为在传输队列族上提交的指令缓冲创建第二个指令池。
- 将资源的
sharing_mode改为vk::SharingMode::CONCURRENT,并指定图形队列族和传输队列族。 - 将任何传输指令(在本章中将使用的
cmd_copy_buffer等)提交到传输队列,而不是图形队列。
虽然需要付出一些努力,但这将让你深入了解在不同队列族之间共享资源的重要知识。
抽象化缓冲创建
由于我们将在本章中创建多个缓冲,将缓冲创建操作移动到一个辅助函数中是个不错的主意。创建一个名为 create_buffer 的新函数,并将 create_vertex_buffer 中的代码(除了映射部分)迁移到该函数中:
unsafe fn create_buffer(
instance: &Instance,
device: &Device,
data: &AppData,
size: vk::DeviceSize,
usage: vk::BufferUsageFlags,
properties: vk::MemoryPropertyFlags,
) -> Result<(vk::Buffer, vk::DeviceMemory)> {
let buffer_info = vk::BufferCreateInfo::builder()
.size(size)
.usage(usage)
.sharing_mode(vk::SharingMode::EXCLUSIVE);
let buffer = device.create_buffer(&buffer_info, None)?;
let requirements = device.get_buffer_memory_requirements(buffer);
let memory_info = vk::MemoryAllocateInfo::builder()
.allocation_size(requirements.size)
.memory_type_index(get_memory_type_index(
instance,
data,
properties,
requirements,
)?);
let buffer_memory = device.allocate_memory(&memory_info, None)?;
device.bind_buffer_memory(buffer, buffer_memory, 0)?;
Ok((buffer, buffer_memory))
}确保将缓冲大小、用法以及内存属性添加到函数参数,以便于我们使用此函数创建多种不同类型的缓冲。
现在,你可以从 create_vertex_buffer 中删除创建缓冲和分配内存的代码,改为调用 create_buffer:
unsafe fn create_vertex_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let size = (size_of::<Vertex>() * VERTICES.len()) as u64;
let (vertex_buffer, vertex_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::VERTEX_BUFFER,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
)?;
data.vertex_buffer = vertex_buffer;
data.vertex_buffer_memory = vertex_buffer_memory;
let memory = device.map_memory(
vertex_buffer_memory,
0,
size,
vk::MemoryMapFlags::empty(),
)?;
memcpy(VERTICES.as_ptr(), memory.cast(), VERTICES.len());
device.unmap_memory(vertex_buffer_memory);
Ok(())
}运行程序,确保顶点缓冲仍然正常工作。
使用暂存缓冲
现在,我们要修改 create_vertex_buffer,使其只将主机可见的缓冲作为临时缓冲,并将一个设备本地缓冲用作实际的顶点缓冲。
unsafe fn create_vertex_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let size = (size_of::<Vertex>() * VERTICES.len()) as u64;
let (staging_buffer, staging_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::TRANSFER_SRC,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
)?;
let memory = device.map_memory(
staging_buffer_memory,
0,
size,
vk::MemoryMapFlags::empty(),
)?;
memcpy(VERTICES.as_ptr(), memory.cast(), VERTICES.len());
device.unmap_memory(staging_buffer_memory);
let (vertex_buffer, vertex_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::TRANSFER_DST | vk::BufferUsageFlags::VERTEX_BUFFER,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
data.vertex_buffer = vertex_buffer;
data.vertex_buffer_memory = vertex_buffer_memory;
Ok(())
}我们现在使用新的 staging_buffer 和 staging_buffer_memory 来映射和复制顶点数据。在本章中,我们将使用两个新的缓冲用法标志:
vk::BufferUsageFlags::TRANSFER_SRC– 缓冲可以作为内存传输操作的源。vk::BufferUsageFlags::TRANSFER_DST– 缓冲可以作为内存传输操作的目标。
vertex_buffer 现在是从设备本地内存类型分配的,这通常意味着我们不能使用 map_memory。然而,我们可以将数据从 staging_buffer 复制到 vertex_buffer。我们必须为 staging_buffer 指定传输源标志,为 vertex_buffer 指定传输目标标志和顶点缓冲用法标志,来表明我们的意图。
接下来,我们将编写一个名为 copy_buffer 的函数,用于将内容从一个缓冲复制到另一个缓冲。
unsafe fn copy_buffer(
device: &Device,
data: &AppData,
source: vk::Buffer,
destination: vk::Buffer,
size: vk::DeviceSize,
) -> Result<()> {
Ok(())
}内存传输操作与绘制指令一样,都需要通过指令缓冲来执行。因此,我们首先需要分配一个临时的指令缓冲。你可能希望为这些短暂的缓冲创建一个独立的指令池,因为实现可以对内存分配进行优化。在这种情况下,你应该在生成指令池时使用 vk::CommandPoolCreateFlags::TRANSIENT 标志。
unsafe fn copy_buffer(
device: &Device,
data: &AppData,
source: vk::Buffer,
destination: vk::Buffer,
size: vk::DeviceSize,
) -> Result<()> {
let info = vk::CommandBufferAllocateInfo::builder()
.level(vk::CommandBufferLevel::PRIMARY)
.command_pool(data.command_pool)
.command_buffer_count(1);
let command_buffer = device.allocate_command_buffers(&info)?[0];
Ok(())
}然后开始记录指令缓冲:
let info = vk::CommandBufferBeginInfo::builder()
.flags(vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT);
device.begin_command_buffer(command_buffer, &info)?;我们将只使用这个指令缓冲一次,并在复制操作完成之前等待函数返回。使用 vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT 标志可以向驱动程序表明我们的意图,这是一个很好的实践。
let regions = vk::BufferCopy::builder().size(size);
device.cmd_copy_buffer(command_buffer, source, destination, &[regions]);缓冲的内容通过 cmd_copy_buffer 指令进行传输。该指令以源缓冲、目标缓冲和待复制区域的数组为参数。区域由 vk::BufferCopy 结构体定义,结构体中包括源缓冲偏移量、目标缓冲偏移量和大小。需要注意的是,与 map_memory 指令不同,这里不能指定 vk::WHOLE_SIZE。
device.end_command_buffer(command_buffer)?;这个指令缓冲仅包含复制指令,因此我们在复制指令之后停止记录。现在执行该指令缓冲以完成传输操作:
let command_buffers = &[command_buffer];
let info = vk::SubmitInfo::builder()
.command_buffers(command_buffers);
device.queue_submit(data.graphics_queue, &[info], vk::Fence::null())?;
device.queue_wait_idle(data.graphics_queue)?;与绘制指令不同,这次我们无需等待事件,而是立即在缓冲上执行传输操作。同样,有两种方法可以等待传输完成。我们可以使用围栏(fence),并使用 wait_for_fences 来等待,或者只需使用 queue_wait_idle 等待传输队列变为空闲状态。使用围栏可以让你同时安排多个传输并等待它们全部完成,而不必逐个执行。这可以给驱动程序更多优化的机会。
device.free_command_buffers(data.command_pool, &[command_buffer]);别忘记清理用于传输操作的指令缓冲。
现在,我们可以在 create_vertex_buffer 函数中调用 copy_buffer,将顶点数据复制到设备本地缓冲:
copy_buffer(device, data, staging_buffer, vertex_buffer, size)?;在从暂存缓冲复制数据到设备缓冲之后,不要忘记进行清理:
device.destroy_buffer(staging_buffer, None);
device.free_memory(staging_buffer_memory, None);运行程序以验证你是否能再次看到熟悉的三角形。现在,顶点数据是从高性能内存加载的,尽管目前可能看不到改进。当我们开始渲染更复杂的几何图形时,这一点将变得更加重要。
结论
值得注意的是,在实际的应用程序中,你不应该为每个缓冲都调用 allocate_memory。内存分配的最大数量受到物理设备的 max_memory_allocation_count 限制,即使在高端硬件(如 NVIDIA GTX 1080)上,这个限制也可能低至 4096。要在同一时刻为大量对象分配内存,正确的方法是创建一个自定义的分配器,通过使用我们在许多函数中看到的 offset 参数,将单个分配分割为多个不同的对象。
然而,在本教程中可以为每个资源单独分配,因为目前我们不会接近这些限制。
索引缓冲
原文链接:https://kylemayes.github.io/vulkanalia/vertex/index_buffer.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在真正的应用程序中,你渲染的 3D 网格通常中的许多三角形之间都会共享顶点。即使是像绘制矩形这样简单的事情,也会遇到这种情况:

渲染一个矩形需要两个三角形,也就是说我们需要一个 6 个顶点的顶点缓冲。问题在于,有两个顶点的数据是重复的,这就导致了 50% 的冗余。对于更复杂的网格而言,平均每个顶点会被 3 个三角形使用,情况只会变得更糟。解决这个问题的方法就是使用索引缓冲。
一个索引缓冲实质上就是一个指向顶点缓冲的指针构成的数组。它允许你重排顶点数据,并为多个顶点复用现有数据。上面的插图展示了如果我们有一个包含每个独特顶点的顶点缓冲,那么矩形的索引缓冲会是什么样子。前三个索引定义了右上角的三角形,最后三个索引定义了左下角三角形的顶点。
创建索引缓冲
在本章中,我们将修改顶点数据,并添加索引数据来绘制一个像插图中那样的矩形。修改顶点数据以表示四个角:
static VERTICES: [Vertex; 4] = [
Vertex::new(vec2(-0.5, -0.5), vec3(1.0, 0.0, 0.0)),
Vertex::new(vec2(0.5, -0.5), vec3(0.0, 1.0, 0.0)),
Vertex::new(vec2(0.5, 0.5), vec3(0.0, 0.0, 1.0)),
Vertex::new(vec2(-0.5, 0.5), vec3(1.0, 1.0, 1.0)),
];左上角是红色的,右上角是绿色的,右下角是蓝色的,而左下角是白色的。我们将添加一个新的数组 INDICES 来表示索引缓冲的内容。它应该与插图中的索引匹配,以绘制右上角的三角形和左下角的三角形。
const INDICES: &[u16] = &[0, 1, 2, 2, 3, 0];取决于 VERTICES 中的条目数量,为索引缓冲使用 u16 和 u32 都是可以的。因为我们使用的顶点数量少于 65,536 个,所以我们可以使用 u16。
和顶点数据一样,索引也需要被上传到 vk::Buffer 中,GPU 才能访问它们。定义两个新的 AppData 字段来保存索引缓冲的资源:
struct AppData {
// ...
vertex_buffer: vk::Buffer,
vertex_buffer_memory: vk::DeviceMemory,
index_buffer: vk::Buffer,
index_buffer_memory: vk::DeviceMemory,
}接下来我们要添加的 create_index_buffer 函数和之前的 create_vertex_buffer 函数几乎一模一样:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_vertex_buffer(&instance, &device, &mut data)?;
create_index_buffer(&instance, &device, &mut data)?;
// ...
}
}
unsafe fn create_index_buffer(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let size = (size_of::<u16>() * INDICES.len()) as u64;
let (staging_buffer, staging_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::TRANSFER_SRC,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
)?;
let memory = device.map_memory(
staging_buffer_memory,
0,
size,
vk::MemoryMapFlags::empty(),
)?;
memcpy(INDICES.as_ptr(), memory.cast(), INDICES.len());
device.unmap_memory(staging_buffer_memory);
let (index_buffer, index_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::TRANSFER_DST | vk::BufferUsageFlags::INDEX_BUFFER,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
data.index_buffer = index_buffer;
data.index_buffer_memory = index_buffer_memory;
copy_buffer(device, data, staging_buffer, index_buffer, size)?;
device.destroy_buffer(staging_buffer, None);
device.free_memory(staging_buffer_memory, None);
Ok(())
}不过还是有两个值得一提的区别,size 现在等于索引数量乘以索引类型 —— 即 u16 或 u32 —— 的大小。index_buffer 的用途应该是 vk::BufferUsageFlags::INDEX_BUFFER 而不是 vk::BufferUsageFlags::VERTEX_BUFFER,这是有道理的。除此之外,整个过程完全一样:我们创建一个暂存缓冲,将 INDICES 的内容复制到其中,然后将其复制到最终的设备本地索引缓冲。
在程序结束时,和顶点缓冲一样,索引缓冲也应该被清理:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_buffer(self.data.index_buffer, None);
self.device.free_memory(self.data.index_buffer_memory, None);
self.device.destroy_buffer(self.data.vertex_buffer, None);
self.device.free_memory(self.data.vertex_buffer_memory, None);
// ...
}使用索引缓冲
在绘制中使用索引缓冲需要修改 create_command_buffer 中的两个地方。首先我们需要绑定索引缓冲,就像绑定顶点缓冲时一样。区别在于索引缓冲只能有一个。很不幸,为每个顶点属性使用不同的索引是不可行的,因此即使只有一个属性变化,我们仍然必须完全复制顶点数据。
device.cmd_bind_vertex_buffers(*command_buffer, 0, &[data.vertex_buffer], &[0]);
device.cmd_bind_index_buffer(*command_buffer, data.index_buffer, 0, vk::IndexType::UINT16);一个索引缓冲通过 cmd_bind_index_buffer 来绑定,这个函数接受索引缓冲、字节偏移量和索引数据类型作为参数。如前所述,可能的类型有 vk::IndexType::UINT16 和 vk::IndexType::UINT32。
只绑定索引缓冲还不够,我们要改变绘图指令,以告诉 Vulkan 使用索引缓冲。删除 cmd_draw 那一行,并用 cmd_draw_indexed 替换:
device.cmd_draw_indexed(*command_buffer, INDICES.len() as u32, 1, 0, 0, 0);cmd_draw_indexed 和 cmd_draw 的调用方式非常类似。指令缓冲后面的前两个参数指定了索引的数量和实例的数量。我们没有使用实例化,所以只指定 1 个实例。索引的数量表示将传递给顶点缓冲的顶点数量。下一个参数指定了索引缓冲的偏移量,传递 0 会让显卡从第一个索引开始读取。倒数第二个参数指定了要添加到索引缓冲中的索引的偏移量。最后一个参数指定了实例化(我们没有使用)的偏移量。
现在运行程序,然后你应该会看到如下画面:

现在你知道如何使用索引缓冲来重用顶点并节约内存了。这会在我们之后的章节中加载 3D 模型时变得尤为重要。
上一章已经提到过,你应该使用一次内存分配来分配多个资源,但事实上你应该更进一步。驱动开发者建议你将多个缓冲,例如顶点缓冲和索引缓冲,存储到一个 vk::Buffer 中,并在 cmd_bind_vertex_buffers 这样的函数中使用偏移量。这样做的好处是你的数据会因存放得更近而更缓存友好。如果这些资源在相同的渲染操作期间没有被使用,那么甚至可以重用同一块内存 —— 当然前提是数据被更新过。这被称为别名(aliasing),并且一些 Vulkan 函数有显式的参数来指定你想要这样做。
描述符集合布局与缓冲
原文链接:https://kylemayes.github.io/vulkanalia/uniform/descriptor_set_layout_and_buffer.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs | shader.vert | shader.frag
现在我们可以将任何顶点属性上传到顶点着色器了,但是全局变量怎么办呢?从本章开始我们要走向 3D,这就需要一个模型-试图-投影矩阵(model-view-projection matrix)。我们可以将它包含在顶点数据中,但这是一种浪费内存的做法,而且每当变换发生变化时,我们都需要更新顶点缓冲。而变换很可能每一帧都会发生变化。
在 Vulkan 中,正确的解决方式是使用资源描述符(resource descriptor)。描述符是一种能够让着色器自由访问缓冲和图像等资源的方法。我们将设置一个包含变换矩阵的缓冲,并让顶点着色器通过描述符访问它们。描述符的使用包括三个部分:
- 在创建管线时指定描述符集合布局
- 从描述符池中分配一个描述符集合
- 在渲染时绑定描述符集合
*描述符集合布局(descriptor set layout)*指定了管线将要访问的资源类型,就像渲染流程指定了将要访问的附件类型一样。*描述符集合(descriptor set)*指定了将要绑定到描述符的实际缓冲或图像资源,就像帧缓冲指定了要绑定到渲染流程附件的实际图像视图一样。然后,描述符集合就像顶点缓冲和帧缓冲一样,绑定到绘制指令中。
描述符有很多种,但在本章中我们将使用 uniform 缓冲对象(uniform buffer object,UBO)。我们将在以后的章节中介绍其他类型的描述符,但基本过程是相同的。假设我们有一个结构体,其中包含了我们希望顶点着色器能够访问的数据:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct UniformBufferObject {
model: Mat4,
view: Mat4,
proj: Mat4,
}接着我们将数据复制到一个 vk::Buffer 中,然后在顶点着色器中像这样通过一个 uniform 缓冲对象描述符来访问它:
layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;
// ...
void main() {
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
}
我们将在每一帧中更新模型、视图和投影矩阵,使得上一章中的矩形在 3D 空间中旋转起来。
顶点着色器
修改顶点着色器,像上面说的那样将 uniform 缓冲对象包含进来。我假设你已经熟悉了 MVP 变换。如果你不熟悉,可以参考第一章中提到的资源。
#version 450
layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;
layout(location = 0) in vec2 inPosition;
layout(location = 1) in vec3 inColor;
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
}
注意 uniform、in 和 out 声明之间的顺序是无关紧要的。binding 指令和属性的 location 指令类似。我们将会在描述符集合布局中引用这个绑定。gl_Position 所在的那一行被修改为使用变换来计算最终的裁剪坐标。与 2D 三角形不同,裁剪坐标的最后一个分量可能不是 1,这将导致在转换为屏幕上的最终归一化设备坐标时进行除法运算。这在透视投影中被称为透视除法,这对于实现今大远小的视觉效果是至关重要的。
描述符集合布局(descriptor set layout)
下一步就是在 Rust 这边定义 UBO 中的数据,并告诉 Vulkan 在顶点着色器中关于这个描述符的信息。首先我们添加一些导入和类型别名:
use cgmath::{point3, Deg};
type Mat4 = cgmath::Matrix4<f32>;接着创建 UniformBufferObject 结构体:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct UniformBufferObject {
model: Mat4,
view: Mat4,
proj: Mat4,
}使用 cgmath crate 中的数据类型,我们可以完全匹配着色器中的定义。矩阵中的数据与着色器期望的数据是二进制兼容的,所以之后我们可以直接将 UniformBufferObject 复制到 vk::Buffer 中。
我们需要提供管线创建时着色器中使用的每个描述符绑定的详细信息,就像我们为每个顶点属性及其 location 索引所做的那样。我们将创建一个名为 create_descriptor_set_layout 的新的函数来定义所有这些信息。它应该在创建管线之前被调用,因为我们将在创建管线时用到这些信息。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_descriptor_set_layout(&device, &mut data)?;
create_pipeline(&device, &mut data)?;
// ...
}
}
unsafe fn create_descriptor_set_layout(
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}每个绑定都需要使用 vk::DescriptorSetLayoutBinding 来描述。
unsafe fn create_descriptor_set_layout(
device: &Device,
data: &mut AppData,
) -> Result<()> {
let ubo_binding = vk::DescriptorSetLayoutBinding::builder()
.binding(0)
.descriptor_type(vk::DescriptorType::UNIFORM_BUFFER)
.descriptor_count(1)
.stage_flags(vk::ShaderStageFlags::VERTEX);
Ok(())
}前两个字段指定了着色器中使用的 binding 和描述符的类型 —— 这里是 uniform 缓冲对象。着色器变量可以表示由 uniform 缓冲对象组成的数组,descriptor_count 指定了数组中的值的数量。在实际的应用中,uniform 缓冲对象数组大有用处,例如它可以用来为骨骼中的每个骨骼指定一个变换。我们的 MVP 变换只用到了一个 uniform 缓冲对象,所以我们将 descriptor_count 设为 1。
我们还需要指定描述符将会在哪些着色器阶段被引用。stage_flags 字段可以是一系列 vk::ShaderStageFlags 值的组合,也可以是 vk::ShaderStageFlags::ALL_GRAPHICS。在我们的场景中,我们只在顶点着色器中使用这个描述符。
还有一个 immutable_samplers 字段,它只与图像采样相关的描述符有关,我们之后会看到。现在我们可以将它保留为默认值。
所有描述符绑定会被合并到一个 vk::DescriptorSetLayout 对象中。在 AppData 中,pipeline_layout 的上面新增一个字段:
struct AppData {
// ...
descriptor_set_layout: vk::DescriptorSetLayout,
pipeline_layout: vk::PipelineLayout,
// ...
}接着我们可以使用 create_descriptor_set_layout 来创建它。这个函数接受一个简单的 vk::DescriptorSetLayoutCreateInfo,其中包含了绑定的数组:
let bindings = &[ubo_binding];
let info = vk::DescriptorSetLayoutCreateInfo::builder()
.bindings(bindings);
data.descriptor_set_layout = device.create_descriptor_set_layout(&info, None)?;我们需要在创建管线时指定描述符集合布局,以告诉 Vulkan 着色器将会使用哪些描述符。修改 vk::PipelineLayoutCreateInfo 来引用描述符集合布局对象:
```rust,noplaypen
let set_layouts = &[data.descriptor_set_layout];
let layout_info = vk::PipelineLayoutCreateInfo::builder()
.set_layouts(set_layouts);你可能会好奇,为什么一个描述符集合布局就可以囊括所有绑定,这里却可以指定多个描述符集合布局。我们会在下一章讨论描述符池和描述符集合时再来审视这个问题。
描述符集合布局应该在我们创建新的图形管线时一直存在,直到程序结束:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_descriptor_set_layout(self.data.descriptor_set_layout, None);
// ...
}Uniform 缓冲
在下一章中我们将会为 shader 指定包含了 UBO 数据的缓冲,但我们得先创建这个缓冲。我们将在每一帧中都将新的数据复制到 uniform 缓冲中,所以使用一个暂存缓冲并没有什么意义。在这种情况下,暂存缓冲对提升性能没有帮助,只会增加额外的开销,反而可能降低性能。
我们应该有多个缓冲,因为可能有多个帧同时在参与渲染,并且我们并不希望在前一帧仍在读取缓冲时就为了下一帧更新缓冲!我们可以为每一帧或每一张交换链图像都创建一个 uniform 缓冲。然而,由于我们需要在每一张交换链图像的指令缓冲中引用 uniform 缓冲,所以为每一张交换链图像创建一个 uniform 缓冲是最合理的。
为此,在 AppData 中新增 uniform_buffers 和 uniform_buffers_memory 字段:
struct AppData {
// ...
index_buffer: vk::Buffer,
index_buffer_memory: vk::DeviceMemory,
uniform_buffers: Vec<vk::Buffer>,
uniform_buffers_memory: Vec<vk::DeviceMemory>,
// ...
}类似地,创建一个新函数 create_uniform_buffers,并在 create_index_buffer 之后调用它来分配缓冲:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_vertex_buffer(&instance, &device, &mut data)?;
create_index_buffer(&instance, &device, &mut data)?;
create_uniform_buffers(&instance, &device, &mut data)?;
// ...
}
}
unsafe fn create_uniform_buffers(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
data.uniform_buffers.clear();
data.uniform_buffers_memory.clear();
for _ in 0..data.swapchain_images.len() {
let (uniform_buffer, uniform_buffer_memory) = create_buffer(
instance,
device,
data,
size_of::<UniformBufferObject>() as u64,
vk::BufferUsageFlags::UNIFORM_BUFFER,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
)?;
data.uniform_buffers.push(uniform_buffer);
data.uniform_buffers_memory.push(uniform_buffer_memory);
}
Ok(())
}我们会另写一个函数来在每一帧中使用新的变换更新 uniform 缓冲,所以这里不需要 map_memory。uniform 数据将用于所有绘制调用,所以包含它的缓冲只应该在我们停止渲染时才被销毁。由于它还取决于交换链图像的数量,而交换链图像的数量在重建后可能会发生变化,所以我们将在 destroy_swapchain 中清理它:
unsafe fn destroy_swapchain(&mut self) {
self.data.uniform_buffers
.iter()
.for_each(|b| self.device.destroy_buffer(*b, None));
self.data.uniform_buffers_memory
.iter()
.for_each(|m| self.device.free_memory(*m, None));
// ...
}这也就意味着我们也得在 recreate_swapchain 中重建它:
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
// ...
create_framebuffers(&self.device, &mut self.data)?;
create_uniform_buffers(&self.instance, &self.device, &mut self.data)?;
create_command_buffers(&self.device, &mut self.data)?;
Ok(())
}更新 uniform 数据
创建一个新的方法 App::update_uniform_buffer 并在 App::render 方法中获取到交换链图像之后调用它:
impl App {
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
if !self.data.images_in_flight[image_index as usize].is_null() {
self.device.wait_for_fences(
&[self.data.images_in_flight[image_index as usize]],
true,
u64::max_value(),
)?;
}
self.data.images_in_flight[image_index as usize] =
self.data.in_flight_fences[self.frame];
self.update_uniform_buffer(image_index)?;
// ...
}
unsafe fn update_uniform_buffer(&self, image_index: usize) -> Result<()> {
Ok(())
}
}注意在此栅栏 (fence) 发出信号之前不要更新 uniform 缓冲!
快速回顾一下在 渲染与呈现 章节中介绍过的栅栏的用法,我们使用栅栏 (fences) 来让 GPU 在处理完之前提交的帧后通知 CPU。这些通知有两个用途:防止 CPU 在已经提交了 MAX_FRAMES_IN_FLIGHT 个未完成的帧给 GPU 时继续提交更多的帧;确保 CPU 不会在 GPU 仍在使用资源(如 uniform 缓冲或指令缓冲)处理帧时修改或删除这些资源。
我们的 uniform 缓冲与交换链图像相关联,所以在获取到交换链图像之后,我们需要确保任何之前渲染到这一张图像的帧都已经完成,然后我们才能安全地更新 uniform 缓冲。只有在 GPU 通知 CPU 这种情况发生后才更新 uniform 缓冲,我们才能安全地对 uniform 缓冲做任何操作。
回到 App::update_uniform_buffer,这个方法将会在每一帧中生成一个新的变换,使得几何体旋转起来。我们需要添加一个导入来实现这个功能:
use std::time::Instant;Instant 结构体提供了精准的时间记录功能。我们将使用它来确保几何体每秒旋转 90 度,而不管帧率如何。在 App 中添加一个字段来跟踪应用程序启动的时间,并在 App::create 中将该字段初始化为 Instant::now():
struct App {
// ...
start: Instant,
}现在我们可以使用该字段来确定应用程序启动后经过了多少秒:
unsafe fn update_uniform_buffer(&self, image_index: usize) -> Result<()> {
let time = self.start.elapsed().as_secs_f32();
Ok(())
}现在我们定义 uniform 缓冲对象中的模型、视图和投影变换。模型旋转将是一个简单的绕 Z 轴旋转,使用 time 变量:
let model = Mat4::from_axis_angle(
vec3(0.0, 0.0, 1.0),
Deg(90.0) * time
);Mat4::from_axis_angle 函数根据指定的旋转角度和转轴创建一个变换矩阵。使用 Deg(90.0) * time 作为旋转角度可以实现每秒旋转 90 度的目的。
let view = Mat4::look_at_rh(
point3(2.0, 2.0, 2.0),
point3(0.0, 0.0, 0.0),
vec3(0.0, 0.0, 1.0),
);至于视图变换,我决定从上方以 45 度的角度看几何体。Mat4::look_at_rh 函数接受眼睛位置、中心位置和上轴(up axis)作为参数。这个函数名中的 rh 表示它使用的是“右手系”,这也是 Vulkan 使用的坐标系。
let mut proj = cgmath::perspective(
Deg(45.0),
self.data.swapchain_extent.width as f32 / self.data.swapchain_extent.height as f32,
0.1,
10.0,
);我决定使用一个在垂直方向上具有 45 度视野(field-of-view)的透视投影。其他的参数分别是宽高比、近视平面和远视平面。使用当前的交换链的交换范围来计算宽高比是很重要的,这样可以将窗口在调整大小后的新尺寸考虑在内。
proj[1][1] *= -1.0;cgmath 原先是为 OpenGL 设计的,因此裁剪空间坐标中的 Y 坐标是反的。要修复这一点,最简单的方法是在反转投影矩阵的 Y 轴缩放因子的符号。如果不这样做,渲染出来的图像会呈现为上下翻转。
let ubo = UniformBufferObject { model, view, proj };最后我们将矩阵组合成一个 uniform 缓冲对象。
现在我们已经定义了所有的变换,可以将 uniform 缓冲对象中的数据复制到当前的 uniform 缓冲中了。这与我们为顶点缓冲所做的完全相同,除了没有用到暂存缓冲:
let memory = self.device.map_memory(
self.data.uniform_buffers_memory[image_index],
0,
size_of::<UniformBufferObject>() as u64,
vk::MemoryMapFlags::empty(),
)?;
memcpy(&ubo, memory.cast(), 1);
self.device.unmap_memory(self.data.uniform_buffers_memory[image_index]);以这种方式使用 UBO 并不是将频繁变化的值传递给着色器的最有效的方法。要将少量数据传递给着色器,更有效的方法是使用推送常量(push constants)。我们会在以后的章节中介绍它们。
如果你现在运行程序,你将会得到来自校验层的未绑定描述符集合的错误,并且什么都不会被渲染。在下一章中我们将会看到这些描述符集合,它们将会将 vk::Buffer 绑定到 uniform 缓冲描述符,这样着色器就可以访问这些变换数据,然后我们的程序就可以正常运行了。
描述符池与描述符集合
原文链接:https://kylemayes.github.io/vulkanalia/uniform/descriptor_pool_and_sets.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
上一章提到的描述符集合布局描述了可以绑定的描述符的类型。在本章中,我们将为每个 vk::Buffer 资源创建一个描述符集合,以将其绑定到 uniform 缓冲描述符。
描述符池
描述符集合不能被直接创建,而是像指令缓冲一样必须从池中分配。类比指令池之于指令缓冲,描述符集合的等效物不出所料地被称为描述符池。我们将编写一个新的函数 create_descriptor_pool 来设置它。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_uniform_buffers(&instance, &device, &mut data)?;
create_descriptor_pool(&device, &mut data)?;
// ...
}
}
unsafe fn create_descriptor_pool(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}首先我们需要使用 vk::DescriptorPoolSize 结构描述我们的描述符集合将包含哪些描述符类型以及它们的数量。
let ubo_size = vk::DescriptorPoolSize::builder()
.type_(vk::DescriptorType::UNIFORM_BUFFER)
.descriptor_count(data.swapchain_images.len() as u32);我们会为每一帧分配一个这样的描述符。包含了最大描述符集合数量信息的 vk::DescriptorPoolSize 结构会被主要的 vk::DescriptorPoolCreateInfo 引用:
let pool_sizes = &[ubo_size];
let info = vk::DescriptorPoolCreateInfo::builder()
.pool_sizes(pool_sizes)
.max_sets(data.swapchain_images.len() as u32);类似于指令池,这个结构有一个的可选标志 vk::DescriptorPoolCreateFlags::FREE_DESCRIPTOR_SET,用于确定是否可以释放单个描述符集合。我们在创建描述符集合后不会再修改它,所以我们不需要这个标志。
struct AppData {
// ...
uniform_buffers: Vec<vk::Buffer>,
uniform_buffers_memory: Vec<vk::DeviceMemory>,
descriptor_pool: vk::DescriptorPool,
// ...
}在 AppData 中添加一个新的字段来存储描述符池的句柄,并调用 create_descriptor_pool 来创建它。
data.descriptor_pool = device.create_descriptor_pool(&info, None)?;当重建交换链时,应该销毁描述符池,因为它取决于图像的数量:
unsafe fn destroy_swapchain(&mut self) {
self.device.destroy_descriptor_pool(self.data.descriptor_pool, None);
// ...
}并且在 App::recreate_swapchain 中重新创建描述符池:
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
// ...
create_uniform_buffers(&self.instance, &self.device, &mut self.data)?;
create_descriptor_pool(&self.device, &mut self.data)?;
// ...
}描述符集合
现在我们可以分配描述符集合本身了。添加一个 create_descriptor_sets 函数:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_descriptor_pool(&device, &mut data)?;
create_descriptor_sets(&device, &mut data)?;
// ...
}
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
// ..
create_descriptor_pool(&self.device, &mut self.data)?;
create_descriptor_sets(&self.device, &mut self.data)?;
// ..
}
}
unsafe fn create_descriptor_sets(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}描述符集合分配使用 vk::DescriptorSetAllocateInfo 结构描述。你需要指定要分配的描述符池,以及描述符集合布局的数组,该数组描述了要分配的每个描述符集合:
let layouts = vec![data.descriptor_set_layout; data.swapchain_images.len()];
let info = vk::DescriptorSetAllocateInfo::builder()
.descriptor_pool(data.descriptor_pool)
.set_layouts(&layouts);在我们的例子中,我们将为每个交换链图像创建一个描述符集合,所有的描述符集合都具有相同的布局。不幸的是,我们只能把描述符集合布局复制多次,因为 set_layouts 字段需要一个与描述符集合数量相匹配的数组。
在 AppData 中添加一个字段来保存描述符集合的句柄:
struct AppData {
// ...
descriptor_pool: vk::DescriptorPool,
descriptor_sets: Vec<vk::DescriptorSet>,
// ...
}并使用 allocate_descriptor_sets 分配它们:
data.descriptor_sets = device.allocate_descriptor_sets(&info)?;你不需要显式地清理描述符集合,因为当描述符池被销毁时,它们将自动释放。调用 allocate_descriptor_sets 将分配描述符集合,每个集合都有一个 uniform 缓冲描述符。
现在已经分配了描述符集合,但是其中的描述符仍然需要配置。我们现在将添加一个循环来填充每个描述符:
for i in 0..data.swapchain_images.len() {
}指向缓冲的描述符 —— 例如我们的 uniform 缓冲描述符 —— 使用 vk::DescriptorBufferInfo 结构进行配置。该结构指定了缓冲以及其中包含描述符数据的区域。
for i in 0..data.swapchain_images.len() {
let info = vk::DescriptorBufferInfo::builder()
.buffer(data.uniform_buffers[i])
.offset(0)
.range(size_of::<UniformBufferObject>() as u64);
}如果你要覆盖整个缓冲,就像我们在这个例子中一样,你也可以使用 vk::WHOLE_SIZE 值来表示范围。描述符的配置使用 update_descriptor_sets 函数进行更新,该函数以 vk::WriteDescriptorSet 结构的数组作为参数。
let buffer_info = &[info];
let ubo_write = vk::WriteDescriptorSet::builder()
.dst_set(data.descriptor_sets[i])
.dst_binding(0)
.dst_array_element(0)
// continued...前两个字段指定了要更新的描述符集合和绑定。我们给 uniform 缓冲绑定索引 0。请记住,描述符可以是数组,因此我们还需要用 dst_array_element 字段指定要更新的数组中的第一个索引。我们没有使用数组,所以索引是 0。
.descriptor_type(vk::DescriptorType::UNIFORM_BUFFER)我们需要再次指定描述符的类型。
.buffer_info(buffer_info);最后一个字段引用了一个数组,其中包含 descriptor_count 个实际配置描述符的结构体。取决于描述符的类型,你需要使用以下三个字段之一:buffer_info 字段用于指向缓冲数据的描述符,image_info 用于指向图像数据的描述符,texel_buffer_view 用于指向缓冲视图的描述符。我们的描述符基于缓冲,所以我们使用 buffer_info。
device.update_descriptor_sets(&[ubo_write], &[] as &[vk::CopyDescriptorSet]);使用 update_descriptor_sets 应用更新。它接受两种类型的数组作为参数:vk::WriteDescriptorSet 数组和 vk::CopyDescriptorSet 数组。后者可以用来将描述符复制到彼此,正如它的名字所暗示的那样。
使用描述符集合
现在我们需要更新 create_command_buffers 函数,使用 cmd_bind_descriptor_sets 来将每个与交换链图像对应的描述符集合绑定到着色器中的描述符上。这需要在 cmd_draw_indexed 调用之前完成:
device.cmd_bind_descriptor_sets(
*command_buffer,
vk::PipelineBindPoint::GRAPHICS,
data.pipeline_layout,
0,
&[data.descriptor_sets[i]],
&[],
);
device.cmd_draw_indexed(*command_buffer, INDICES.len() as u32, 1, 0, 0, 0);不同于顶点和索引缓冲的是,描述符集合并不是专为图形管线而设的。因此我们需要指定我们想要将描述符集合绑定到图形管线还是计算管线。下一个参数是描述符基于的管线布局。接下来的两个参数指定了第一个描述符集合的索引和要绑定的集合数组。我们稍后会回到这个问题。最后一个参数指定了用于动态描述符的偏移量数组。我们将在后面的章节中看到这些。
如果你现在运行程序,那么很不幸,你看不到任何东西。问题在于我们在投影矩阵中翻转了 Y 坐标,现在顶点是按逆时针顺序而不是顺时针顺序绘制的。这导致背面剔除生效,并阻止任何几何图形被绘制。进入 create_pipeline 函数并修改 vk::PipelineRasterizationStateCreateInfo 中的 front_face 以纠正这个问题:
.cull_mode(vk::CullModeFlags::BACK)
.front_face(vk::FrontFace::COUNTER_CLOCKWISE)再次运行程序,你应该能看到以下内容:

矩形变成了方形,因为投影矩阵现在纠正了宽高比。App::update_uniform_buffer 方法负责屏幕调整大小,所以我们不需要在 App::recreate_swapchain 中重新创建描述符集合。
对齐要求
到目前为止,我们忽略了一个问题,那就是 Rust 结构中的数据应该如何与着色器中的 uniform 定义匹配。在两者中使用相同的类型似乎是显而易见的:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct UniformBufferObject {
model: Mat4,
view: Mat4,
proj: Mat4,
}layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;
然而这不只是全部。例如,试试看像这样修改结构和着色器:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct UniformBufferObject {
foo: Vec2,
model: Mat4,
view: Mat4,
proj: Mat4,
}layout(binding = 0) uniform UniformBufferObject {
vec2 foo;
mat4 model;
mat4 view;
mat4 proj;
} ubo;
重新编译你的着色器和程序并运行它,你会发现五颜六色的正方形消失了!这是因为我们没有考虑到对齐要求(alignment requirements)。
Vulkan 希望你的结构中的数据在内存中以特定的方式对齐,例如:
- 标量必须以 N (= 4 字节,给定 32 位浮点数) 对齐。
vec2必须以 2N (= 8 字节) 对齐。vec3或vec4必须以 4N (= 16 字节) 对齐。- 嵌套结构必须以其成员的基本对齐方式对齐,向上舍入为 16 的倍数。
mat4矩阵必须与vec4具有相同的对齐方式。
你可以在规范中找到完整的对齐要求列表。
我们原先的着色器只有三个 mat4 字段,已经满足了对齐要求。由于每个 mat4 的大小为 4 x 4 x 4 = 64 字节,model 的偏移量为 0,view 的偏移量为 64,proj 的偏移量为 128。所有这些都是 16 的倍数,这就是为什么它碰巧能正常工作。
而新的结构则以 vec2 开头,而 vec2 只有 8 字节大小,因此后面所有的偏移量都会被打乱。现在 model 的偏移量为 8,view 的偏移量为 72,proj 的偏移量为 136,它们都不是 16 的倍数。不幸的是,Rust 对于控制结构体字段的对齐方式没有很好的支持,但是我们可以手动填充来修复对齐问题:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct UniformBufferObject {
foo: Vec2,
_padding: [u8; 8],
model: Mat4,
view: Mat4,
proj: Mat4,
}如果你现在重新编译并再次运行程序,你应该会看到着色器再次正确地接收到矩阵值。
多个描述符集合
正如一些结构和函数调用所暗示的那样,实际上可以同时绑定多个描述符集合。在创建管线布局时,你需要为每个描述符集合指定一个描述符集合布局。然后着色器可以像这样引用特定的描述符集合:
layout(set = 0, binding = 0) uniform UniformBufferObject { ... }
你可以利用这个特性,将每个对象都不同的描述符和在对象之间共享的描述符分别放入不同的描述符集合中。在这种情况下,你可以避免在绘制调用之间重新绑定大多数描述符,这可能更有效率。
图像
原文链接:https://kylemayes.github.io/vulkanalia/texture/images.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
我们已经使用了逐顶点颜色来为几何体上色,但这是一种相当受限的方法。在本章教程中,我们将实现纹理映射(texture mapping)来让几何体看上去更有趣。这也使得我们可以在后续的章节中加载并绘制出基础的 3D 模型。
向我们的应用添加纹理需要以下步骤:
- 创建一个设备内存中的图像对象
- 从图像文件向其中填充像素
- 创建一个图像采样器
- 添加一个组合图像采样器描述符,用来从纹理中采样颜色
之前我们已经处理过图像对象了,但那些是由交换链扩展自动创建的。这次我们将自己创建一个图像对象。创建一个图像并向其中填充数据的过程与创建顶点缓冲类似:我们先创建一个暂存缓冲并向它填充像素数据,然后再将这些数据复制到最终用来渲染的图像对象中。直接创建一个暂存图像也可以,但 Vulkan 允许直接从 vk::Buffer 复制像素到图像中,而且这样做实际上在某些硬件上更快。我们首先创建一个暂存缓冲并用像素值填充它,然后我们创建一个图像,并将像素复制到其中。创建图像与创建缓冲并没有太大的区别。它涉及到查询内存需求、分配设备内存并绑定,就像我们以前看到的那样。
然而,当使用图像时,我们还需要注意一些额外的事情。图像可以有不同的布局,布局会影响像素在内存中的组织方式。受限于图形硬件的工作方式,简单地按行存储像素可能无法带来最佳性能。当对图像执行任何操作时,你必须确保它们具有最适合在该操作中使用的布局。我们其实在指定渲染流程时已经见到了其中一些布局:
vk::ImageLayout::PRESENT_SRC_KHR– 最适合用作呈现的布局vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL– 最适合用作从片元着色器写入颜色的附件的布局vk::ImageLayout::TRANSFER_SRC_OPTIMAL– 最适合用作cmd_copy_image_to_buffer这类传输操作的数据源的布局vk::ImageLayout::TRANSFER_DST_OPTIMAL– 最适合用作cmd_copy_buffer_to_image这类传输操作的目标的布局vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL– 最适合用于从一个着色器中采样的布局
转换图像布局最常见的方法之一是使用管线屏障(pipeline barrier)。管线屏障主要用于同步对资源的访问,例如确保图像在读取之前已经被写入。但管线屏障也可以用于转换布局。在本章中,我们将看到管线屏障是如何用于转换布局的。此外,当使用 vk::SharingMode::EXCLUSIVE 时,屏障还可以用于在队列族之间传递图像的所有权。
图像库
能用来加载图像的库有很多,你甚至可以自己编写代码来加载 BMP 和 PPM 等简单格式。在本教程中,我们将使用 png crate,你应该已经将它添加到程序的依赖中了。
加载图像
我们需要打开图像文件。添加以下导入:
use std::fs::File;创建一个新函数 create_texture_image,我们将用它加载图像并将其上传到一个 Vulkan 图像对象中。我们要使用指令缓冲,所以它应该在 create_command_pool 之后调用。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_command_pool(&instance, &device, &mut data)?;
create_texture_image(&instance, &device, &mut data)?;
// ...
}
}
unsafe fn create_texture_image(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}创建一个与 shaders 目录同一级的新目录 resources 用来存放纹理图像。我们将从该目录加载一个名为 texture.png 的图像。我选择使用下面这张 以 CC0 协议发布的图像,并将其调整到 512 x 512 像素大小,你也可以随意选择任何你想使用的(带有 alpha 通道的)PNG 图像。

使用这个库加载图像非常简单:
unsafe fn create_texture_image(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let image = File::open("resources/texture.png")?;
let decoder = png::Decoder::new(image);
let mut reader = decoder.read_info()?;
let mut pixels = vec![0; reader.info().raw_bytes()];
reader.next_frame(&mut pixels)?;
let size = reader.info().raw_bytes() as u64;
let (width, height) = reader.info().size();
Ok(())
}这段代码将用每像素 4 个字节的数据填充 pixels 列表,总共将会有 width * height * 4 个值。注意 png crate 目前还不支持将 RGB 图像转换为 RGBA 图像,并且后续代码将假设像素数据拥有 alpha 通道。因此,你需要确保使用带有 alpha 通道的 PNG 图像(例如上面的图像)。
暂存缓冲
现在我们将在主机可见的内存中创建一个缓冲,以便我们使用 map_memory 并将像素复制到其中。缓冲应该在主机可见的内存中,这样我们可以将其映射。它还应该能被用作传输源,以便我们稍后能将其复制到图像中:
let (staging_buffer, staging_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::TRANSFER_SRC,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
)?;然后,我们可以直接将从图像加载库中获取的像素值复制到缓冲中:
let memory = device.map_memory(
staging_buffer_memory,
0,
size,
vk::MemoryMapFlags::empty(),
)?;
memcpy(pixels.as_ptr(), memory.cast(), pixels.len());
device.unmap_memory(staging_buffer_memory);纹理图像
尽管我们可以让着色器直接访问缓冲中的像素值,但最好还是使用 Vulkan 中的图像对象来实现这一目标。使用图像对象,我们能够使用 2D 坐标更轻松、更快速地检索颜色。图像对象中的像素称为纹素(texel),我们从现在开始使用这个名字。将下列新的字段添加到 AppData 中:
struct AppData {
// ...
texture_image: vk::Image,
texture_image_memory: vk::DeviceMemory,
}图像的参数在 vk::ImageCreateInfo 结构体中指定:
let info = vk::ImageCreateInfo::builder()
.image_type(vk::ImageType::_2D)
.extent(vk::Extent3D { width, height, depth: 1 })
.mip_levels(1)
.array_layers(1)
// continued...在 image_type 字段中指定的图像类型会告诉 Vulkan 图像中的纹素将使用什么样的坐标系来寻址。我们可以创建 1D、2D 和 3D 图像。一维图像可以用来存储数据或渐变;二维图像主要用于纹理;三维图像可以用来存储体素(voxel)体积。extent 字段指定了图像的尺寸,也就是每个坐标轴上有多少个纹素。这就是为什么 depth 必须是 1 而不是 0。我们的纹理不会是一个数组,并且我们现在也不会使用多级渐远。
.format(vk::Format::R8G8B8A8_SRGB)Vulkan 支持许多图像格式,但我们应该为纹素使用与缓冲中的像素相同的格式,否则复制操作将会失败。
.tiling(vk::ImageTiling::OPTIMAL)tiling 字段可以从以下两个值中选择:
vk::ImageTiling::LINEAR– 纹素按行主序排列,和我们的pixels数组一样vk::ImageTiling::OPTIMAL– 纹素按实现定义的最佳访问顺序排列
与图像的布局不同,平铺(tiling)模式无法在之后更改。如果你想要能直接访问图像内存中的纹素,那么你必须使用 vk::ImageTiling::LINEAR。我们不需要这样,因为我们会使用暂存缓冲而不是暂存图像。我们将使用 vk::ImageTiling::OPTIMAL 来实现着色器的高效访问。
.initial_layout(vk::ImageLayout::UNDEFINED)图像的 initial_layout 只有两个可能的值:
vk::ImageLayout::UNDEFINED– 不可被 GPU 使用,第一次转换将会丢弃纹素。vk::ImageLayout::PREINITIALIZED– 不可被 GPU 使用,但第一次转换将会保留纹素。
在少数情况下,第一次转换时需要保留纹素。例如,如果你将某个具有 vk::ImageTiling::LINEAR 平铺模式的图像用作暂存图像,你需要将纹素数据上传到其中,然后将图像转换为传输源 —— 这个过程中不能丢失数据。然而,在我们的例子中,我们是图像转换为传输目标,然后再从缓冲对象中将纹素数据复制到其中,所以我们不需要这个特性,可以安全地使用 vk::ImageLayout::UNDEFINED。
.usage(vk::ImageUsageFlags::SAMPLED | vk::ImageUsageFlags::TRANSFER_DST)usage 字段的语义与缓冲创建时的语义相同。图像将被用作缓冲复制的目标,因此它应该被设置为传输目标。我们还希望能够从着色器中访问图像来给网格上色,所以 usage 也应该需要 vk::ImageUsageFlags::SAMPLED。
.sharing_mode(vk::SharingMode::EXCLUSIVE)图像只会被一个队列族使用,即支持图形操作(因此也支持传输)的队列族。
.samples(vk::SampleCountFlags::_1)samples 标志与多重采样有关。这只与用作附件的图像有关,所以我们只需要一个采样。
.flags(vk::ImageCreateFlags::empty()); // Optional.在图像上还有一些可选的标志,允许控制诸如稀疏图像(sparse image)之类的更高级属性。稀疏图像是只有某些区域储存在内存中的图像。例如,如果你使用一个 3D 纹理来存储体素地形,那么你可以使用稀疏图像来避免分配内存来存储大量的“空气”值。我们在本教程中不会使用它,所以你可以省略这个字段的生成器方法,这将把它设置为默认值(一个空的标志集)。
data.texture_image = device.create_image(&info, None)?;图像使用 create_image 创建,没有任何特别值得注意的参数。图形硬件可能不支持 vk::Format::R8G8B8A8_SRGB 格式,这时你需要有一系列可用的替代格式,并选择其中能被支持的最好的一个。然而,这个格式的支持十分广泛,我们将跳过这一步。使用不同的格式也需要烦人的转换。我们将在深度缓冲章节中回过头来实现这样的一个系统。
let requirements = device.get_image_memory_requirements(data.texture_image);
let info = vk::MemoryAllocateInfo::builder()
.allocation_size(requirements.size)
.memory_type_index(get_memory_type_index(
instance,
data,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
requirements,
)?);
data.texture_image_memory = device.allocate_memory(&info, None)?;
device.bind_image_memory(data.texture_image, data.texture_image_memory, 0)?;给图像分配内存的方式与给缓冲分配内存的方式完全相同,除了需要使用 get_image_memory_requirements 而不是 get_buffer_memory_requirements,使用 bind_image_memory 而不是 bind_buffer_memory。
这个函数已经变得相当长了,并且在后面的章节中还需要创建更多的图像,所以我们应该为图像创建抽象出一个 create_image 函数,和缓冲一样。创建这个函数并将图像对象的创建和内存分配移入其中:
unsafe fn create_image(
instance: &Instance,
device: &Device,
data: &AppData,
width: u32,
height: u32,
format: vk::Format,
tiling: vk::ImageTiling,
usage: vk::ImageUsageFlags,
properties: vk::MemoryPropertyFlags,
) -> Result<(vk::Image, vk::DeviceMemory)> {
let info = vk::ImageCreateInfo::builder()
.image_type(vk::ImageType::_2D)
.extent(vk::Extent3D {
width,
height,
depth: 1,
})
.mip_levels(1)
.array_layers(1)
.format(format)
.tiling(tiling)
.initial_layout(vk::ImageLayout::UNDEFINED)
.usage(usage)
.samples(vk::SampleCountFlags::_1)
.sharing_mode(vk::SharingMode::EXCLUSIVE);
let image = device.create_image(&info, None)?;
let requirements = device.get_image_memory_requirements(image);
let info = vk::MemoryAllocateInfo::builder()
.allocation_size(requirements.size)
.memory_type_index(get_memory_type_index(
instance,
data,
properties,
requirements,
)?);
let image_memory = device.allocate_memory(&info, None)?;
device.bind_image_memory(image, image_memory, 0)?;
Ok((image, image_memory))
}我把宽度、高度、格式、平铺模式、用途和内存属性变成了参数,因为这些都将在不同图像之间变化。
create_texture_image 函数现在可以简化为:
unsafe fn create_texture_image(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let image = File::open("resources/texture.png")?;
let decoder = png::Decoder::new(image);
let mut reader = decoder.read_info()?;
let mut pixels = vec![0; reader.info().raw_bytes()];
reader.next_frame(&mut pixels)?;
let size = reader.info().raw_bytes() as u64;
let (width, height) = reader.info().size();
let (staging_buffer, staging_buffer_memory) = create_buffer(
instance,
device,
data,
size,
vk::BufferUsageFlags::TRANSFER_SRC,
vk::MemoryPropertyFlags::HOST_COHERENT | vk::MemoryPropertyFlags::HOST_VISIBLE,
)?;
let memory = device.map_memory(
staging_buffer_memory,
0,
size,
vk::MemoryMapFlags::empty(),
)?;
memcpy(pixels.as_ptr(), memory.cast(), pixels.len());
device.unmap_memory(staging_buffer_memory);
let (texture_image, texture_image_memory) = create_image(
instance,
device,
data,
width,
height,
vk::Format::R8G8B8A8_SRGB,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::SAMPLED | vk::ImageUsageFlags::TRANSFER_DST,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
data.texture_image = texture_image;
data.texture_image_memory = texture_image_memory;
Ok(())
}布局转换
我们现在要写的函数再次涉及到记录和执行指令缓冲,所以现在是将这些逻辑移入几个辅助函数的好时机:
unsafe fn begin_single_time_commands(
device: &Device,
data: &AppData,
) -> Result<vk::CommandBuffer> {
let info = vk::CommandBufferAllocateInfo::builder()
.level(vk::CommandBufferLevel::PRIMARY)
.command_pool(data.command_pool)
.command_buffer_count(1);
let command_buffer = device.allocate_command_buffers(&info)?[0];
let info = vk::CommandBufferBeginInfo::builder()
.flags(vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT);
device.begin_command_buffer(command_buffer, &info)?;
Ok(command_buffer)
}
unsafe fn end_single_time_commands(
device: &Device,
data: &AppData,
command_buffer: vk::CommandBuffer,
) -> Result<()> {
device.end_command_buffer(command_buffer)?;
let command_buffers = &[command_buffer];
let info = vk::SubmitInfo::builder()
.command_buffers(command_buffers);
device.queue_submit(data.graphics_queue, &[info], vk::Fence::null())?;
device.queue_wait_idle(data.graphics_queue)?;
device.free_command_buffers(data.command_pool, &[command_buffer]);
Ok(())
}这些函数抽取自 copy_buffer 中原有的代码。你现在可以将 copy_buffer 函数简化为:
unsafe fn copy_buffer(
device: &Device,
data: &AppData,
source: vk::Buffer,
destination: vk::Buffer,
size: vk::DeviceSize,
) -> Result<()> {
let command_buffer = begin_single_time_commands(device, data)?;
let regions = vk::BufferCopy::builder().size(size);
device.cmd_copy_buffer(command_buffer, source, destination, &[regions]);
end_single_time_commands(device, data, command_buffer)?;
Ok(())
}现在我们要调用函数 cmd_copy_buffer_to_image 来记录将像素从暂存缓冲复制到图像中的指令,但这个指令首先要求图像处于正确的布局。创建一个新函数来处理布局转换:
unsafe fn transition_image_layout(
device: &Device,
data: &AppData,
image: vk::Image,
format: vk::Format,
old_layout: vk::ImageLayout,
new_layout: vk::ImageLayout,
) -> Result<()> {
let command_buffer = begin_single_time_commands(device, data)?;
end_single_time_commands(device, data, command_buffer)?;
Ok(())
}转换布局最常用的方法之一是使用图像内存屏障(image memory barrier)。这样的管线屏障通常用于同步对资源的访问,例如确保对缓冲的写入在读取之前完成,但它也可以用于转换图像布局,以及在使用 vk::SharingMode::EXCLUSIVE 时在队列族之间传递图像对象的所有权。对于缓冲,有一个等效的缓冲内存屏障(buffer memory barrier)。
let barrier = vk::ImageMemoryBarrier::builder()
.old_layout(old_layout)
.new_layout(new_layout)
// continued...前两个字段指定了布局转换。如果你不关心图像中现有的内容,那么可以使用 vk::ImageLayout::UNDEFINED 作为 old_layout。
.src_queue_family_index(vk::QUEUE_FAMILY_IGNORED)
.dst_queue_family_index(vk::QUEUE_FAMILY_IGNORED)如果你使用屏障来在队列族之间传输图像对象的所有权,那么这两个字段应该是队列族的索引。如果你不想这样做,那么它们必须被显式设置为 vk::QUEUE_FAMILY_IGNORED(不是默认值!)。
.image(image)
.subresource_range(subresource)image 和 subresource_range 指定了受影响的图像和图像中的特定部分。我们需要在定义图像内存屏障之前定义 subresource:
let subresource = vk::ImageSubresourceRange::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.base_mip_level(0)
.level_count(1)
.base_array_layer(0)
.layer_count(1);我们的图像不是一个数组,也没有多级渐远层级,所以只指定了一个多级渐远层级和数组层。
.src_access_mask(vk::AccessFlags::empty()) // TODO
.dst_access_mask(vk::AccessFlags::empty()); // TODO屏障主要用于同步,所以你必须指定哪些涉及资源的操作类型需要在屏障之前发生,以及哪些涉及资源的操作需要在屏障处等待。尽管我们已经使用 queue_wait_idle 来手动同步,但我们仍然需要这样做。这些值取决于旧布局和新布局,所以我们会在弄清楚要使用哪些转换之后再回到这里。
device.cmd_pipeline_barrier(
command_buffer,
vk::PipelineStageFlags::empty(), // TODO
vk::PipelineStageFlags::empty(), // TODO
vk::DependencyFlags::empty(),
&[] as &[vk::MemoryBarrier],
&[] as &[vk::BufferMemoryBarrier],
&[barrier],
);所有类型的管线屏障都使用相同的函数提交。指令缓冲之后的第一个参数指定了在屏障之前应该发生的操作所在的管线阶段。第二个参数指定了在屏障处等待的操作所在的管线阶段。在屏障之前和之后允许指定的管线阶段取决于在屏障之前和之后如何使用资源。允许的值在 Vulkan 规范的这个表格中列出。例如,如果你想在屏障之后读取一个 uniform,你应该指定一个 vk::AccessFlags::UNIFORM_READ 的用途和最早从 uniform 中读取的着色器作为管线阶段,比如 vk::PipelineStageFlags::FRAGMENT_SHADER。对于这类用途,指定非着色器管线阶段是没有意义的。校验层会在你指定与用途类型不匹配的管线阶段时发出警告。
第四个参数是一个空的 vk::DependencyFlags 集合或 vk::DependencyFlags::BY_REGION。后者将屏障变成每个区域的条件。举例来说,这意味着你可以从在此之前已经写入的资源的部分开始读取。
最后三个参数引用了三种可用类型的管线屏障的切片:内存屏障、缓冲内存屏障以及我们这里使用的图像内存屏障。注意,我们目前还没有使用 vk::Format 参数,但我们将在深度缓冲章节中使用它来进行特殊的转换。
复制缓冲至图像
在我们回到 create_texture_image 之前,我们还要写另一个辅助函数 copy_buffer_to_image:
unsafe fn copy_buffer_to_image(
device: &Device,
data: &AppData,
buffer: vk::Buffer,
image: vk::Image,
width: u32,
height: u32,
) -> Result<()> {
let command_buffer = begin_single_time_commands(device, data)?;
end_single_time_commands(device, data, command_buffer)?;
Ok(())
}正如缓冲复制一样,你需要指定缓冲的哪一部分将被复制到图像的哪一部分。这是通过 vk::BufferImageCopy 结构体来完成的:
let subresource = vk::ImageSubresourceLayers::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.mip_level(0)
.base_array_layer(0)
.layer_count(1);
let region = vk::BufferImageCopy::builder()
.buffer_offset(0)
.buffer_row_length(0)
.buffer_image_height(0)
.image_subresource(subresource)
.image_offset(vk::Offset3D { x: 0, y: 0, z: 0 })
.image_extent(vk::Extent3D { width, height, depth: 1 });这里的大部分字段无需解释。buffer_offset 指定了缓冲中像素值开始的字节偏移量。buffer_row_length 和 buffer_image_height 字段指定了像素在内存中的布局。例如,你可以在图像的行之间有一些填充字节。对于这两个字段都指定 0 表示像素就像我们现在这样紧密地排列。image_subresource、image_offset 和 image_extent 字段指示我们要将像素复制到图像的哪个部分。
使用 cmd_copy_buffer_to_image 函数将从缓冲到图像的复制操作加入队列:
device.cmd_copy_buffer_to_image(
command_buffer,
buffer,
image,
vk::ImageLayout::TRANSFER_DST_OPTIMAL,
&[region],
);第四个参数表示图像当前使用哪一种布局。我在这里假设图像已经转换为最适合复制像素的布局。现在我们只复制一段像素到整个图像,但也可以指定一个 vk::BufferImageCopy 数组来在一次操作中将这个缓冲的多个不同拷贝复制到图像中。
准备纹理图像
我们现在已经拥有了完成纹理图像所需的所有工具,所以我们要回到 create_texture_image 函数。我们先前在那里做的最后一件事是创建纹理图像。下一步是将暂存缓冲复制到纹理图像。这涉及到两个步骤:
- 转换纹理图像为
vk::ImageLayout::TRANSFER_DST_OPTIMAL - 执行从缓冲到图像的复制操作
这可以用我们刚刚创建的函数轻易完成:
transition_image_layout(
device,
data,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
vk::ImageLayout::UNDEFINED,
vk::ImageLayout::TRANSFER_DST_OPTIMAL,
)?;
copy_buffer_to_image(
device,
data,
staging_buffer,
data.texture_image,
width,
height,
)?;图像是使用 vk::ImageLayout::UNDEFINED 布局创建的,所以在转换 texture_image 时将它指定为旧布局。请记住,我们可以这样做是因为在执行复制操作之前我们不关心它的内容。
为了能够开始从着色器中采样纹理图像,我们需要最后一个转换以供着色器访问:
transition_image_layout(
device,
data,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
vk::ImageLayout::TRANSFER_DST_OPTIMAL,
vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL,
)?;转换屏障掩码
如果你现在启用校验层并运行你的应用程序,那么你会看到它警告 transition_image_layout 中的访问掩码和管线阶段无效。我们仍然需要根据转换中的布局来设置它们。
我们需要处理两个转换:
- 未定义 → 传输目标 – 不需要等待任何东西的传输写入
- 传输目标 → 着色器读取 – 着色器读取应该等待传输写入,特别是片段着色器中的着色器读取,因为我们会在那里使用纹理
这些规则可以使用以下访问掩码和管线阶段来指定,它们应该被加在 transition_image_layout 的开头:
let (
src_access_mask,
dst_access_mask,
src_stage_mask,
dst_stage_mask,
) = match (old_layout, new_layout) {
(vk::ImageLayout::UNDEFINED, vk::ImageLayout::TRANSFER_DST_OPTIMAL) => (
vk::AccessFlags::empty(),
vk::AccessFlags::TRANSFER_WRITE,
vk::PipelineStageFlags::TOP_OF_PIPE,
vk::PipelineStageFlags::TRANSFER,
),
(vk::ImageLayout::TRANSFER_DST_OPTIMAL, vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL) => (
vk::AccessFlags::TRANSFER_WRITE,
vk::AccessFlags::SHADER_READ,
vk::PipelineStageFlags::TRANSFER,
vk::PipelineStageFlags::FRAGMENT_SHADER,
),
_ => return Err(anyhow!("Unsupported image layout transition!")),
};然后使用访问标志和管线阶段掩码更新 vk::ImageMemoryBarrier 结构体和 cmd_pipeline_barrier 调用:
let barrier = vk::ImageMemoryBarrier::builder()
.old_layout(old_layout)
.new_layout(new_layout)
.src_queue_family_index(vk::QUEUE_FAMILY_IGNORED)
.dst_queue_family_index(vk::QUEUE_FAMILY_IGNORED)
.image(image)
.subresource_range(subresource)
.src_access_mask(src_access_mask)
.dst_access_mask(dst_access_mask);
device.cmd_pipeline_barrier(
command_buffer,
src_stage_mask,
dst_stage_mask,
vk::DependencyFlags::empty(),
&[] as &[vk::MemoryBarrier],
&[] as &[vk::BufferMemoryBarrier],
&[barrier],
);如你在之前提到的列表中所见,传输写入必须发生在管线传输阶段。由于写入不需要任何等待,你可以为屏障前操作指定空访问掩码与最早的管线阶段 vk::PipelineStageFlags::TOP_OF_PIPE。注意,vk::PipelineStageFlags::TRANSFER 不是一个在图形与计算管线中的真实阶段。它更像是一个传输操作发生的伪阶段。欲知更多详情与其它伪阶段的例子,请见文档。
图像将在相同的管线阶段被写入,然后在片段着色器中被读取。这就是为什么我们在片段着色器管线阶段指定了着色器读取访问。
如果我们将来需要做更多的转换,那么我们会扩展这个函数。现在,程序应该可以成功运行。当然,现在还不会有视觉上的变化。
有一件事需要注意,那就是提交指令缓冲在一开始时会导致隐式的 vk::AccessFlags::HOST_WRITE 同步。由于 transition_image_layout 函数执行的指令缓冲只有一个指令,如果你在布局转换中需要一个 vk::AccessFlags::HOST_WRITE 依赖,那么你可以使用这个隐式同步并将 src_access_mask 设置为 vk::AccessFlags::empty()。你可以选择是否要明确地指定它,但我个人不喜欢依赖这些类似 OpenGL 的“隐藏”操作。
实际上有一种特殊的图像布局类型 vk::ImageLayout::GENERAL,它支持所有操作。当然,它的问题也就是它不一定能为任何操作提供最佳性能。对于一些特殊情况它是必需的,比如将图像同时用作输入和输出,或者在它离开预初始化布局后读取图像。
到目前为止,所有提交指令的辅助函数都被设置为同步执行,因为它们会等待队列空闲。对于实际应用程序,建议将这些操作组合到一个单独的指令缓冲中,并异步执行以获得更高的吞吐量,对于在 create_texture_image 函数中的转换和复制更是如此。试试看通过创建 setup_command_buffer 来让辅助函数记录指令,并添加一个 flush_setup_commands 来执行到目前为止已经记录的指令。最好在纹理映射能正常运行之后这样做,以检查纹理资源是否仍然配置正确。
善后
在 create_texture_image 函数的最后将暂存缓冲及其内存清理掉:
device.destroy_buffer(staging_buffer, None);
device.free_memory(staging_buffer_memory, None);主要纹理图像将会一直使用到程序结束:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_image(self.data.texture_image, None);
self.device.free_memory(self.data.texture_image_memory, None);
// ...
}图像现在包含了纹理,但我们仍然需要一种方法来从图形管线中访问它。我们将在下一章中讨论这个问题。
图像视图与采样器
原文链接:https://kylemayes.github.io/vulkanalia/texture/image_view_and_sampler.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在本章中,我们将会创建两个新的图形管线中采样图像所必须的资源。第一个资源我们在之前使用交换链图像时已经见过了,但是第二个资源是全新的,它与着色器如何从图像中读取像素有关。
纹理图像视图
正如我们之前在交换链图像和帧缓冲中所见到的,图像不能直接访问,而是要通过图像视图来访问。我们也需要为纹理图像创建这样的图像视图。
在 AppData 中添加一个 vk::ImageView 字段来保存纹理图像的图像视图,并创建一个新的函数 create_texture_image_view 来创建它:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_texture_image(&instance, &device, &mut data)?;
create_texture_image_view(&device, &mut data)?;
// ...
}
}
struct AppData {
// ...
texture_image: vk::Image,
texture_image_memory: vk::DeviceMemory,
texture_image_view: vk::ImageView,
// ...
}
unsafe fn create_texture_image_view(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}这个函数的代码可以直接基于 create_swapchain_image_views。你只需要修改 format 和 image:
let subresource_range = vk::ImageSubresourceRange::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.base_mip_level(0)
.level_count(1)
.base_array_layer(0)
.layer_count(1);
let info = vk::ImageViewCreateInfo::builder()
.image(data.texture_image)
.view_type(vk::ImageViewType::_2D)
.format(vk::Format::R8G8B8A8_SRGB)
.subresource_range(subresource_range);我省略了显式的 components 初始化,因为 vk::ComponentSwizzle::IDENTITY 的值就是 0。通过调用 create_image_view 来完成图像视图的创建:
data.texture_image_view = device.create_image_view(&info, None)?;这里的很多逻辑都和 create_swapchain_image_views 重复了,你可能希望将这些逻辑抽出来,写成一个新的 create_image_view 函数:
unsafe fn create_image_view(
device: &Device,
image: vk::Image,
format: vk::Format,
) -> Result<vk::ImageView> {
let subresource_range = vk::ImageSubresourceRange::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.base_mip_level(0)
.level_count(1)
.base_array_layer(0)
.layer_count(1);
let info = vk::ImageViewCreateInfo::builder()
.image(image)
.view_type(vk::ImageViewType::_2D)
.format(format)
.subresource_range(subresource_range);
Ok(device.create_image_view(&info, None)?)
}有了这个函数,create_texture_image_view 函数就可以简化为:
unsafe fn create_texture_image_view(device: &Device, data: &mut AppData) -> Result<()> {
data.texture_image_view = create_image_view(
device,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
)?;
Ok(())
}而 create_swapchain_image_views 可以简化为:
unsafe fn create_swapchain_image_views(device: &Device, data: &mut AppData) -> Result<()> {
data.swapchain_image_views = data
.swapchain_images
.iter()
.map(|i| create_image_view(device, *i, data.swapchain_format))
.collect::<Result<Vec<_>, _>>()?;
Ok(())
}记得在程序结束时,在销毁图像之前销毁图像视图:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_image_view(self.data.texture_image_view, None);
// ...
}采样器(sampler)
着色器可以直接从图像中读取像素,但当图像被用作纹理时,这种做法并不常见。纹理通常是通过采样器访问的,采样器会应用过滤和变换来计算最终的颜色。
这些过滤器有助于解决采样过密(oversampling)的问题。考虑一个纹理,它被映射到的几何体的片段数比纹素数多。如果你只是简单地为每个片段的纹理坐标取最近的纹素,那么你会得到如下第一张图像的结果:

如果你用线性插值结合了最近的 4 个纹素,那么你会得到一个更平滑的结果,如右图所示。当然,左图可能更适合你的应用程序的艺术风格要求(想想 Minecraft),但是在传统的图形应用程序中,右图更受欢迎。当从纹理中读取颜色时,采样器对象会自动为你应用这种过滤。
而当纹素数量多于片段时,就会出现采样过疏(undersampling)的问题。当以锐角采样棋盘纹理这样的高频图案时,就会出现伪影:

在左图中,纹理在远处变成了一团模糊的东西。解决这个问题的方法是各向异性过滤,采样器也可以自动应用它。
除了这些过滤器之外,采样器还可以处理变换。它决定了当你尝试通过其*寻址模式(addressing mode)*读取图像外的纹素时会发生什么。下面的图像展示了一些可能性:

现在我们创建一个 create_texture_sampler 函数来设置一个这样的采样器对象。之后我们会在着色器中使用这个采样器来从纹理中读取颜色。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_texture_image(&instance, &device, &mut data)?;
create_texture_image_view(&device, &mut data)?;
create_texture_sampler(&device, &mut data)?;
// ...
}
}
unsafe fn create_texture_sampler(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}采样器是通过 vk::SamplerCreateInfo 结构进行配置的,它指定了它应该应用的所有过滤器和变换。
let info = vk::SamplerCreateInfo::builder()
.mag_filter(vk::Filter::LINEAR)
.min_filter(vk::Filter::LINEAR)
// continued...mag_filter 和 min_filter 字段指定了如何插值放大或缩小的纹素。放大涉及上面描述的采样过密问题,而缩小涉及到采样过疏。选项有 vk::Filter::NEAREST 和 vk::Filter::LINEAR,分别对应上面图像中演示的模式。
.mipmap_mode(vk::SamplerMipmapMode::LINEAR) .address_mode_u(vk::SamplerAddressMode::REPEAT)
.address_mode_v(vk::SamplerAddressMode::REPEAT)
.address_mode_w(vk::SamplerAddressMode::REPEAT)寻址模式可以使用 address_mode 字段按轴指定。可用的值如下所示。上面的图像演示了其中的大多数。请注意,这些轴被称为 U、V 和 W,而不是 X、Y 和 Z。这是纹理空间坐标的约定。
vk::SamplerAddressMode::REPEAT– 超出图像尺寸时重复纹理。vk::SamplerAddressMode::MIRRORED_REPEAT– 类似于重复,但是在超出尺寸时反转坐标以镜像图像。vk::SamplerAddressMode::CLAMP_TO_EDGE– 超出图像尺寸时取最接近坐标的边缘的颜色。vk::SamplerAddressMode::MIRROR_CLAMP_TO_EDGE– 类似于 clamp to edge,但是使用与最接近边缘相反的边缘。vk::SamplerAddressMode::CLAMP_TO_BORDER– 超出图像尺寸时返回一个纯色。
这里我们用什么寻址模式都无所谓,因为在本教程中我们不会采样到图像外面。不过,重复模式可能是最常见的模式,因为它可以被用来在绘制像地板和墙壁这样的物体时平铺纹理。
.anisotropy_enable(true)
.max_anisotropy(16.0)如果要使用各向异性过滤,我们需要指定两个字段。除非遇到了性能问题,不然没理由不启用各向异性过滤。max_anisotropy 字段限制了用于计算最终颜色的纹素样本的数量。将其设为较低的值能带来更好的性能,但也会降低渲染的质量。目前没有任何图形硬件会使用超过 16 个样本,因为就算使用了超过这个数量的样本,带来的视觉提升也可以忽略。
.border_color(vk::BorderColor::INT_OPAQUE_BLACK)border_color 字段指定了在使用 clamp to border 寻址模式时,采样超出图像范围时返回的颜色。可以返回黑色、白色或透明色,可以是浮点或整数格式。不能指定任意颜色。
.unnormalized_coordinates(false)unnormalized_coordinates 字段指定了你是否要使用未标准化的坐标系来寻址图像中的纹素。如果这个字段是 true,那么你可以简单地使用 [0, width) 和 [0, height) 范围内的坐标。如果是 false,那么纹素将在所有轴上使用 [0, 1) 范围来寻址。现实世界中的应用几乎总是使用标准化坐标,因为这样就可以用完全相同的坐标使用不同分辨率的纹理。
.compare_enable(false)
.compare_op(vk::CompareOp::ALWAYS)如果启用了比较函数,那么纹素将首先与一个值进行比较,比较的结果将被用于过滤操作。这主要用于阴影贴图上的近似百分比过滤。我们将在后面的章节中介绍这个。
.mipmap_mode(vk::SamplerMipmapMode::LINEAR)
.mip_lod_bias(0.0)
.min_lod(0.0)
.max_lod(0.0);接下来的这些字段都与多级渐远有关。我们将在后面的章节中介绍多级渐远,但简单来说它就是另一种过滤器。
采样器的功能现在已经完全定义了。添加一个 AppData 字段来保存采样器对象的句柄:
struct AppData {
// ...
texture_image_view: vk::ImageView,
texture_sampler: vk::Sampler,
// ...
}接着使用 create_sampler 函数来创建这个采样器:
data.texture_sampler = device.create_sampler(&info, None)?;注意采样器不引用 vk::Image。采样器是一个独立的对象,它提供了从纹理中提取颜色的接口。采样器可以应用于任何你想要的图像,无论是 1D、2D 还是 3D。这与许多旧的 API 不同,旧的 API 将纹理图像和过滤器组合成一个单一的状态。
在程序结束、我们不再访问图像之后销毁采样器:
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.device.destroy_sampler(self.data.texture_sampler, None);
// ...
}各向异性设备特性
如果你现在运行程序,你会看到一条类似这样的校验层消息:

这是因为各向异性过滤其实是一项可选的设备特性。我们需要更新 create_logical_device 函数来请求它:
let features = vk::PhysicalDeviceFeatures::builder()
.sampler_anisotropy(true);并且尽管现代显卡不支持各向异性过滤的可能性非常小,但我们还是应该更新 check_physical_device 来检查它是否可用:
unsafe fn check_physical_device(
instance: &Instance,
data: &AppData,
physical_device: vk::PhysicalDevice,
) -> Result<()> {
// ...
let features = instance.get_physical_device_features(physical_device);
if features.sampler_anisotropy != vk::TRUE {
return Err(anyhow!(SuitabilityError("No sampler anisotropy.")));
}
Ok(())
}get_physical_device_features 重用了 vk::PhysicalDeviceFeatures 结构体,通过设置布尔值来指示支持哪些特性,而不是请求哪些特性。
你也可以根据条件来设置,而不是强制使用各向异性过滤:
.anisotropy_enable(false)
.max_anisotropy(1.0)下一章中,我们将把图像和采样器对象暴露给着色器,以便将纹理绘制到正方形上。
组合图像采样器
原文链接:https://kylemayes.github.io/vulkanalia/texture/combined_immage_sampler.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs | shader.vert | shader.frag
我们在 uniform 缓冲部分第一次认识了描述符。在本章中我们将看到一种新的描述符:组合图像采样器。这种描述符使得着色器可以通过像我们在上一章中创建的采样器对象来访问图像资源。
首先我们修改描述符集合布局、描述符池以及描述符集合,使其包含一个组合图像采样器描述符。然后我们将在 Vertex 中添加纹理坐标,并修改片元着色器,使其从纹理中读取颜色而不是仅仅插值顶点颜色。
更新描述符
在 create_descriptor_set_layout 函数中为组合图像采样器描述符添加一个 vk::DescriptorSetLayoutBinding。我们将其放在 uniform 缓冲之后的绑定中:
let sampler_binding = vk::DescriptorSetLayoutBinding::builder()
.binding(1)
.descriptor_type(vk::DescriptorType::COMBINED_IMAGE_SAMPLER)
.descriptor_count(1)
.stage_flags(vk::ShaderStageFlags::FRAGMENT);
let bindings = &[ubo_binding, sampler_binding];
let info = vk::DescriptorSetLayoutCreateInfo::builder()
.bindings(bindings);记得将 stage_flags 设为 vk::ShaderStageFlags::FRAGMENT,以指示我们将会在片元着色器中使用组合图像采样器描述符 —— 这是片元的颜色将会被确定的地方。在顶点着色器中使用纹理采样是可能的,例如通过高度图动态地改变顶点网格的形状。
我们必须创建一个更大的描述符池,在 vk::DescriptorPoolCreateInfo 中添加另一个 vk::DescriptorType::COMBINED_IMAGE_SAMPLER 类型的 vk::DescriptorPoolSize,从而为组合图像采样器的分配腾出空间。转到 create_descriptor_pool 函数,为组合图像采样器描述符添加一个 vk::DescriptorPoolSize:
let sampler_size = vk::DescriptorPoolSize::builder()
.type_(vk::DescriptorType::COMBINED_IMAGE_SAMPLER)
.descriptor_count(data.swapchain_images.len() as u32);
let pool_sizes = &[ubo_size, sampler_size];
let info = vk::DescriptorPoolCreateInfo::builder()
.pool_sizes(pool_sizes)
.max_sets(data.swapchain_images.len() as u32);有一些问题是校验层无法捕获的,描述符池不够大就是一个很好的例子:从 Vulkan 1.1 开始,如果描述符池不够大,allocate_descriptor_sets 可能会失败并返回错误码 vk::ErrorCode::OUT_OF_POOL_MEMORY,但驱动程序也可能会尝试在内部解决这个问题。这意味着有时(取决于硬件、池大小和分配大小)驱动程序会允许我们超出描述符池的限制。其他时候,allocate_descriptor_sets 将会失败并返回 vk::ErrorCode::OUT_OF_POOL_MEMORY。如果分配在某些机器上成功,但在其他机器上失败,这可能会让人特别沮丧。
因为 Vulkan 把分配的责任转移给了驱动程序,所以只分配与描述符池创建时相应的 descriptor_count 成员指定的某种类型的描述符(vk::DescriptorType::COMBINED_IMAGE_SAMPLER 等)不再是一个严格的要求。然而,最好还是这样做。并且在将来,如果你启用了最佳实践校验,VK_LAYER_KHRONOS_validation 将会对这种类型的问题发出警告。
最后一步就是将实际的图像和采样器绑定到描述符集合中的描述符上了。转到 create_descriptor_sets 函数。组合图像采样器结构的资源必须在 vk::DescriptorImageInfo 结构中指定,就像 uniform 缓冲描述符的缓冲资源在 vk::DescriptorBufferInfo 结构中指定一样。这就是前一章中的对象结合在一起的地方。
let info = vk::DescriptorImageInfo::builder()
.image_layout(vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL)
.image_view(data.texture_image_view)
.sampler(data.texture_sampler);
let image_info = &[info];
let sampler_write = vk::WriteDescriptorSet::builder()
.dst_set(data.descriptor_sets[i])
.dst_binding(1)
.dst_array_element(0)
.descriptor_type(vk::DescriptorType::COMBINED_IMAGE_SAMPLER)
.image_info(image_info);
device.update_descriptor_sets(
&[ubo_write, sampler_write],
&[] as &[vk::CopyDescriptorSet],
);描述符需要使用图像信息更新。这一次我们使用 image_info 数组,而不是 buffer_info。描述符现在已经可以被着色器使用了!
纹理坐标
纹理映射还缺少一个重要的组成部分,那就是每个顶点的实际坐标。这些坐标决定了图像如何映射到几何体上。
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct Vertex {
pos: Vec2,
color: Vec3,
tex_coord: Vec2,
}
impl Vertex {
const fn new(pos: Vec2, color: Vec3, tex_coord: Vec2) -> Self {
Self { pos, color, tex_coord }
}
fn binding_description() -> vk::VertexInputBindingDescription {
vk::VertexInputBindingDescription::builder()
.binding(0)
.stride(size_of::<Vertex>() as u32)
.input_rate(vk::VertexInputRate::VERTEX)
.build()
}
fn attribute_descriptions() -> [vk::VertexInputAttributeDescription; 3] {
let pos = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(0)
.format(vk::Format::R32G32_SFLOAT)
.offset(0)
.build();
let color = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(1)
.format(vk::Format::R32G32B32_SFLOAT)
.offset(size_of::<Vec2>() as u32)
.build();
let tex_coord = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(2)
.format(vk::Format::R32G32_SFLOAT)
.offset((size_of::<Vec2>() + size_of::<Vec3>()) as u32)
.build();
[pos, color, tex_coord]
}
}修改 Vertex 结构体并为纹理坐标添加一个 Vec2 类型的字段。记得也添加一条 vk::VertexInputAttributeDescription,这样我们就能在顶点着色器中访问纹理坐标了。这样我们才能将它们从顶点着色器传递给片元着色器,以便在正方形表面上进行插值。
static VERTICES: [Vertex; 4] = [
Vertex::new(vec2(-0.5, -0.5), vec3(1.0, 0.0, 0.0), vec2(1.0, 0.0)),
Vertex::new(vec2(0.5, -0.5), vec3(0.0, 1.0, 0.0), vec2(0.0, 0.0)),
Vertex::new(vec2(0.5, 0.5), vec3(0.0, 0.0, 1.0), vec2(0.0, 1.0)),
Vertex::new(vec2(-0.5, 0.5), vec3(1.0, 1.0, 1.0), vec2(1.0, 1.0)),
];在本教程中,我会简单地使用左上角为 0, 0,右下角为 1, 1 的坐标填充正方形。你可以随意尝试不同的坐标,并试着使用小于 0 或大于 1 的坐标来看看寻址模式的效果!
着色器
最后一步就是修改着色器,使其从纹理中采样出颜色。 我们首先需要修改顶点着色器,将纹理坐标传递给片元着色器:
layout(location = 0) in vec2 inPosition;
layout(location = 1) in vec3 inColor;
layout(location = 2) in vec2 inTexCoord;
layout(location = 0) out vec3 fragColor;
layout(location = 1) out vec2 fragTexCoord;
void main() {
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(inPosition, 0.0, 1.0);
fragColor = inColor;
fragTexCoord = inTexCoord;
}
和逐顶点颜色一样,fragTexCoord 值也会被光栅化器在正方形区域内平滑插值。我们可以通过让片元着色器将纹理坐标作为颜色输出来可视化这一点:
#version 450
layout(location = 0) in vec3 fragColor;
layout(location = 1) in vec2 fragTexCoord;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragTexCoord, 0.0, 1.0);
}
别忘记重新编译着色器!之后,你应该会看到下面的图像。
绿色通道代表了水平坐标,红色通道代表了垂直坐标。黑色和黄色的角落证实了纹理坐标在正方形上从 0, 0 插值到 1, 1 的正确性。使用颜色可视化数据是着色器编程中的 printf 调试等效方法,因为没有更好的选择!
组合图像采样器描述符在 GLSL 中是使用采样器 uniform 表示的。在片元着色器中添加一个引用:
layout(binding = 1) uniform sampler2D texSampler;
对于其他类型的图像,有等效的 sampler1D 和 sampler3D 类型。记得在这里使用正确的绑定。
void main() {
outColor = texture(texSampler, fragTexCoord);
}
使用内建的 texture 函数采样纹理。texture 函数接受一个 sampler 和一个坐标作为参数。采样器会自动处理过滤和变换。当你运行应用程序时,你应该会在正方形上看到纹理:
试着缩放纹理坐标,得到大于 1 的值,来试验寻址模式的功能。例如,当使用 vk::SamplerAddressMode::REPEAT 时,下面的片元着色器会产生下面的图像:
void main() {
outColor = texture(texSampler, fragTexCoord * 2.0);
}

你也可以用顶点颜色来改变纹理颜色:
void main() {
outColor = vec4(fragColor * texture(texSampler, fragTexCoord).rgb, 1.0);
}
我在这里分离了 RGB 和 alpha 通道,以免缩放 alpha 通道。

现在你知道如何在着色器中访问图像了!当与帧缓冲中也写入的图像结合使用时,这是一种非常强大的技术。你可以使用这些图像作为输入来实现很酷的效果,比如后处理和 3D 世界中的相机显示。
深度缓冲
原文链接:https://kylemayes.github.io/vulkanalia/model/depth_buffering.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs | shader.vert | shader.frag
我们的几何图形已经被投影到了三维空间中,但到目前为止它还是完全扁平的。在本章中我们会为位置添加一个 Z 坐标,以为 3D 网格做准备。我们将使用这第三个坐标来将一个正方形放在当前正方形上方,以观察当几何图形没有按深度排序时会出现的问题。
3D 几何图形
修改 Vertex 结构体,为位置使用一个 3D 向量,然后更新相应的 vk::VertexInputAttributeDescription 中的 format 字段,并更新其他的偏移量:
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct Vertex {
pos: Vec3,
color: Vec3,
tex_coord: Vec2,
}
impl Vertex {
const fn new(pos: Vec3, color: Vec3, tex_coord: Vec2) -> Self {
Self { pos, color, tex_coord }
}
fn binding_description() -> vk::VertexInputBindingDescription {
vk::VertexInputBindingDescription::builder()
.binding(0)
.stride(size_of::<Vertex>() as u32)
.input_rate(vk::VertexInputRate::VERTEX)
.build()
}
fn attribute_descriptions() -> [vk::VertexInputAttributeDescription; 3] {
let pos = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(0)
.format(vk::Format::R32G32B32_SFLOAT)
.offset(0)
.build();
let color = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(1)
.format(vk::Format::R32G32B32_SFLOAT)
.offset(size_of::<Vec3>() as u32)
.build();
let tex_coord = vk::VertexInputAttributeDescription::builder()
.binding(0)
.location(2)
.format(vk::Format::R32G32_SFLOAT)
.offset((size_of::<Vec3>() + size_of::<Vec3>()) as u32)
.build();
[pos, color, tex_coord]
}
}接着,更新顶点着色器来接受 3D 坐标作为输入。别忘了重新编译着色器!
layout(location = 0) in vec3 inPosition;
// ...
void main() {
gl_Position = ubo.proj * ubo.view * ubo.model * vec4(inPosition, 1.0);
fragColor = inColor;
fragTexCoord = inTexCoord;
}
最后,更新 VERTICES 来包含 Z 坐标:
static VERTICES: [Vertex; 4] = [
Vertex::new(vec3(-0.5, -0.5, 0.0), vec3(1.0, 0.0, 0.0), vec2(1.0, 0.0)),
Vertex::new(vec3(0.5, -0.5, 0.0), vec3(0.0, 1.0, 0.0), vec2(0.0, 0.0)),
Vertex::new(vec3(0.5, 0.5, 0.0), vec3(0.0, 0.0, 1.0), vec2(0.0, 1.0)),
Vertex::new(vec3(-0.5, 0.5, 0.0), vec3(1.0, 1.0, 1.0), vec2(1.0, 1.0)),
];如果你现在运行程序,你应该会看到和之前完全一样的结果。现在是时候添加一些额外的几何图形来让场景更有趣,并展示我们将在本章中解决的问题了。复制顶点来定义一个处在当前正方形下方的正方形的位置,像这样:

将新顶点的 Z 坐标设置为 -0.5,并为额外的正方形添加合适的索引:
static VERTICES: [Vertex; 8] = [
Vertex::new(vec3(-0.5, -0.5, 0.0), vec3(1.0, 0.0, 0.0), vec2(1.0, 0.0)),
Vertex::new(vec3(0.5, -0.5, 0.0), vec3(0.0, 1.0, 0.0), vec2(0.0, 0.0)),
Vertex::new(vec3(0.5, 0.5, 0.0), vec3(0.0, 0.0, 1.0), vec2(0.0, 1.0)),
Vertex::new(vec3(-0.5, 0.5, 0.0), vec3(1.0, 1.0, 1.0), vec2(1.0, 1.0)),
Vertex::new(vec3(-0.5, -0.5, -0.5), vec3(1.0, 0.0, 0.0), vec2(1.0, 0.0)),
Vertex::new(vec3(0.5, -0.5, -0.5), vec3(0.0, 1.0, 0.0), vec2(0.0, 0.0)),
Vertex::new(vec3(0.5, 0.5, -0.5), vec3(0.0, 0.0, 1.0), vec2(0.0, 1.0)),
Vertex::new(vec3(-0.5, 0.5, -0.5), vec3(1.0, 1.0, 1.0), vec2(1.0, 1.0)),
];
const INDICES: &[u16] = &[
0, 1, 2, 2, 3, 0,
4, 5, 6, 6, 7, 4,
];运行程序,你会看到类似于埃舍尔(Escher)艺术作品的图像:

译注:莫里茨·科内利斯·埃舍尔 是荷兰著名版画艺术家,因其视错觉艺术作品而闻名。
问题在于下面的正方形的片元覆盖了上面的正方形的片元,而这仅仅是因为它在索引数组中出现的更晚。有两种方法可以解决这个问题:
- 将所有绘制调用按深度从后向前排序
- 使用深度缓冲进行深度测试
第一种方法通常用于绘制透明物体,因为要实现与绘制顺序无关的透明是很困难的。然而,要根据深度对片元排序,更常见的做法是使用深度缓冲(depth buffer)。深度缓冲是一个额外的附件,它存储了每个位置的深度,就像颜色附件存储了每个位置的颜色一样。每当光栅化器产生一个片元时,深度测试会检查新片元是否比之前的更“近”。如果不是,则丢弃新片元。通过深度测试的片元会将自己的深度写入深度缓冲。深度值也可以从片元着色器中操作,就像操作颜色输出一样。
在我们继续之前,有一个问题需要解决。App::update_uniform_buffer 中 cgmath::perspective 生成的透视投影矩阵使用了 OpenGL 的深度范围 -1.0 到 1.0。我们想要使用 Vulkan 的深度范围 0.0 到 1.0,所以我们将生成的透视矩阵与一个校正矩阵相乘,将 OpenGL 的范围映射到 Vulkan 的范围:
let correction = Mat4::new(
1.0, 0.0, 0.0, 0.0,
// 我们同时通过这行的 `-1.0` 翻转了 Y 轴。
0.0, -1.0, 0.0, 0.0,
0.0, 0.0, 1.0 / 2.0, 0.0,
0.0, 0.0, 1.0 / 2.0, 1.0,
);
let proj = correction
* cgmath::perspective(
Deg(45.0),
self.data.swapchain_extent.width as f32 / self.data.swapchain_extent.height as f32,
0.1,
10.0,
);
// 下面这行已经不需要了,因为我们已经使用新的校正矩阵反转了 Y 轴。
// proj[1][1] *= -1.0;注意 cgmath::Matrix4::new 以列主序构造矩阵,所以我们传递给它的参数看起来像是被转置过。实际构造出的矩阵在行主序下看起来像这样:
1 0 0 0
0 -1 0 0
0 0 ½ ½
0 0 0 1
深度图像与视图
和颜色附件一样,深度附件也是基于图像的。区别在于交换链不会自动为我们创建深度图像。我们只需要一个深度图像,因为同时只有一个绘制操作在运行。深度图像同样需要三个资源:图像、内存和图像视图。
struct AppData {
// ...
depth_image: vk::Image,
depth_image_memory: vk::DeviceMemory,
depth_image_view: vk::ImageView,
}创建一个新函数 create_depth_objects 来设置这些资源:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_command_pool(&instance, &device, &mut data)?;
create_depth_objects(&instance, &device, &mut data)?;
// ...
}
}
unsafe fn create_depth_objects(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
Ok(())
}创建深度图像非常直观。深度图像应该具有以下属性:由交换链范围定义的、与颜色附件相同的分辨率,适用于深度附件的图像用法,最佳平铺模式,并且存储在设备本地内存中。唯一的问题是:深度图像的正确格式是什么?格式必须包含一个深度分量,由 vk::Format 变体中的 D??_ 表示。
不同于纹理图像的是,我们并不需要一个特定的像素格式,因为我们不会直接在程序中访问深度图像中的像素。深度图像中的像素只要有一个合理的精度就行。现实世界中的应用程序通常都使用至少 24 位的精度,有几种格式符合这个要求:
vk::Format::D32_SFLOAT– 为深度使用 32 位浮点数vk::Format::D32_SFLOAT_S8_UINT– 为深度使用 32 位有符号浮点数,同时为模板分量使用 8 个位vk::Format::D24_UNORM_S8_UINT– 为深度使用 24 位浮点数,同时为模板分量使用 8 个位
模板分量可以被用于模板测试,模板测试可以与深度测试结合使用。我们将在未来的章节中讨论这个。
我们可以直接选择 vk::Format::D32_SFLOAT,因为它的支持非常普遍(参见硬件数据库),但是在可能的情况下,为我们的应用程序增加一些额外的灵活性是很好的。我们将编写一个 get_supported_format 函数,它接受一个候选格式列表,将其中的格式按照最理想到最不理想的顺序排列,并返回第一个满足我们要求的格式:
unsafe fn get_supported_format(
instance: &Instance,
data: &AppData,
candidates: &[vk::Format],
tiling: vk::ImageTiling,
features: vk::FormatFeatureFlags,
) -> Result<vk::Format> {
candidates
.iter()
.cloned()
.find(|f| {
})
.ok_or_else(|| anyhow!("Failed to find supported format!"))
}受支持的格式与图像的平铺模式和用法有关,因此我们必须将它们作为参数传递。可以使用 get_physical_device_format_properties 函数查询支持的格式:
let properties = instance.get_physical_device_format_properties(
data.physical_device,
*f,
);vk::FormatProperties 结构体有以下字段:
linear_tiling_features– 支持线性平铺模式的用例optimal_tiling_features– 支持最佳平铺模式的用例buffer_features– 支持缓冲的用例
只有前两个与本章相关,我们根据 tiling 参数的值来检查其中的一个:
match tiling {
vk::ImageTiling::LINEAR => properties.linear_tiling_features.contains(features),
vk::ImageTiling::OPTIMAL => properties.optimal_tiling_features.contains(features),
_ => false,
}现在我们将使用这个函数来创建一个 get_depth_format 辅助函数,以选择一个支持用作深度附件的深度分量格式:
unsafe fn get_depth_format(instance: &Instance, data: &AppData) -> Result<vk::Format> {
let candidates = &[
vk::Format::D32_SFLOAT,
vk::Format::D32_SFLOAT_S8_UINT,
vk::Format::D24_UNORM_S8_UINT,
];
get_supported_format(
instance,
data,
candidates,
vk::ImageTiling::OPTIMAL,
vk::FormatFeatureFlags::DEPTH_STENCIL_ATTACHMENT,
)
}从 create_depth_objects 调用该函数来选择深度格式:
let format = get_depth_format(instance, data)?;现在我们已经有了调用 create_image 和 create_image_view 辅助函数所需的所有信息:
let (depth_image, depth_image_memory) = create_image(
instance,
device,
data,
data.swapchain_extent.width,
data.swapchain_extent.height,
format,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::DEPTH_STENCIL_ATTACHMENT,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
data.depth_image = depth_image;
data.depth_image_memory = depth_image_memory;
// Image View
data.depth_image_view = create_image_view(device, data.depth_image, format)?;然而,create_image_view 函数目前假设子资源总是使用 vk::ImageAspectFlags::COLOR,因此我们需要将该字段变成一个参数:
unsafe fn create_image_view(
device: &Device,
image: vk::Image,
format: vk::Format,
aspects: vk::ImageAspectFlags,
) -> Result<vk::ImageView> {
let subresource_range = vk::ImageSubresourceRange::builder()
.aspect_mask(aspects)
.base_mip_level(0)
.level_count(1)
.base_array_layer(0)
.layer_count(1);
// ...
}更新所有调用点,传递正确的 aspects:
create_image_view(device, *i, data.swapchain_format, vk::ImageAspectFlags::COLOR)
// ...
data.depth_image_view = create_image_view(
device,
data.depth_image,
format,
vk::ImageAspectFlags::DEPTH,
)?;
// ...
data.texture_image_view = create_image_view(
device,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
vk::ImageAspectFlags::COLOR,
)?;创建深度图像就是这样。我们不需要映射它或将另一个图像复制到它,因为我们将在渲染通道的开始处清除它,就像颜色附件一样。
显式转换深度图像
我们不需要显式地将图像的布局转换为深度附件,因为我们将在渲染流程中处理这个问题。然而,为了完整起见,我仍然会在本节中描述这个过程。如果你愿意,你可以跳过它。
在 create_depth_objects 函数的最后,像这样调用 transition_image_layout:
transition_image_layout(
device,
data,
data.depth_image,
format,
vk::ImageLayout::UNDEFINED,
vk::ImageLayout::DEPTH_STENCIL_ATTACHMENT_OPTIMAL,
)?;未定义布局可以被作为初始布局,因为深度图像中没有需要考虑的现有内容。我们需要更新 transition_image_layout 中的一些逻辑,以使用正确的子资源 aspect:
**注意:**第一个
|运算符描述了一个模式,它匹配match分支中指定的任意一个vk::Format。与此同时,第二个|运算符是按位或运算符,它将我们在这段代码中想要启用的vk::ImageAspectFlags位组合在一起。
let aspect_mask = if new_layout == vk::ImageLayout::DEPTH_STENCIL_ATTACHMENT_OPTIMAL {
match format {
vk::Format::D32_SFLOAT_S8_UINT | vk::Format::D24_UNORM_S8_UINT =>
vk::ImageAspectFlags::DEPTH | vk::ImageAspectFlags::STENCIL,
_ => vk::ImageAspectFlags::DEPTH
}
} else {
vk::ImageAspectFlags::COLOR
};
let subresource = vk::ImageSubresourceRange::builder()
.aspect_mask(aspect_mask)
.base_mip_level(0)
.level_count(1)
.base_array_layer(0)
.layer_count(1);尽管我们没有用到模板分量,我们仍然需要在深度图像的布局转换中包含它。
最后,添加正确的访问掩码和管线阶段:
let (
src_access_mask,
dst_access_mask,
src_stage_mask,
dst_stage_mask,
) = match (old_layout, new_layout) {
(vk::ImageLayout::UNDEFINED, vk::ImageLayout::DEPTH_STENCIL_ATTACHMENT_OPTIMAL) => (
vk::AccessFlags::empty(),
vk::AccessFlags::DEPTH_STENCIL_ATTACHMENT_READ | vk::AccessFlags::DEPTH_STENCIL_ATTACHMENT_WRITE,
vk::PipelineStageFlags::TOP_OF_PIPE,
vk::PipelineStageFlags::EARLY_FRAGMENT_TESTS,
),
// ...
};深度缓冲会被读取并进行深度测试来判断片元是否可见,并且当绘制新片元时会被写入。读取发生在 vk::PipelineStageFlags::EARLY_FRAGMENT_TESTS 阶段,写入发生在 vk::PipelineStageFlags::LATE_FRAGMENT_TESTS 阶段。你应该选择最早的管线阶段来匹配指定的操作,这样就能确保深度图像在需要作为深度附件使用时已经就绪。
渲染流程
我们将修改 create_render_pass 函数来包含一个深度附件。首先指定 vk::AttachmentDescription:
let depth_stencil_attachment = vk::AttachmentDescription::builder()
.format(get_depth_format(instance, data)?)
.samples(vk::SampleCountFlags::_1)
.load_op(vk::AttachmentLoadOp::CLEAR)
.store_op(vk::AttachmentStoreOp::DONT_CARE)
.stencil_load_op(vk::AttachmentLoadOp::DONT_CARE)
.stencil_store_op(vk::AttachmentStoreOp::DONT_CARE)
.initial_layout(vk::ImageLayout::UNDEFINED)
.final_layout(vk::ImageLayout::DEPTH_STENCIL_ATTACHMENT_OPTIMAL);format 字段应该与深度图像的格式相同。这次我们不关心存储深度数据(store_op),因为在绘制完成后它将不会被使用。这可能允许硬件执行额外的优化。就像颜色缓冲一样,我们不关心之前的深度内容,所以我们可以使用 vk::ImageLayout::UNDEFINED 作为 initial_layout。
let depth_stencil_attachment_ref = vk::AttachmentReference::builder()
.attachment(1)
.layout(vk::ImageLayout::DEPTH_STENCIL_ATTACHMENT_OPTIMAL);在第一个(也是唯一一个)子流程中添加对深度附件的引用:
let subpass = vk::SubpassDescription::builder()
.pipeline_bind_point(vk::PipelineBindPoint::GRAPHICS)
.color_attachments(color_attachments)
.depth_stencil_attachment(&depth_stencil_attachment_ref);不同于颜色附件的是,一个子流程只能使用一个深度(以及模板)附件。在多个缓冲上进行深度测试没有任何意义。
let attachments = &[color_attachment, depth_stencil_attachment];
let subpasses = &[subpass];
let dependencies = &[dependency];
let info = vk::RenderPassCreateInfo::builder()
.attachments(attachments)
.subpasses(subpasses)
.dependencies(dependencies);接着,更新 vk::RenderPassCreateInfo 结构体,引用两个附件。
let dependency = vk::SubpassDependency::builder()
.src_subpass(vk::SUBPASS_EXTERNAL)
.dst_subpass(0)
.src_stage_mask(vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT
| vk::PipelineStageFlags::EARLY_FRAGMENT_TESTS)
.src_access_mask(vk::AccessFlags::empty())
.dst_stage_mask(vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT
| vk::PipelineStageFlags::EARLY_FRAGMENT_TESTS)
.dst_access_mask(vk::AccessFlags::COLOR_ATTACHMENT_WRITE
| vk::AccessFlags::DEPTH_STENCIL_ATTACHMENT_WRITE);Finally, we need to extend our subpass dependencies to make sure that there is no conflict between the transitioning of the depth image and it being cleared as part of its load operation. The depth image is first accessed in the early fragment test pipeline stage and because we have a load operation that clears, we should specify the access mask for writes.
最后我们需要扩展我们的子流程依赖,以确保深度图像的转换和它在加载操作时的清除操作之间没有冲突。深度图像会在早期片元测试阶段被使用,并且因为我们指定了清除的加载操作,所以我们应该为写入指定访问掩码。
帧缓冲
下一步是修改帧缓冲的创建,将深度图像绑定到深度附件。转到 create_framebuffers,将深度图像视图指定为第二个附件:
let attachments = &[*i, data.depth_image_view];
let create_info = vk::FramebufferCreateInfo::builder()
.render_pass(data.render_pass)
.attachments(attachments)
.width(data.swapchain_extent.width)
.height(data.swapchain_extent.height)
.layers(1);每个交换链图像都有各自的颜色附件,但是由于我们的信号量,因为同一时间只有一个子流程在运行,因此所有交换链图像都可以使用同一个深度图像。
你还需要移动对 create_framebuffers 的调用,以确保它在深度图像视图实际创建后被调用:
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_depth_objects(&instance, &device, &mut data)?;
create_framebuffers(&device, &mut data)?;
// ...
}清除值
因为现在我们有多个具有 vk::AttachmentLoadOp::CLEAR 的附件,所以我们也需要指定多个清除值。转到 create_command_buffers,并在 clear_values 数组中添加一个 vk::ClearValue 实例:
let color_clear_value = vk::ClearValue {
color: vk::ClearColorValue {
float32: [0.0, 0.0, 0.0, 1.0],
},
};
let depth_clear_value = vk::ClearValue {
depth_stencil: vk::ClearDepthStencilValue {
depth: 1.0,
stencil: 0,
},
};
let clear_values = &[color_clear_value, depth_clear_value];深度缓冲中的深度值范围是 0.0 到 1.0,其中 1.0 位于远平面,0.0 位于近平面。深度缓冲中每个点的初始值应该是最远的深度,即 1.0。
注意 clear_values 的顺序应该与你的附件的顺序相同。
深度与模板状态
深度附件现在已经可以使用了,接下来还需要在图形管线中启用深度测试。它通过 vk::PipelineDepthStencilStateCreateInfo 结构体进行配置:
let depth_stencil_state = vk::PipelineDepthStencilStateCreateInfo::builder()
.depth_test_enable(true)
.depth_write_enable(true)
// continued ...depth_test_enable 字段指定新片元的深度是否应该与深度缓冲进行比较,以判断它们是否应该被丢弃。depth_write_enable 字段指定通过深度测试的片元的新深度是否应该被写入深度缓冲。
.depth_compare_op(vk::CompareOp::LESS)depth_compare_op 字段指定用于决定保留还是丢弃片元的比较方式。我们使用较低的深度 = 更近的约定,因此新片元的深度应该是较低的。
.depth_bounds_test_enable(false)
.min_depth_bounds(0.0) // Optional.
.max_depth_bounds(1.0) // Optional.depth_bounds_test_enable、min_depth_bounds 和 max_depth_bounds 字段用于可选的深度范围测试。简单来说,这允许你只保留落在指定深度范围内的片元。我们不会使用这个功能。
.stencil_test_enable(false)
.front(/* vk::StencilOpState */) // Optional.
.back(/* vk::StencilOpState */); // Optional.最后三个字段配置模板缓冲操作,我们在本教程中也不会使用。如果你想使用这些操作,那么你必须确保深度/模板图像的格式包含模板分量。
let info = vk::GraphicsPipelineCreateInfo::builder()
.stages(stages)
.vertex_input_state(&vertex_input_state)
.input_assembly_state(&input_assembly_state)
.viewport_state(&viewport_state)
.rasterization_state(&rasterization_state)
.multisample_state(&multisample_state)
.depth_stencil_state(&depth_stencil_state)
.color_blend_state(&color_blend_state)
.layout(data.pipeline_layout)
.render_pass(data.render_pass)
.subpass(0);更新 vk::GraphicsPipelineCreateInfo 结构体,引用我们刚刚填充的深度模板状态。如果渲染通道包含深度模板附件,则总是需要指定深度模板状态。
如果你现在运行程序,你应该会看到几何体的片元现在被正确排序了:
处理窗口大小变化
当窗口大小改变时,深度缓冲的分辨率应该改变,以匹配新的颜色附件分辨率。在这种情况下,扩展 App::recreate_swapchain 方法来重新创建深度资源:
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
self.device.device_wait_idle()?;
self.destroy_swapchain();
create_swapchain(window, &self.instance, &self.device, &mut self.data)?;
create_swapchain_image_views(&self.device, &mut self.data)?;
create_render_pass(&self.instance, &self.device, &mut self.data)?;
create_pipeline(&self.device, &mut self.data)?;
create_depth_objects(&self.instance, &self.device, &mut self.data)?;
create_framebuffers(&self.device, &mut self.data)?;
create_uniform_buffers(&self.instance, &self.device, &mut self.data)?;
create_descriptor_pool(&self.device, &mut self.data)?;
create_descriptor_sets(&self.device, &mut self.data)?;
create_command_buffers(&self.device, &mut self.data)?;
Ok(())
}清理操作应该在交换链清理函数中发生:
unsafe fn destroy_swapchain(&mut self) {
self.device.destroy_image_view(self.data.depth_image_view, None);
self.device.free_memory(self.data.depth_image_memory, None);
self.device.destroy_image(self.data.depth_image, None);
// ...
}恭喜,你的应用程序现在终于可以正确地渲染任意的 3D 几何体了。我们将在下一章中通过绘制一个带纹理的模型尝试这项功能!
加载模型
原文链接:https://kylemayes.github.io/vulkanalia/model/loading_models.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
现在你的程序已经可以渲染带纹理的 3D 网格了,但当前 vertices 和 indices 数组中的几何图形有些乏味。在本章中,我们将扩展程序,从一个实际的模型文件中加载顶点和索引,让显卡可以实际地做点事情。
许多图形 API 教程都会让读者在这样的章节中编写自己的 OBJ 加载器。但这样做的问题是,更有趣的 3D 应用程序需要许多功能,例如骨骼动画,而 OBJ 格式不支持这些功能。我们将会在本章中从 OBJ 模型加载网格数据,但我们将更多地关注将网格数据与程序本身集成,而不是从文件加载它的细节。
库
我们将使用 tobj crate 从 OBJ 文件中加载顶点和面。如果你遵照了“开发环境”那一章中的说明,那么这个依赖应该已经安装好并且可以使用了。
示例网格
在本章中我们不会启用光照,所以最好使用一个纹理上已经烘焙好光照的示例模型。查找这样的模型的一个简单方法是在 Sketchfab 上寻找 3D 扫描模型。该网站上的许多模型都以 OBJ 格式提供,并且有宽松的许可证。
在本教程中,我决定使用 nigeloh 做的的 Viking room 模型(CC BY 4.0)。我调整了模型的大小和方向,以便将其用作当前几何图形的替代品:
{kind=link}
**注意:**本教程中包含的
.obj和.png文件可能与原始文件不同(并且可能也与原始 C++ 教程中使用的文件不同)。请确保使用本教程中的文件。
你也可以随便使用你自己的模型,但确保它只使用了一个材质(material),并且其尺寸大约为 1.5 x 1.5 x 1.5 个单位。如果它比这个大,那么你将不得不改变视图矩阵。将模型文件和纹理图像放在 resources 目录中。
更新 create_texture_image 以从这个路径加载图像:
的模型的选项。我们将 triangulate 字段设置为 true,以确保加载的模型的组件被转换为三角形。这很重要,因为我们的渲染代
let image = File::open("resources/viking_room.png")?;如果要二次确认你的图像文件是正确的,你还可以在 create_texture_image 中在解码 PNG 图像后添加以下代码:
if width != 1024 || height != 1024 || reader.info().color_type != png::ColorType::Rgba {
panic!("Invalid texture image.");
}加载顶点和索引
现在我们将从模型文件中加载顶点和索引,所以你现在应该删除全局的 VERTICES 和 INDICES 数组。用 AppData 的字段替换它们:
struct AppData {
// ...
vertices: Vec<Vertex>,
indices: Vec<u32>,
vertex_buffer: vk::Buffer,
vertex_buffer_memory: vk::DeviceMemory,
// ...
}你还需要用新的 AppData 字段替换对全局数组的所有引用。
你应该将索引的类型从 u16 改为 u32,因为顶点数量会远超过 65,536。记得也要改变 cmd_bind_index_buffer 的参数:
device.cmd_bind_index_buffer(
*command_buffer,
data.index_buffer,
0,
vk::IndexType::UINT32,
);你还需要更新 create_index_buffer 中索引缓冲的大小:
let size = (size_of::<u32>() * data.indices.len()) as u64;接着我们需要再导入一些东西:
use std::collections::HashMap;
use std::hash::{Hash, Hasher};
use std::io::BufReader;我们现在要编写一个 load_models 函数,它将使用 tobj 库来从网格中获取顶点数据并填充 vertices 和 indices 字段。它应该在创建顶点和索引缓冲之前的某个地方被调用:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
load_model(&mut data)?;
create_vertex_buffer(&instance, &device, &mut data)?;
create_index_buffer(&instance, &device, &mut data)?;
// ...
}
}
fn load_model(data: &mut AppData) -> Result<()> {
Ok(())
}调用 tobj::load_obj_buf 函数来将模型加载到 tobj crate 的数据结构中:
let mut reader = BufReader::new(File::open("resources/viking_room.obj")?);
let (models, _) = tobj::load_obj_buf(
&mut reader,
&tobj::LoadOptions { triangulate: true, ..Default::default() },
|_| Ok(Default::default()),
)?;OBJ 文件由位置、法线、纹理坐标和面组成。面由任意数量的顶点组成,其中每个顶点通过索引引用位置、法线和/或纹理坐标。这使得 OBJ 文件中的面不仅可以重用整个顶点,还可以重用顶点的单个属性。
tobj::load_obj_buf 返回一个模型的 Vec 和一个材质的 Vec。我们对材质不感兴趣,只对模型感兴趣,所以返回的材质被忽略了。
tobj::load_obj_buf 的第二个参数指定了处理加载的模型的选项。我们将 triangulate 字段设置为 true,以确保加载的模型的组件被转换为三角形。这很重要,因为我们的渲染代码只能处理三角形。我们的 Viking room 模型不需要这个,因为它的面已经是三角形了,但如果你尝试使用不同的 OBJ 文件,这可能是必要的。
tobj::load_obj_buf 的第三个参数是一个回调,用于加载 OBJ 文件中引用的材质。我们对材质不感兴趣,所以我们只返回一个空材质。
我们将把文件中的所有面组合成一个模型,所以我们遍历所有模型:
for model in &models {
}三角化功能已经确保每个面有三个顶点,所以我们现在可以直接遍历顶点并将它们直接转储到我们的 vertices 向量中:
for model in &models {
for index in &model.mesh.indices {
let vertex = Vertex {
pos: vec3(0.0, 0.0, 0.0),
color: vec3(1.0, 1.0, 1.0),
tex_coord: vec2(0.0, 0.0),
};
data.vertices.push(vertex);
data.indices.push(data.indices.len() as u32);
}
}简单起见,我们现在假设每个顶点都是唯一的,因此简单地自增索引就行。index 变量用于在 positions 和 texcoords 数组中查找实际的顶点属性:
let pos_offset = (3 * index) as usize;
let tex_coord_offset = (2 * index) as usize;
let vertex = Vertex {
pos: vec3(
model.mesh.positions[pos_offset],
model.mesh.positions[pos_offset + 1],
model.mesh.positions[pos_offset + 2],
),
color: vec3(1.0, 1.0, 1.0),
tex_coord: vec2(
model.mesh.texcoords[tex_coord_offset],
model.mesh.texcoords[tex_coord_offset + 1],
),
};不幸的是,tobj::load_obj_buf 返回的 positions 是一个扁平的数组,存储的是 f32 而不是像 cgmath::Vector3<f32> 这样的东西。考虑到每个顶点坐标有三个分量,你需要将索引乘以 3。类似地,每个纹理坐标有两个分量。对于顶点坐标,偏移量 0、1 和 2 会被用于访问 X、Y 和 Z 分量;对于纹理坐标,偏移量 0 和 1 会被用于访问 U 和 V 分量。
你可能想从现在开始在 release 模式下编译你的程序,因为没有优化的情况下加载纹理和模型可能会非常慢。如果你现在运行你的程序,你应该会看到如下所示的东西:

太棒了,几何图形看起来是正确的,但纹理怎么了?OBJ 格式使用这样一个坐标系:垂直坐标 0 表示图像的底部。但是我们已经将图像以自上而下的方式上传到 Vulkan 中,其中 0 表示图像的顶部。我们通过翻转纹理坐标的垂直分量来解决这个问题:
tex_coord: vec2(
model.mesh.texcoords[tex_coord_offset],
1.0 - model.mesh.texcoords[tex_coord_offset + 1],
),再次运行你的程序,你应该会看到正确的结果:

所有这些辛苦的工作终于开始得到回报了!
顶点去重
不幸的是,我们还没有真正地从索引缓冲中获益。vertices 现在包含了大量重复的顶点数据,因为许多顶点都被多个三角形共用。我们应该只保留唯一一个顶点,并使用索引缓冲重用它们。要实现这一点,一种直接的方法是使用 HashMap 来跟踪唯一的顶点和相应的索引:
let mut unique_vertices = HashMap::new();
for model in &models {
for index in &model.mesh.indices {
// ...
if let Some(index) = unique_vertices.get(&vertex) {
data.indices.push(*index as u32);
} else {
let index = data.vertices.len();
unique_vertices.insert(vertex, index);
data.vertices.push(vertex);
data.indices.push(index as u32);
}
}我们从 OBJ 文件中读取一个索引,并检查我们之前是否已经看到过一个具有完全相同的位置和纹理坐标的顶点。如果没有,我们将它添加到 vertices 中,并将其索引存储在 unique_vertices 容器中。之后,我们将新顶点的索引添加到 indices 中。如果我们之前看到过完全相同的顶点,那么我们将在 unique_vertices 中查找它的索引,并将该索引存储在 indices 中。
程序现在将无法编译,因为我们需要为我们的 Vertex 结构实现 Hash trait,以便将其用作 HashMap 的键。不幸的是,由于 Vertex 包含 f32,我们需要手动实现 Hash 和所需的 trait(PartialEq 和 Eq)(注意,我们的 Eq 实现只在顶点数据中没有 NaN 的情况下才有效,这是一个安全的假设)。
impl PartialEq for Vertex {
fn eq(&self, other: &Self) -> bool {
self.pos == other.pos
&& self.color == other.color
&& self.tex_coord == other.tex_coord
}
}
impl Eq for Vertex {}
impl Hash for Vertex {
fn hash<H: Hasher>(&self, state: &mut H) {
self.pos[0].to_bits().hash(state);
self.pos[1].to_bits().hash(state);
self.pos[2].to_bits().hash(state);
self.color[0].to_bits().hash(state);
self.color[1].to_bits().hash(state);
self.color[2].to_bits().hash(state);
self.tex_coord[0].to_bits().hash(state);
self.tex_coord[1].to_bits().hash(state);
}
}现在你应该能够成功编译和运行你的程序。如果你检查 vertices 的大小,你会发现顶点数量已经从 1,500,000 减少到了 265,645!这意味着每个顶点平均被大约 6 个三角形重用。这绝对节省了大量的 GPU 内存。
生成多级渐远
原文链接:https://kylemayes.github.io/vulkanalia/quality/generating_mipmaps.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
现在我们的程序可以加载并渲染 3D 模型了。本章中我们会再添加一个特性:多级渐远生成。多级渐远被广泛用于游戏和渲染软件中,而 Vulkan 允许你完全地控制多级渐远的创建方式。
多级渐远是预先计算好的、缩小过的图像。每个新图像的宽度和高度都是上一个图像的一半。多级渐远被用作*细节层级(Level of Detail, LOD)*一种形式。远离相机的物体将从较小的多级渐远图像中采样它们的纹理。使用较小的图像可以提高渲染速度并避免诸如摩尔纹之类的伪像。下面是多级渐远的一个例子:

创建图像
在 Vulkan 中,每个多级渐远图像都存储在 vk::Image 的不同多级渐远层级中。多级渐远层级 0 是原始图像,层级 0 之后的多级渐远层级通常被称为多级渐远链。
多级渐远层级的数量在创建 vk::Image 时指定。到目前为止,我们总是将这个值设置为 1,而现在我们需要根据图像的尺寸计算多级渐远层级的数量。首先,在 AppData 中添加一个字段来存储这个数字:
struct AppData {
// ...
mip_levels: u32,
texture_image: vk::Image,
// ...
}mip_levels 的值可以在 create_texture_image 中加载纹理后被计算出来:
let image = File::open("resources/viking_room.png")?;
let decoder = png::Decoder::new(image);
let mut reader = decoder.read_info()?;
// ...
data.mip_levels = (width.max(height) as f32).log2().floor() as u32 + 1;这个表达式计算了多级渐远链中的层级数量。max 方法选择长和宽中更大的维度。log2 方法计算该维度可以被 2 整除的次数。floor 方法处理该维度不是 2 的幂的情况。最后为了让原始图像也有一个多级渐远层级,我们加上 1。
要使用这个值,我们需要修改 create_image、create_image_view 和 transition_image_layout 函数,以允许我们指定多级渐远层级的数量。在这些函数中添加一个 mip_levels 参数:
unsafe fn create_image(
instance: &Instance,
device: &Device,
data: &AppData,
width: u32,
height: u32,
mip_levels: u32,
format: vk::Format,
tiling: vk::ImageTiling,
usage: vk::ImageUsageFlags,
properties: vk::MemoryPropertyFlags,
) -> Result<(vk::Image, vk::DeviceMemory)> {
let info = vk::ImageCreateInfo::builder()
// ...
.mip_levels(mip_levels)
// ...
// ...
}unsafe fn create_image_view(
device: &Device,
image: vk::Image,
format: vk::Format,
aspects: vk::ImageAspectFlags,
mip_levels: u32,
) -> Result<vk::ImageView> {
let subresource_range = vk::ImageSubresourceRange::builder()
// ...
.level_count(mip_levels)
// ...
// ...
}unsafe fn transition_image_layout(
device: &Device,
data: &AppData,
image: vk::Image,
format: vk::Format,
old_layout: vk::ImageLayout,
new_layout: vk::ImageLayout,
mip_levels: u32,
) -> Result<()> {
// ...
let subresource = vk::ImageSubresourceRange::builder()
// ...
.level_count(mip_levels)
// ...
// ...
}更新所有调用这些函数的地方,以使用正确的值:
注意:确保对除纹理之外的所有图像和图像视图使用
1。
let (depth_image, depth_image_memory) = create_image(
instance,
device,
data,
data.swapchain_extent.width,
data.swapchain_extent.height,
1,
format,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::DEPTH_STENCIL_ATTACHMENT,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
// ...
let (texture_image, texture_image_memory) = create_image(
instance,
device,
data,
width,
height,
data.mip_levels,
vk::Format::R8G8B8A8_SRGB,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::SAMPLED | vk::ImageUsageFlags::TRANSFER_DST,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;create_image_view(
device,
*i,
data.swapchain_format,
vk::ImageAspectFlags::COLOR,
1,
)
// ...
data.depth_image_view = create_image_view(
device,
data.depth_image,
format,
vk::ImageAspectFlags::DEPTH,
1,
)?;
// ...
data.texture_image_view = create_image_view(
device,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
vk::ImageAspectFlags::COLOR,
data.mip_levels,
)?;transition_image_layout(
device,
data,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
vk::ImageLayout::UNDEFINED,
vk::ImageLayout::TRANSFER_DST_OPTIMAL,
data.mip_levels,
)?;
// ...
transition_image_layout(
device,
data,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
vk::ImageLayout::TRANSFER_DST_OPTIMAL,
vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL,
data.mip_levels,
)?;生成多级渐远
现在我们的纹理图像有多个多级渐远层级了,但目前为止我们只用暂存缓冲填充了层级 0。其他层级的内容仍然是未定义的。要填充这些层级,我们需要从我们拥有的单个层级生成数据。我们将使用 cmd_blit_image 指令。这个指令执行复制、缩放和过滤操作。我们将多次调用它来将数据blit到我们纹理图像的每个层级。
cmd_blit_image 被视为一个传输操作,所以我们必须告诉 Vulkan 我们打算将纹理图像用作传输源和传输目标。在 create_texture_image 中,将 vk::ImageUsageFlags::TRANSFER_SRC 添加到纹理图像的用法标志中:
let (texture_image, texture_image_memory) = create_image(
instance,
device,
data,
width,
height,
data.mip_levels,
vk::Format::R8G8B8A8_SRGB,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::SAMPLED
| vk::ImageUsageFlags::TRANSFER_DST
| vk::ImageUsageFlags::TRANSFER_SRC,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;和其他图像操作一样,cmd_blit_image 依赖于图像的布局。我们可以将整个图像转换为 vk::ImageLayout::GENERAL,但这很可能会很慢。为了获得最佳性能,源图像应该是 vk::ImageLayout::TRANSFER_SRC_OPTIMAL,目标图像应该是 vk::ImageLayout::TRANSFER_DST_OPTIMAL。Vulkan 允许我们独立地转换图像的每个多级渐远层级。每个 blit 每次只处理两个多级渐远层级,所以我们可以在 blit 指令之间将每个层级转换为最佳布局。
transition_image_layout 只对整个图像执行布局转换,所以我们需要再写几个管线屏障指令。在 create_texture_image 中删除现有的将图像转换到 vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL 的操作。
这将使纹理图像的每个层级都处于 vk::ImageLayout::TRANSFER_DST_OPTIMAL。在从中读取的 blit 指令完成后,每个层级将被转换为 vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL。
现在我们要写生成多级渐远的函数:
unsafe fn generate_mipmaps(
instance: &Instance,
device: &Device,
data: &AppData,
image: vk::Image,
width: u32,
height: u32,
mip_levels: u32,
) -> Result<()> {
let command_buffer = begin_single_time_commands(device, data)?;
let subresource = vk::ImageSubresourceRange::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.base_array_layer(0)
.layer_count(1)
.level_count(1);
let mut barrier = vk::ImageMemoryBarrier::builder()
.image(image)
.src_queue_family_index(vk::QUEUE_FAMILY_IGNORED)
.dst_queue_family_index(vk::QUEUE_FAMILY_IGNORED)
.subresource_range(subresource);
end_single_time_commands(device, data, command_buffer)?;
Ok(())
}我们将进行多次转换,所以我们将重用这个 vk::ImageMemoryBarrier(这就是为什么它被定义为可变的)。上面设置的字段将对所有屏障保持不变。subresource_range.mip_level、old_layout、new_layout、src_access_mask 和 dst_access_mask 将在每次转换中被改变。
let mut mip_width = width;
let mut mip_height = height;
for i in 1..mip_levels {
}This loop will record each of the cmd_blit_image commands. Note that the range index starts at 1, not 0.
这个循环将记录每个 cmd_blit_image 指令。注意,范围索引从 1 开始,而不是 0。
barrier.subresource_range.base_mip_level = i - 1;
barrier.old_layout = vk::ImageLayout::TRANSFER_DST_OPTIMAL;
barrier.new_layout = vk::ImageLayout::TRANSFER_SRC_OPTIMAL;
barrier.src_access_mask = vk::AccessFlags::TRANSFER_WRITE;
barrier.dst_access_mask = vk::AccessFlags::TRANSFER_READ;
device.cmd_pipeline_barrier(
command_buffer,
vk::PipelineStageFlags::TRANSFER,
vk::PipelineStageFlags::TRANSFER,
vk::DependencyFlags::empty(),
&[] as &[vk::MemoryBarrier],
&[] as &[vk::BufferMemoryBarrier],
&[barrier],
);首先,我们将层级 i - 1 转换为 vk::ImageLayout::TRANSFER_SRC_OPTIMAL。这个转换将等待层级i - 1 被填充,要么是来自前一个 blit 指令,要么是来自 cmd_copy_buffer_to_image。当前的 blit 指令将等待这个转换。
let src_subresource = vk::ImageSubresourceLayers::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.mip_level(i - 1)
.base_array_layer(0)
.layer_count(1);
let dst_subresource = vk::ImageSubresourceLayers::builder()
.aspect_mask(vk::ImageAspectFlags::COLOR)
.mip_level(i)
.base_array_layer(0)
.layer_count(1);
let blit = vk::ImageBlit::builder()
.src_offsets([
vk::Offset3D { x: 0, y: 0, z: 0 },
vk::Offset3D {
x: mip_width as i32,
y: mip_height as i32,
z: 1,
},
])
.src_subresource(src_subresource)
.dst_offsets([
vk::Offset3D { x: 0, y: 0, z: 0 },
vk::Offset3D {
x: (if mip_width > 1 { mip_width / 2 } else { 1 }) as i32,
y: (if mip_height > 1 { mip_height / 2 } else { 1 }) as i32,
z: 1,
},
])
.dst_subresource(dst_subresource);接着,我们指定 blit 操作将会使用的区域。源多级渐远层级是 i - 1,目标多级渐远层级是 i。src_offsets 数组的两个元素决定了数据将从哪里 blit 出来的 3D 区域。dst_offsets 决定了数据将 blit 到哪里的区域。dst_offsets[1] 的 X 和 Y 维度被 2 除以,因为每个多级渐远层级的大小是前一个层级的一半。src_offsets[1] 和 dst_offsets[1] 的 Z 维度必须是 1,因为 2D 图像的深度是 1。
device.cmd_blit_image(
command_buffer,
image,
vk::ImageLayout::TRANSFER_SRC_OPTIMAL,
image,
vk::ImageLayout::TRANSFER_DST_OPTIMAL,
&[blit],
vk::Filter::LINEAR,
);现在,我们记录 blit 指令。注意,image 被用于 src_image 和 dst_image 参数。这是因为我们在同一图像的不同层级之间 blit。源多级渐远层级刚刚转换为 vk::ImageLayout::TRANSFER_SRC_OPTIMAL,而目标级层级仍然处于 create_texture_image 中的 vk::ImageLayout::TRANSFER_DST_OPTIMAL。
如果你正在使用专用的传输队列(如 顶点缓冲 章节中所提到的),那么请注意 cmd_blit_image 必须被提交到具有图形功能的队列。
最后一个参数允许我们指定 blit 中使用的 vk::Filter。我们在这里有与创建 vk::Sampler 时相同的过滤选项。我们使用 vk::Filter::LINEAR 来启用插值。
barrier.old_layout = vk::ImageLayout::TRANSFER_SRC_OPTIMAL;
barrier.new_layout = vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL;
barrier.src_access_mask = vk::AccessFlags::TRANSFER_READ;
barrier.dst_access_mask = vk::AccessFlags::SHADER_READ;
device.cmd_pipeline_barrier(
command_buffer,
vk::PipelineStageFlags::TRANSFER,
vk::PipelineStageFlags::FRAGMENT_SHADER,
vk::DependencyFlags::empty(),
&[] as &[vk::MemoryBarrier],
&[] as &[vk::BufferMemoryBarrier],
&[barrier],
);这个屏障将多级渐远层级 i - 1 转换为 vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL。这个转换等待当前的 blit 指令完成。所有采样操作都将等待这个转换完成。
if mip_width > 1 {
mip_width /= 2;
}
if mip_height > 1 {
mip_height /= 2;
}在循环体结束时,我们将当前的多级渐远维度除以 2。我们在除法之前检查每个维度,以确保该维度永远不会变为 0。这处理了图像不是正方形的情况,因为如果图像不是正方形,其中一个多级渐远维度会在另一个维度之前达到 1。当这种情况发生时,在剩下的层级中该维度应该保持 1。
barrier.subresource_range.base_mip_level = mip_levels - 1;
barrier.old_layout = vk::ImageLayout::TRANSFER_DST_OPTIMAL;
barrier.new_layout = vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL;
barrier.src_access_mask = vk::AccessFlags::TRANSFER_WRITE;
barrier.dst_access_mask = vk::AccessFlags::SHADER_READ;
device.cmd_pipeline_barrier(
command_buffer,
vk::PipelineStageFlags::TRANSFER,
vk::PipelineStageFlags::FRAGMENT_SHADER,
vk::DependencyFlags::empty(),
&[] as &[vk::MemoryBarrier],
&[] as &[vk::BufferMemoryBarrier],
&[barrier],
);
end_single_time_commands(device, data, command_buffer)?;在我们结束指令缓冲之前,我们插入了一个管线屏障。这个屏障将最后一个多级渐远层级从 vk::ImageLayout::TRANSFER_DST_OPTIMAL 转换为 vk::ImageLayout::SHADER_READ_ONLY_OPTIMAL。这在循环中没有处理,因为最后一个多级渐远层级不会被 blit 操作。
最后,在 create_texture_image 的末尾添加对 generate_mipmaps 的调用:
generate_mipmaps(
instance,
device,
data,
data.texture_image,
width,
height,
data.mip_levels,
)?;我们的纹理图像的多级渐远现在已经填充好了。
检查线性过滤支持
使用内置指令 cmd_blit_image 来生成所有的多级渐远层级非常方便,但不幸的是,并非所有的平台都保证支持它。cmd_blit_image 要求我们使用的纹理图像格式支持线性过滤,这可以通过 get_physical_device_format_properties 指令来检查。我们将在 generate_mipmaps 函数中添加一个检查。
首先添加一个额外的参数来指定图像格式:
generate_mipmaps(
instance,
device,
data,
data.texture_image,
vk::Format::R8G8B8A8_SRGB,
width,
height,
data.mip_levels,
)?;
// ...
unsafe fn generate_mipmaps(
instance: &Instance,
device: &Device,
data: &AppData,
image: vk::Image,
format: vk::Format,
width: u32,
height: u32,
mip_levels: u32,
) -> Result<()> {
// ...
}在 generate_mipmaps 函数中,使用 get_physical_device_format_properties 来请求纹理图像格式的属性,并检查是否支持线性过滤:
if !instance
.get_physical_device_format_properties(data.physical_device, format)
.optimal_tiling_features
.contains(vk::FormatFeatureFlags::SAMPLED_IMAGE_FILTER_LINEAR)
{
return Err(anyhow!("Texture image format does not support linear blitting!"));
}vk::FormatProperties 结构有三个字段,分别命名为 linear_tiling_features、optimal_tiling_features 和 buffer_features,它们描述了格式在使用方式不同的情况下的使用方式。我们使用最佳平铺格式创建纹理图像,所以我们需要检查 optimal_tiling_features。可以使用 vk::FormatFeatureFlags::SAMPLED_IMAGE_FILTER_LINEAR 来检查线性过滤特性的支持。
在不支持的情况下有两种替代方案。你可以实现一个函数,搜索常见的纹理图像格式,找到一个支持线性 blit 的格式,或者你可以在你的软件中实现多级渐远的生成。然后,每个多级渐远层级可以以与加载原始图像相同的方式加载到图像中。
应该指出的是,在实践中,程序通常不会在运行时生成多级渐远层级。通常,它们是预先生成的,并与基础层级一起存储在纹理文件中,以提高加载速度。在软件中实现调整大小并从文件加载多个层级的功能留给读者作为练习。
采样器
vk::Image 中保存了多级渐远数据,而 vk::Sampler 控制了渲染时如何读取这些数据。Vulkan 允许我们指定 min_lod、max_lod、mip_lod_bias 和 mipmap_mode("LOD" 意味着 "细节层级")。当采样纹理时,采样器根据以下伪代码选择一个多级渐远层级:
// 物体越近就越小,可以为负值
let mut lod = get_lod_level_from_screen_size();
lod = clamp(lod + mip_lod_bias, min_lod, max_lod);
// 截断到纹理中多级渐远层级的数量
let level = clamp(floor(lod), 0, texture.mip_levels - 1);
let color = if mipmap_mode == vk::SamplerMipmapMode::NEAREST {
sample(level)
} else {
blend(sample(level), sample(level + 1))
};如果 sampler_info.mipmap_mode(多级渐远模式)是 vk::SamplerMipmapMode::NEAREST,则 lod 会选择一个用于采样的多级渐远层级。如果多级渐远模式是 vk::SamplerMipmapMode::LINEAR,则 lod 用于选择要采样的两个多级渐远层级,对这些层级进行采样,并对结果线性混合。
采样操作也受 lod 的影响:
let color = if lod <= 0 {
read_texture(uv, mag_filter)
} else {
read_texture(uv, min_filter)
};如果物体靠近相机,mag_filter 将被用作过滤器。如果物体离相机更远,min_filter 将被用作过滤器。通常,lod 是非负的,只有在靠近相机时才是 0。mip_lod_bias 让我们强制 Vulkan 使用比它通常使用的更低的 lod 和 level。
为了看到本章代码的效果,我们需要设置 texture_sampler 的字段。我们之前已经将 min_filter 和 mag_filter 设置为 vk::Filter::LINEAR,现在我们只需要设置 min_lod、max_lod、mip_lod_bias 和 mipmap_mode。
unsafe fn create_texture_sampler(device: &Device, data: &mut AppData) -> Result<()> {
let info = vk::SamplerCreateInfo::builder()
// ...
.mipmap_mode(vk::SamplerMipmapMode::LINEAR)
.min_lod(0.0) // Optional.
.max_lod(data.mip_levels as f32)
.mip_lod_bias(0.0); // Optional.
data.texture_sampler = device.create_sampler(&info, None)?;
Ok(())
}要使用所有的多级渐远层级,我们将 min_lod 设置为 0.0,max_lod 设置为多级渐远层级的数量。我们没有理由改变 lod 值,所以我们将 mip_lod_bias 设置为 0.0f。
现在运行你的程序,你应该会看到以下内容:

我们的场景太简单了,所以没有什么明显的区别。如果你仔细观察,你会发现微妙的区别(如果你在单独的标签中打开下面的图像,你会发现区别很容易被发现,这样你就可以看到它的全尺寸)。

最明显的区别之一是斧头。有了多级渐远,深灰色和浅灰色区域之间的边界已经被平滑了。要是没有多级渐远,这些边界要锐利得多。在这张图像中,斧头被放大了 8 倍,以显示有多级渐远和没有多级渐远(没有任何过滤,所以像素只是被扩展了)的情况。

你可以玩一下采样器的设置,看看它们如何影响多级渐远。例如,通过改变 min_lod,你可以强制采样器不使用最低的多级渐远层级:
.min_lod(data.mip_levels as f32 / 2.0)这些设置将产生这样的图像:

这是当物体离相机更远时,更高的多级渐远层级将如何使用。
多重采样
原文链接:https://kylemayes.github.io/vulkanalia/quality/multisampling.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
现在我们的程序为纹理加载了多个细节层级,这能修复渲染远离观察者的物体时的伪影。图像现在更加平滑了,但是如果仔细观察,你会发现在几何形状的边缘有锯齿状的图案。这在我们早期的程序中就能看到,当我们渲染一个四边形时:

这种我们不希望看到的效果被称为“锯齿”(aliasing),它是由于渲染可用的像素数量有限造成的。因为没有显示器的分辨率是无限的,所以锯齿总是会在某种程度上可见。有很多方法可以修复这个问题,在本章中我们将会专注于其中一个比较流行的方法:多重采样抗锯齿(multisample anti-aliasing, MSAA)。
在通常的渲染中,像素的颜色是由单个样本点决定的,这个样本点在大多数情况下是屏幕上目标像素的中心。而如果绘制的线段通过某个像素,但是没有覆盖样本点,那么这个像素就会被留空,导致了锯齿状的“楼梯”效果。
MSAA 所做的就是使用多个样本点来决定像素的最终颜色(因此得名)。正如你所期望的那样,更多的样本会得到更好的结果,但也会消耗更多计算资源。
在我们的实现中,我们会使用可用的最大样本数量。取决于你的应用程序,这可能不是最好的方法。如果更少的样本就能满足你的质量要求,那么为了性能,使用更少的样本可能会更好。
获取可用的样本数量
Let's start off by determining how many samples our hardware can use. Most modern GPUs support at least 8 samples but this number is not guaranteed to be the same everywhere. We'll keep track of it by adding a new field to AppData:
让我们从检测硬件支持多少样本开始。大多数现代 GPU 至少支持 8 个样本,但这个数字不保证在任何地方都是一样的。我们在 AppData 中添加一个新字段来记录它:
struct AppData {
// ...
physical_device: vk::PhysicalDevice,
msaa_samples: vk::SampleCountFlags,
// ...
}默认情况下,我们为每个像素使用一个样本,相当于没有多重采样,这种情况下最终图像将保持不变。最大样本数可以从与我们选择的物理设备相关联的 vk::PhysicalDeviceProperties 中提取。我们使用了深度缓冲,因此我们必须考虑将颜色和深度的样本数都考虑在内。两者都支持的最高样本数(使用 & 运算符)将是我们可以支持的最大样本数。添加一个函数来获取这些信息:
unsafe fn get_max_msaa_samples(
instance: &Instance,
data: &AppData,
) -> vk::SampleCountFlags {
let properties = instance.get_physical_device_properties(data.physical_device);
let counts = properties.limits.framebuffer_color_sample_counts
& properties.limits.framebuffer_depth_sample_counts;
[
vk::SampleCountFlags::_64,
vk::SampleCountFlags::_32,
vk::SampleCountFlags::_16,
vk::SampleCountFlags::_8,
vk::SampleCountFlags::_4,
vk::SampleCountFlags::_2,
]
.iter()
.cloned()
.find(|c| counts.contains(*c))
.unwrap_or(vk::SampleCountFlags::_1)
}现在我们在选取物理设备的环节使用这个函数来设置 msaa_samples 变量。我们稍微修改 pick_physical_device 函数,在选取物理设备之后设置最大的 MSAA 样本数:
unsafe fn pick_physical_device(instance: &Instance, data: &mut AppData) -> Result<()> {
// ...
for physical_device in instance.enumerate_physical_devices()? {
// ...
if let Err(error) = check_physical_device(instance, data, physical_device) {
// ...
} else {
// ...
data.msaa_samples = get_max_msaa_samples(instance, data);
return Ok(());
}
}
Ok(())
}设置渲染目标
在 MSAA 中,每个像素都在一个离屏缓冲中进行采样,然后离屏缓冲被渲染到屏幕上。这个新的缓冲与我们一直渲染到的普通图像略有不同 —— 它们必须能为每个像素存储多个样本。一旦创建了多重采样缓冲,就必须将其解析到默认的帧缓冲(每个像素只存储一个样本)。这就是为什么我们必须创建一个额外的渲染目标并修改我们当前的绘制过程。我们只需要一个渲染目标,因为一次只能有一个绘制操作处于活动状态,就像深度缓冲一样。在 AppData 中添加以下字段:
struct AppData {
// ...
color_image: vk::Image,
color_image_memory: vk::DeviceMemory,
color_image_view: vk::ImageView,
// ...
}This new image will have to store the desired number of samples per pixel, so we need to pass this number to vk::ImageCreateInfo during the image creation process. Modify the ^create_image function by adding a samples parameter:
这个新的图像需要为每个像素存储所需数量的样本,因此我们需要在创建图像的过程中将样本数传递给 vk::ImageCreateInfo。修改 create_image 函数,添加一个 samples 参数:
unsafe fn create_image(
instance: &Instance,
device: &Device,
data: &AppData,
width: u32,
height: u32,
mip_levels: u32,
samples: vk::SampleCountFlags,
format: vk::Format,
tiling: vk::ImageTiling,
usage: vk::ImageUsageFlags,
properties: vk::MemoryPropertyFlags,
) -> Result<(vk::Image, vk::DeviceMemory)> {
// Image
let info = vk::ImageCreateInfo::builder()
// ...
.samples(samples)
// ...
// ...
}现在我们先暂时给所有调用这个函数的地方传递 vk::SampleCountFlags::_1,我们将在实现过程中逐步将其替换为正确的值:
let (depth_image, depth_image_memory) = create_image(
instance,
device,
data,
data.swapchain_extent.width,
data.swapchain_extent.height,
1,
vk::SampleCountFlags::_1,
format,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::DEPTH_STENCIL_ATTACHMENT,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
// ...
let (texture_image, texture_image_memory) = create_image(
instance,
device,
data,
width,
height,
data.mip_levels,
vk::SampleCountFlags::_1,
vk::Format::R8G8B8A8_SRGB,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::SAMPLED
| vk::ImageUsageFlags::TRANSFER_DST
| vk::ImageUsageFlags::TRANSFER_SRC,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;现在我们将创建一个多重采样的颜色缓冲。添加一个 create_color_objects 函数,并注意我们在这里将 data.msaa_samples 传递给 create_image。我们只使用一个多级渐远层级,因为 Vulkan 规范要求每个像素有多个样本的图像必须只有一个多级渐远层级。此外,这个颜色缓冲不需要多级渐远层级,因为它不会被用作纹理:
unsafe fn create_color_objects(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let (color_image, color_image_memory) = create_image(
instance,
device,
data,
data.swapchain_extent.width,
data.swapchain_extent.height,
1,
data.msaa_samples,
data.swapchain_format,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::COLOR_ATTACHMENT
| vk::ImageUsageFlags::TRANSIENT_ATTACHMENT,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
data.color_image = color_image;
data.color_image_memory = color_image_memory;
data.color_image_view = create_image_view(
device,
data.color_image,
data.swapchain_format,
vk::ImageAspectFlags::COLOR,
1,
)?;
Ok(())
}为了保持一致性,在 create_depth_objects 之前调用这个函数:
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_color_objects(&instance, &device, &mut data)?;
create_depth_objects(&instance, &device, &mut data)?;
// ...
}现在我们已经有了一个多重采样的颜色缓冲,是时候来处理深度了。修改 create_depth_objects,更新深度缓冲使用的样本数:
unsafe fn create_depth_objects(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
// ...
let (depth_image, depth_image_memory) = create_image(
instance,
device,
data,
data.swapchain_extent.width,
data.swapchain_extent.height,
1,
data.msaa_samples,
format,
vk::ImageTiling::OPTIMAL,
vk::ImageUsageFlags::DEPTH_STENCIL_ATTACHMENT,
vk::MemoryPropertyFlags::DEVICE_LOCAL,
)?;
// ...
}我们现在创建了一些新的 Vulkan 资源,所以不要忘记在必要时释放它们:
unsafe fn destroy_swapchain(&mut self) {
self.device.destroy_image_view(self.data.color_image_view, None);
self.device.free_memory(self.data.color_image_memory, None);
self.device.destroy_image(self.data.color_image, None);
// ...
}然后更新 App::recreate_swapchain 方法,这样当窗口大小改变时,新的颜色图像就能以正确的分辨率重新创建:
unsafe fn recreate_swapchain(&mut self, window: &Window) -> Result<()> {
// ...
create_color_objects(&self.instance, &self.device, &mut self.data)?;
create_depth_objects(&self.instance, &self.device, &mut self.data)?;
// ...
}我们已经完成了初始的 MSAA 设置,现在我们需要在图形管线、帧缓冲和渲染流程中开始使用这个新资源,然后看看效果!
添加新的附件
首先处理渲染流程。修改 create_render_pass,更新颜色和深度附件创建信息:
unsafe fn create_render_pass(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
let color_attachment = vk::AttachmentDescription::builder()
// ...
.samples(data.msaa_samples)
// ...
.final_layout(vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL);
let depth_stencil_attachment = vk::AttachmentDescription::builder()
// ...
.samples(data.msaa_samples)
// ...
// ...
}你会注意到我们已经将 final_layout 从 vk::ImageLayout::PRESENT_SRC_KHR 改为了 vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL。这是因为多重采样图像不能直接呈现。我们首先需要将它们解析为普通图像。这个要求不适用于深度缓冲,因为它不会在任何时候被呈现。因此,我们只需要为颜色添加一个新的附件,这是一个所谓的解析附件:
let color_resolve_attachment = vk::AttachmentDescription::builder()
.format(data.swapchain_format)
.samples(vk::SampleCountFlags::_1)
.load_op(vk::AttachmentLoadOp::DONT_CARE)
.store_op(vk::AttachmentStoreOp::STORE)
.stencil_load_op(vk::AttachmentLoadOp::DONT_CARE)
.stencil_store_op(vk::AttachmentStoreOp::DONT_CARE)
.initial_layout(vk::ImageLayout::UNDEFINED)
.final_layout(vk::ImageLayout::PRESENT_SRC_KHR);现在必须告诉渲染流程将多重采样的颜色图像解析为普通附件。创建一个新的附件引用,它将指向颜色缓冲,该缓冲将用作解析目标:
let color_resolve_attachment_ref = vk::AttachmentReference::builder()
.attachment(2)
.layout(vk::ImageLayout::COLOR_ATTACHMENT_OPTIMAL);让 resolve_attachments 成员指向新创建的附件引用。这就足以让渲染流程定义一个能将图像渲染到屏幕上的多重采样解析操作了:
let color_attachments = &[color_attachment_ref];
let resolve_attachments = &[color_resolve_attachment_ref];
let subpass = vk::SubpassDescription::builder()
.pipeline_bind_point(vk::PipelineBindPoint::GRAPHICS)
.color_attachments(color_attachments)
.depth_stencil_attachment(&depth_stencil_attachment_ref)
.resolve_attachments(resolve_attachments);现在用新的颜色附件更新渲染流程创建信息:
let attachments = &[
color_attachment,
depth_stencil_attachment,
color_resolve_attachment,
];
let subpasses = &[subpass];
let dependencies = &[dependency];
let info = vk::RenderPassCreateInfo::builder()
.attachments(attachments)
.subpasses(subpasses)
.dependencies(dependencies);渲染流程就位了,修改 create_framebuffers,将新的图像视图添加到附件切片中:
let attachments = &[data.color_image_view, data.depth_image_view, *i];最后,修改 create_pipeline 来告诉新创建的管线使用多个样本:
let multisample_state = vk::PipelineMultisampleStateCreateInfo::builder()
.sample_shading_enable(false)
.rasterization_samples(data.msaa_samples);现在运行程序,你应该会看到下面的效果:

就像多级渐远一样,差异可能不会立即显现出来。仔细观察,你会注意到边缘不再那么锯齿状,整个图像与原始图像相比似乎更加平滑(如果你在单独的标签页中打开下面的图像,差异会更容易被发现)。

再把斧头头部放大 8 倍,差异更加明显:

质量提升
我们目前的 MSAA 实现有一些局限性,在细节更多的场景中,这可能影响输出画面的质量。例如,现在我们还没有解决着色器锯齿会造成的潜在问题,也就是说,MSAA 只平滑了图形的边缘,但却没有处理内部的填充。这可能会导致这样一种情况:屏幕上渲染出了一个平滑的多边形,但是如果应用的纹理包含高对比度的颜色,那么纹理看起来仍然是锯齿状的。解决这个问题的一种方法是启用采样着色,这将进一步提高图像质量,但会带来额外的性能开销:
unsafe fn create_logical_device(
instance: &Instance,
data: &mut AppData,
) -> Result<Device> {
// ...
let features = vk::PhysicalDeviceFeatures::builder()
.sampler_anisotropy(true)
// Enable sample shading feature for the device.
.sample_rate_shading(true);
// ...
}
// ...
unsafe fn create_pipeline(device: &Device, data: &mut AppData) -> Result<()> {
// ...
let multisample_state = vk::PipelineMultisampleStateCreateInfo::builder()
// Enable sample shading in the pipeline.
.sample_shading_enable(true)
// Minimum fraction for sample shading; closer to one is smoother.
.min_sample_shading(0.2)
.rasterization_samples(data.msaa_samples);
// ...
}在这个例子中,我们将采样着色保持禁用。但在某些情况下,采样着色可以带来显著的质量提升:

推送常量
原文链接:https://kylemayes.github.io/vulkanalia/dynamic/push_constants.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
前面没有这个声明的章节都是直接从 https://github.com/Overv/VulkanTutorial 改编而来。
这一章和后面的章节都是原创,作者并不是 Vulkan 的专家。作者尽力保持了权威的语气,但是这些章节应该被视为一个 Vulkan 初学者的“尽力而为”。
如果你有问题、建议或者修正,请提交 issue!
本章代码:main.rs | shader.vert | shader.frag
目前为止我们在教程中创建的场景都是静态的。虽然我们可以操作提供模型、视图和投影(MVP)矩阵的 uniform 缓冲来旋转和移动模型,但是我们不能改变渲染什么。这是因为程序在初始化的过程中分配和记录指令缓冲的时候就已经决定了要渲染什么。
在接下来的几章中,我们将会探索多种用于渲染动态场景的技巧。我们首先来看一下推送常量,这是 Vulkan 的一个特性,它允许我们轻松高效地“推送”动态数据到着色器。仅靠推送常量本身并不能实现动态场景,但是在接下来的几章中,你会逐渐明白它的用处。
推式常量与 uniform 缓冲
之前我们已经在使用另一种能将动态数据提供给顶点着色器的 Vulkan 特性了:那就是 uniform 缓冲。在渲染每一帧时,App::update_uniform_buffer 方法都会根据模型当前的旋转角度计算出新的 MVP 矩阵,并将这些矩阵复制到 uniform 缓冲中。然后顶点着色器从 uniform 缓冲中读取这些矩阵,以确定模型的顶点在屏幕上的位置。
目前为止这种方法工作得很好,那么为什么我们要用推送常量取而代之呢?相比于 uniform 缓冲,推送常量的优势之一是速度:更新推送常量比复制新数据到 uniform 缓冲要快得多。如果有大量需要频繁更新的值,这种差异会很快累积起来。
当然,这里有一个限制:使用推送常量提供给着色器的数据量有一个非常有限的最大值。这个最大值因设备而异,由 vk::PhysicalDeviceLimits 的 max_push_constants_size 字段以字节为单位指定。Vulkan 要求这个限制至少为128字节(见表 32),但实际设备上的最大值也不会比 128 高多少。即使是 RTX 3080 这样的高端硬件,这个最大值也只有 256 字节。
如果我们想用推送常量来向矩阵提供我们的 MVP 矩阵,那么我们马上就会撞到这个限制。MVP 矩阵太大了,无法被可靠地放入推送常量中:每个矩阵是 64 字节(16 × 4 字节浮点数),总共 192 字节。当然,我们可以写两套代码,一套用于处理推送常量 >= 192 字节的设备,另一套用于处理无法满足这个需求的设备,但是我们还有更简单的方法。
一种方法就是将 MVP 矩阵预先相乘,获得一个单独的矩阵。另一种方法是只将模型矩阵作为推送常量提供,而将视图和投影矩阵留在 uniform 缓冲中。这两种方法都可以为我们提供至少 64 字节的余量。在本章中,我们将采用第二种方法来探索推送常量。
为什么只将推送常量用于模型矩阵呢?在 App::update_uniform_buffer 方法中,你可以注意到 model 矩阵随着 time 的增加,在每一帧中都会有所改变,而 view 矩阵是静态的,proj 矩阵则只会在窗口大小发生变化的时候改变。这就使得我们可以只在窗口大小发生变化时更新包含视图和投影矩阵的 uniform 缓冲,而将推送常量用于不断变化的模型矩阵。
当然,在实际的应用程序中,视图矩阵不太可能是静态的。例如,如果你在构建一个第一人称游戏,view 矩阵可能会随着玩家在游戏世界中移动而快速变化。然而,即使视图和投影矩阵每一帧都发生改变,至少它们也会在你渲染的所有模型之间共享。也就是说你可以在每一帧中更新 uniform 缓冲,以提供共享的视图和投影矩阵,并使用推送常量来为场景中每个模型提供模型矩阵。
推送模型矩阵
文字部分就到这里,现在让我们开始吧,将顶点着色器中的模型矩阵从 uniform 缓冲对象移动到推送常量中。别忘了重新编译顶点着色器!
#version 450
layout(binding = 0) uniform UniformBufferObject {
mat4 view;
mat4 proj;
} ubo;
layout(push_constant) uniform PushConstants {
mat4 model;
} pcs;
// ...
void main() {
gl_Position = ubo.proj * ubo.view * pcs.model * vec4(inPosition, 1.0);
// ...
}
注意不同于 uniform 缓冲对象,推送常量的布局是 push_constant,而不是像 push_constant = 0 这样的东西。这是因为我们在调用图形管线时只能提供一个推送常量集合,并且如上所述,这个集合非常有限。
从 UniformBufferObject 结构体中移除 model,因为从现在开始我们会为模型矩阵使用推送常量。
#[repr(C)]
#[derive(Copy, Clone, Debug)]
struct UniformBufferObject {
view: Mat4,
proj: Mat4,
}Also remove model from the App::update_command_buffers method.
同时从 App::update_command_buffers 方法中移除 model。
let view = Mat4::look_at_rh(
point3(2.0, 2.0, 2.0),
point3(0.0, 0.0, 0.0),
vec3(0.0, 0.0, 1.0),
);
let correction = Mat4::new(
1.0, 0.0, 0.0, 0.0,
0.0, -1.0, 0.0, 0.0,
0.0, 0.0, 1.0 / 2.0, 0.0,
0.0, 0.0, 1.0 / 2.0, .0,
);
let proj = correction * cgmath::perspective(
Deg(45.0),
self.data.swapchain_extent.width as f32 / self.data.swapchain_extent.height as f32,
0.1,
10.0,
);
let ubo = UniformBufferObject { view, proj };
// ...我们需要更新图形管线的布局,将我们的新推送常量告知 Vulkan。在 create_pipeline 函数中,你可以看到我们之前已经将描述符集合布局提供给了 create_pipeline_layout。描述符集合布局描述了我们着色器中使用的 uniform 缓冲对象和纹理采样器,而现在我们需要使用推送常量范围 vk::PushConstantRange 来描述图形管线中着色器将要访问的推送常量。
let vert_push_constant_range = vk::PushConstantRange::builder()
.stage_flags(vk::ShaderStageFlags::VERTEX)
.offset(0)
.size(64 /* 16 × 4 byte floats */);
let set_layouts = &[data.descriptor_set_layout];
let push_constant_ranges = &[vert_push_constant_range];
let layout_info = vk::PipelineLayoutCreateInfo::builder()
.set_layouts(set_layouts)
.push_constant_ranges(push_constant_ranges);
data.pipeline_layout = device.create_pipeline_layout(&layout_info, None)?;这里的推送常量范围说明了顶点着色器访问的推送常量可以在提供给图形管线的推送常量的开头找到,大小相当于一个 mat4。
有了这些,我们就可以开始将模型矩阵推送到顶点着色器了。推送常量会被直接记录到提交给 GPU 的指令缓冲中,这就是为什么它们如此快速,这也解释了为什么它们的大小如此有限。
在 create_command_buffers 函数中,定义一个模型矩阵,并在我们记录绘制指令之前,使用 cmd_push_constants 将其作为推送常量添加到指令缓冲中。
let model = Mat4::from_axis_angle(
vec3(0.0, 0.0, 1.0),
Deg(0.0)
);
let model_bytes = std::slice::from_raw_parts(
&model as *const Mat4 as *const u8,
size_of::<Mat4>()
);
for (i, command_buffer) in data.command_buffers.iter().enumerate() {
// ...
device.cmd_push_constants(
*command_buffer,
data.pipeline_layout,
vk::ShaderStageFlags::VERTEX,
0,
model_bytes,
);
device.cmd_draw_indexed(*command_buffer, data.indices.len() as u32, 1, 0, 0, 0);
// ...
}如果你现在运行程序,你会看到熟悉的模型,但是它不再旋转了!我们不再在每一帧中更新 uniform 缓冲对象中的模型矩阵,而是将其编码到指令缓冲中,正如之前所讨论的,指令缓冲永远不会被更新。这进一步凸显了以某种方式更新指令缓冲的需求,这个话题将在下一章中讨论。现在,让我们在片元着色器中再添加一个推送常量,然后结束本章。
推送透明度
接下来我们将在片元着色器中添加一个推送常量,我们可以用它来控制模型的不透明度。首先修改片元着色器,将推送常量包含进去,并将其用作片元颜色的 alpha 通道。同样,一定要重新编译着色器!
#version 450
layout(binding = 1) uniform sampler2D texSampler;
layout(push_constant) uniform PushConstants {
layout(offset = 64) float opacity;
} pcs;
// ...
void main() {
outColor = vec4(texture(texSampler, fragTexCoord).rgb, pcs.opacity);
}
这次我们为推送常量值指定了一个偏移量。记住,推送常量在图形管线中的所有着色器之间是共享的,所以我们需要考虑到推送常量的前 64 字节已经被顶点着色器中使用的模型矩阵占用了。
在管线布局中为新的不透明度推送常量添加一个推送常量范围。
let vert_push_constant_range = vk::PushConstantRange::builder()
.stage_flags(vk::ShaderStageFlags::VERTEX)
.offset(0)
.size(64 /* 16 × 4 byte floats */);
let frag_push_constant_range = vk::PushConstantRange::builder()
.stage_flags(vk::ShaderStageFlags::FRAGMENT)
.offset(64)
.size(4);
let set_layouts = &[data.descriptor_set_layout];
let push_constant_ranges = &[vert_push_constant_range, frag_push_constant_range];
let layout_info = vk::PipelineLayoutCreateInfo::builder()
.set_layouts(set_layouts)
.push_constant_ranges(push_constant_ranges);
data.pipeline_layout = device.create_pipeline_layout(&layout_info, None)?;最后,在 create_command_buffers 中,在为模型矩阵调用 cmd_push_constants 之后,再添加一个 cmd_push_constants 的调用。
device.cmd_push_constants(
*command_buffer,
data.pipeline_layout,
vk::ShaderStageFlags::VERTEX,
0,
model_bytes,
);
device.cmd_push_constants(
*command_buffer,
data.pipeline_layout,
vk::ShaderStageFlags::FRAGMENT,
64,
&0.25f32.to_ne_bytes()[..],
);
device.cmd_draw_indexed(*command_buffer, data.indices.len() as u32, 1, 0, 0, 0);这里我们通过在模型矩阵的 64 字节之后将不透明度 0.25 记录到指令缓冲中,来向片元着色器提供不透明度。然而,如果你现在运行程序,你会发现模型仍然完全不透明!
回看固定功能那一章,我们讨论过如果要渲染透明几何体,就需要设置阿尔法合成。然而,那时我们禁用了阿尔法合成。所以现在我们要在 create_pipeline 函数中,更新 vk::PipelineColorBlendAttachmentState,以启用阿尔法合成,就像那一章中描述的那样。
let attachment = vk::PipelineColorBlendAttachmentState::builder()
.color_write_mask(vk::ColorComponentFlags::all())
.blend_enable(true)
.src_color_blend_factor(vk::BlendFactor::SRC_ALPHA)
.dst_color_blend_factor(vk::BlendFactor::ONE_MINUS_SRC_ALPHA)
.color_blend_op(vk::BlendOp::ADD)
.src_alpha_blend_factor(vk::BlendFactor::ONE)
.dst_alpha_blend_factor(vk::BlendFactor::ZERO)
.alpha_blend_op(vk::BlendOp::ADD);运行程序,看看我们现在幽灵一般的模型。

成功了!
重用指令缓冲
原文链接:https://kylemayes.github.io/vulkanalia/dynamic/recycling_command_buffers.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
这一章和后面的章节都是原创,作者并不是 Vulkan 的专家。作者尽力保持了权威的语气,但是这些章节应该被视为一个 Vulkan 初学者的“尽力而为”。
如果你有问题、建议或者修正,请提交 issue!
本章代码:main.rs
当你分配指令缓冲并在其中记录指令的时候,Vulkan 会分配一块内存来存储指令缓冲的信息和已经记录到其中的指令。现在我们想要每一帧都记录不同的指令,我们需要回收这块内存,就像在 C 语言中我们需要在不再使用 malloc 分配的内存时使用 free 一样。
解决方案
Vulkan 为重用指令缓冲的内存提供了三种基本的方式
- 重置指令缓冲(这会清除其中已经记录的指令),然后向指令缓冲中记录新的指令
- 释放指令缓冲(这会将内存返还给指令池),然后重新分配一个指令缓冲
- 重置指令池(这会重置所有从这个指令池中分配的指令缓冲),然后向指令缓冲中记录新的指令
让我们看看实现这三种方法分别需要做什么。
1. 重置指令缓冲
默认情况下,指令缓冲是不可重置的,一旦记录了指令,它们就是不可变的。重置指令缓冲的能力是一个选项,必须在创建指令池时启用,这个选项会应用到从这个指令池分配的所有指令缓冲。在 create_command_pool 中,为指令池创建信息添加 vk::CommandPoolCreateFlags::RESET_COMMAND_BUFFER 标志。
let info = vk::CommandPoolCreateInfo::builder()
.flags(vk::CommandPoolCreateFlags::RESET_COMMAND_BUFFER)
.queue_family_index(indices.graphics);
data.command_pool = device.create_command_pool(&info, None)?;接着,为 App 结构体创建一个新的方法 update_command_buffer。这个方法会在每一帧被调用,用来重置并重新记录当前帧使用的帧缓冲的指令缓冲。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
Ok(())
}在 render 方法中,在更新帧的 uniform 缓冲之前(或者之后,这两个语句的顺序不重要)调用这个新方法。
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.update_command_buffer(image_index)?;
self.update_uniform_buffer(image_index)?;
// ...
}注意在调用 update_command_buffer 时要多加小心。如果一个指令缓冲仍然在渲染一个之前已经提交的帧,重置这个指令缓冲会引发严重的问题。这个问题在 Descriptor set layout and buffer 章节中也有讨论,这也是为什么我们在这里调用 App::update_uniform_buffer。正如在那一章中详细讨论的那样,这两个函数都是在调用 wait_for_fences 之后被调用的,wait_for_fences 会等待 GPU 用完获取到的交换链图像及其相关资源,所以我们可以放心地对指令缓冲做任何事情。
在这个新方法中,调用 reset_command_buffer 来重置指令缓冲。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
let command_buffer = self.data.command_buffers[image_index];
self.device.reset_command_buffer(
command_buffer,
vk::CommandBufferResetFlags::empty(),
)?;
Ok(())
}一旦 reset_command_buffer 返回,指令缓冲就会被重置回初始状态,和从指令池中新分配的指令缓冲没有什么区别。
现在我们可以将记录指令缓冲的代码从 create_command_buffers 移动到 update_command_buffer 中。我们不需要再循环遍历指令缓冲了,因为我们每一帧只记录一个指令缓冲。除此之外,只需要做一些机械的修改就可以将这段代码迁移到我们的新方法中(例如,将对循环计数器 i 的引用替换为 image_index)。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
// ...
let model = Mat4::from_axis_angle(
vec3(0.0, 0.0, 1.0),
Deg(0.0)
);
let model_bytes = &*slice_from_raw_parts(
&model as *const Mat4 as *const u8,
size_of::<Mat4>()
);
let info = vk::CommandBufferBeginInfo::builder();
self.device.begin_command_buffer(command_buffer, &info)?;
let render_area = vk::Rect2D::builder()
.offset(vk::Offset2D::default())
.extent(self.data.swapchain_extent);
let color_clear_value = vk::ClearValue {
color: vk::ClearColorValue {
float32: [0.0, 0.0, 0.0, 1.0],
},
};
let depth_clear_value = vk::ClearValue {
depth_stencil: vk::ClearDepthStencilValue { depth: 1.0, stencil: 0 },
};
let clear_values = &[color_clear_value, depth_clear_value];
let info = vk::RenderPassBeginInfo::builder()
.render_pass(self.data.render_pass)
.framebuffer(self.data.framebuffers[image_index])
.render_area(render_area)
.clear_values(clear_values);
self.device.cmd_begin_render_pass(command_buffer, &info, vk::SubpassContents::INLINE);
self.device.cmd_bind_pipeline(command_buffer, vk::PipelineBindPoint::GRAPHICS, self.data.pipeline);
self.device.cmd_bind_vertex_buffers(command_buffer, 0, &[self.data.vertex_buffer], &[0]);
self.device.cmd_bind_index_buffer(command_buffer, self.data.index_buffer, 0, vk::IndexType::UINT32);
self.device.cmd_bind_descriptor_sets(
command_buffer,
vk::PipelineBindPoint::GRAPHICS,
self.data.pipeline_layout,
0,
&[self.data.descriptor_sets[image_index]],
&[],
);
self.device.cmd_push_constants(
command_buffer,
self.data.pipeline_layout,
vk::ShaderStageFlags::VERTEX,
0,
model_bytes,
);
self.device.cmd_push_constants(
command_buffer,
self.data.pipeline_layout,
vk::ShaderStageFlags::FRAGMENT,
64,
&0.25f32.to_ne_bytes()[..],
);
self.device.cmd_draw_indexed(command_buffer, self.data.indices.len() as u32, 1, 0, 0, 0);
self.device.cmd_end_render_pass(command_buffer);
self.device.end_command_buffer(command_buffer)?;
Ok(())
}有了这些修改,我们的程序现在可以每一帧执行不同的渲染指令,这样就可以实现动态场景了!让我们通过将模型矩阵的计算恢复到旧的状态来练习这个新功能。在 App::update_command_buffer 中,将模型矩阵的计算替换为旧的计算,这样就可以让模型随着时间旋转。
let time = self.start.elapsed().as_secs_f32();
let model = Mat4::from_axis_angle(
vec3(0.0, 0.0, 1.0),
Deg(90.0) * time
);
let model_bytes = &*slice_from_raw_parts(
&model as *const Mat4 as *const u8,
size_of::<Mat4>()
);运行程序,你会发现模型现在又开始旋转了,因为我们每一帧都向着色器推送了一个更新的模型矩阵。

最后,既然我们现在只在重置指令缓冲之前提交一次指令缓冲,我们应该让 Vulkan 知道这一点,这样它就可以更好地理解我们程序的行为。在开始记录指令缓冲时,传递 vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT 标志就可以实现这一点。
let info = vk::CommandBufferBeginInfo::builder()
.flags(vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT);
self.device.begin_command_buffer(command_buffer, &info)?;你可能还记得我们之前在 begin_single_time_commands 函数中使用过这个标志。Vulkan 并不强制要求使用这个标志,但如果你只在重置或释放指令缓冲之前使用一次指令缓冲,有了这个标志提供的信息,Vulkan 驱动或许能更好地优化对一次性指令缓冲的处理。
2. 重新分配指令缓冲
接着我们来看看每一帧都重新分配指令缓冲要怎么做。
移除我们刚才在 update_command_buffer 开头重置指令缓冲的代码。添加以下代码,用新的指令缓冲替换旧的指令缓冲:
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
let allocate_info = vk::CommandBufferAllocateInfo::builder()
.command_pool(self.data.command_pool)
.level(vk::CommandBufferLevel::PRIMARY)
.command_buffer_count(1);
let command_buffer = self.device.allocate_command_buffers(&allocate_info)?[0];
self.data.command_buffers[image_index] = command_buffer;
// ...
}现在你可以运行程序,你会发现程序的运行效果和之前完全一样,但是如果你让它多运行一会,就会发现问题了!你可能已经注意到了,在分配新的指令缓冲之前,我们并没有释放之前的指令缓冲。如果你观察这个修改后的程序的内存使用情况,你会发现内存使用量迅速上升,因为很快就会出现数千个被遗弃的指令缓冲,而这些指令缓冲永远不会被回收。
在 update_command_buffer 的开头释放原先的指令缓冲,将其使用的内存返还给指令池。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
let previous = self.data.command_buffers[image_index];
self.device.free_command_buffers(self.data.command_pool, &[previous]);
// ...
}现在运行程序,你会发现内存使用量稳定了下来,而不是像 Electron 应用一样吃光系统上所有的内存。
现在我们不再需要 vk::CommandPoolCreateFlags::RESET_COMMAND_BUFFER 标志了,因为我们不再重置指令池了。保留这个标志不会影响我们程序的正确性,但是它可能会对性能产生负面影响,因为它会强制指令池以可以重置的方式分配指令缓冲。
我们把标志换成 vk::CommandPoolCreateFlags::TRANSIENT,这会告诉 Vulkan,我们将使用这个指令池分配的指令缓冲是“稍纵即逝的”,也就是说,这些指令缓冲会非常短命。
let info = vk::CommandPoolCreateInfo::builder()
.flags(vk::CommandPoolCreateFlags::TRANSIENT)
.queue_family_index(indices.graphics);
data.command_pool = device.create_command_pool(&info, None)?;和 vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT 一样,这个标志不会影响我们程序的正确性,但是它可能会让 Vulkan 驱动更好地优化对短命的指令缓冲的处理。
3. 重置指令池
接着我们来看看重置整个指令池,这会一举重置所有活动的指令缓冲。
然而,我们立刻就遇到了一个问题。我们不能每一帧都重置所有的指令缓冲,因为有些指令缓冲可能仍然在使用中!App::render 中的 wait_for_fences 调用确保我们可以安全地重置当前帧缓冲的指令缓冲,但是可能还有其他指令缓冲仍然在使用中。
我们可以继续沿着这条路走下去,但这样的话我们的程序就不能并行渲染多个帧了。保持多帧并行渲染的能力很重要,因为正如在渲染与呈现那一章提到的,这可以让我们更好地利用硬件:CPU 会花费更少的时间等待 GPU,反之亦然。
我们会选择另一种方式,为每个帧缓冲维护一个单独的指令池。这样我们就可以自由地重置当前帧缓冲关联的指令池,而不用担心会破坏任何仍在渲染中的之前提交的帧。
你可能会觉得这有点高射炮打蚊子,为什么仅仅为了每次只重置一个指令缓冲,就要创建多个单独的指令池呢?在每一帧中释放或者重置指令缓冲不是更简单,而且或许还能更快吗?这只是一个教学练习吗?本教程的作者是个骗子吗?
为了让你能够放心地暂时搁置这些问题(好吧,也许不包括最后一个问题),让我们来预览一下下一章的内容。下一章将涉及每一帧管理多个指令缓冲,而不是我们到目前为止一直在使用的每一帧一个指令缓冲。那么,通过重置指令池一次性释放所有这些指令缓冲,程序将变得更简单,而且或许还会更快。
我们将保留现有的这个指令池,因为它会在程序初始化期间被用来分配指令缓冲。在 AppData 中添加一个字段,为每个帧缓冲保存一个指令池,并将现有的 create_command_pool 函数重命名为 create_command_pools,以反映它新增加的职能。
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_command_pools(&instance, &device, &mut data)?;
// ...
}
}
struct AppData {
// ...
command_pools: Vec<vk::CommandPool>,
command_buffers: Vec<vk::CommandBuffer>,
// ...
}
unsafe fn create_command_pools(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
// ...
}创建一个新的 create_command_pool 函数,用来创建一个指令池,这个指令池会被用于创建可以提交到图形队列的、短命的指令缓冲。
unsafe fn create_command_pool(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<vk::CommandPool> {
let indices = QueueFamilyIndices::get(instance, data, data.physical_device)?;
let info = vk::CommandPoolCreateInfo::builder()
.flags(vk::CommandPoolCreateFlags::TRANSIENT)
.queue_family_index(indices.graphics);
Ok(device.create_command_pool(&info, None)?)
}有了这个函数,我们可以很容易地更新 create_command_pools,来创建我们现有的全局指令池和新的每帧指令池。
unsafe fn create_command_pools(
instance: &Instance,
device: &Device,
data: &mut AppData,
) -> Result<()> {
data.command_pool = create_command_pool(instance, device, data)?;
let num_images = data.swapchain_images.len();
for _ in 0..num_images {
let command_pool = create_command_pool(instance, device, data)?;
data.command_pools.push(command_pool);
}
Ok(())
}现在我们需要使用这些新的每帧指令池来创建指令缓冲。更新 create_command_buffers,为每个指令缓冲使用一个单独的 allocate_command_buffers 调用,这样每个指令缓冲就可以关联到一个每帧指令池。
unsafe fn create_command_buffers(device: &Device, data: &mut AppData) -> Result<()> {
let num_images = data.swapchain_images.len();
for image_index in 0..num_images {
let allocate_info = vk::CommandBufferAllocateInfo::builder()
.command_pool(data.command_pools[image_index])
.level(vk::CommandBufferLevel::PRIMARY)
.command_buffer_count(1);
let command_buffer = device.allocate_command_buffers(&allocate_info)?[0];
data.command_buffers.push(command_buffer);
}
Ok(())
}更新 App::update_command_buffer,重置每帧指令池,而不是释放并重新分配指令缓冲。这也会重置使用这个指令池创建的任何指令缓冲,所以我们不需要做任何其他事情,就可以重用指令缓冲。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
let command_pool = self.data.command_pools[image_index];
self.device.reset_command_pool(command_pool, vk::CommandPoolResetFlags::empty())?;
let command_buffer = self.data.command_buffers[image_index];
// ...
}现在运行程序,确保新的指令缓冲重用策略仍然会产生和之前一样的结果。如果你启用了校验层,当程序关闭时,校验层会提醒我们没有清理这些新的指令池。更新 App::destroy,销毁它们。
unsafe fn destroy(&mut self) {
self.destroy_swapchain();
self.data.command_pools
.iter()
.for_each(|p| self.device.destroy_command_pool(*p, None));
// ...
}最后,在 App::destroy_swapchain 中删除对 free_command_buffers 的调用。这个调用会错误地尝试将分配给每帧指令缓冲的内存返还给全局指令池,而现在这些指令缓冲并不是从全局指令池指令池分配的。如果保留这段代码,当窗口大小改变或者强制重新创建交换链时,我们的程序很可能会崩溃。我们不再需要管理单个指令缓冲的删除,因为我们现在是在指令池级别管理这个。
结论
现在我们已经探索了 Vulkan 提供的重用指令缓冲的基本方式,现在我们可以动态地改变程序提交的指令,无论是为了响应用户输入还是响应其他信号。这些方法可以以任何你能想象的方式被组合使用,这也恰恰展示了 Vulkan 赋予程序员的强大和灵活性。
如果你对于如何在指令池和指令缓冲方面设计 Vulkan 程序感到有点不知所措,不要担心!下一章会让事情变得更加复杂。
次级指令缓冲
原文链接:https://kylemayes.github.io/vulkanalia/dynamic/secondary_command_buffers.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
这一章和后面的章节都是原创,作者并不是 Vulkan 的专家。作者尽力保持了权威的语气,但是这些章节应该被视为一个 Vulkan 初学者的“尽力而为”。
如果你有问题、建议或者修正,请提交 issue!
本章代码:main.rs
现在我们的程序会在每一帧提交不同的指令,但是我们还没有达到我们的最初目标:动态地改变程序渲染的内容。在这一章中,我们将修改我们的程序,使其能够根据用户输入渲染 1 到 4 个模型实例。
我们将运用次级指令缓冲来实现这个功能。次级指令缓冲是一个 Vulkan 特性,可以用来构建可重用的指令序列,然后我们就可以从主指令缓冲中执行这些指令。实现这个功能并不是一定要使用次级指令缓冲,但是这是我们第一次渲染多个物体,正好可以介绍一下它。
主指令缓冲 vs 次级指令缓冲
目前为止我们只用过主指令缓冲,也就是可以被直接提交到 Vulkan 队列并在设备上执行的指令缓冲。次级指令缓冲则不能被提交到队列,而是会被主指令缓冲调用并间接地执行。
使用次级指令缓冲有两个主要的优点:
- 次级指令缓冲可以被并行地分配和记录,这样你就可以更好地利用现代硬件的众多 CPU 核心
- 次级指令缓冲的生存期可以独立地管理,这样你就可以同时拥有长期或永久的次级指令缓冲和经常更新的次级指令缓冲,从而减少每一帧需要创建的指令缓冲的数量
这两点对主指令缓冲也是成立的,但是主指令缓冲有一个重大的限制,导致它不能利用这些优势。多个主指令缓冲无法在同一个渲染流程中同时执行,也就是说如果你想在一帧中执行多个主指令缓冲,每个主指令缓冲都需要以 cmd_begin_render_pass 开始,以 cmd_end_render_pass 结束。
这听起来不是什么大问题,但是开始一个渲染流程实例是一个非常耗费资源的操作,而且如果每一帧都需要多次开始渲染流程,那么性能就会在某些硬件上大幅下降。次级指令缓冲可以从调用它的主指令缓冲那里继承渲染流程实例以及其他状态,从而避免了这个问题。
多个模型实例
我们从给 AppData 添加一个字段开始,这个字段将包含我们新的次级指令缓冲。我们每一帧都会有多个次级指令缓冲,每个次级指令缓冲都对应一个我们正在渲染的模型实例,所以这个字段是一个列表的列表。
struct AppData {
// ...
command_buffers: Vec<vk::CommandBuffer>,
secondary_command_buffers: Vec<Vec<vk::CommandBuffer>>,
// ...
}在真实的应用程序中,我们在一帧中需要渲染的次级指令缓冲的数量可能会随着时间的推移而显著变化。此外,我们可能不会提前知道应用程序最多需要多少个次级指令缓冲。
在这个例子里我们其实是知道最大值的,但我们假装不知道,并且采取一个更接近真实应用程序的方法。我们不会像分配主指令缓冲那样在初始化时分配次级指令缓冲,而是在需要时分配次级指令缓冲。我们仍然需要用空的次级指令缓冲列表填充外部的 Vec,所以我们需要更新 create_command_buffers 来实现这一点。
unsafe fn create_command_buffers(device: &Device, data: &mut AppData) -> Result<()> {
// ...
data.secondary_command_buffers = vec![vec![]; data.swapchain_images.len()];
Ok(())
}为 App 新增一个 update_secondary_command_buffer 方法,我们将会用这个方法来(在需要时)为我们将要渲染的 4 个模型实例之一分配并记录次级指令缓冲。model_index 参数表示次级指令缓冲应该渲染的 4 个模型实例中的哪一个。
unsafe fn update_secondary_command_buffer(
&mut self,
image_index: usize,
model_index: usize,
) -> Result<vk::CommandBuffer> {
self.data.secondary_command_buffers.resize_with(image_index + 1, Vec::new);
let command_buffers = &mut self.data.secondary_command_buffers[image_index];
while model_index >= command_buffers.len() {
let allocate_info = vk::CommandBufferAllocateInfo::builder()
.command_pool(self.data.command_pools[image_index])
.level(vk::CommandBufferLevel::SECONDARY)
.command_buffer_count(1);
let command_buffer = self.device.allocate_command_buffers(&allocate_info)?[0];
command_buffers.push(command_buffer);
}
let command_buffer = command_buffers[model_index];
let info = vk::CommandBufferBeginInfo::builder();
self.device.begin_command_buffer(command_buffer, &info)?;
self.device.end_command_buffer(command_buffer)?;
Ok(command_buffer)
}这些代码将会为模型实例在需要时分配次级指令缓冲,但是在初次分配后会重用它们。和主指令缓冲一样,我们可以自由地使用任何之前分配的次级指令缓冲,因为我们正在重置它们所分配的指令池。
在开始记录次级指令缓冲之前,我们需要向 Vulkan 提供一些次级指令缓冲特有的额外信息。创建一个 vk::CommandBufferInheritanceInfo 实例,指定将与次级指令缓冲一起使用的渲染流程、子流程索引和帧缓冲,然后将这个继承信息提供给 begin_command_buffer。
let inheritance_info = vk::CommandBufferInheritanceInfo::builder()
.render_pass(self.data.render_pass)
.subpass(0)
.framebuffer(self.data.framebuffers[image_index]);
let info = vk::CommandBufferBeginInfo::builder()
.inheritance_info(&inheritance_info);
self.device.begin_command_buffer(command_buffer, &info)?;正如我们之前所提到的,次级指令缓冲可以从执行它的主指令缓冲那里继承一些状态。这个继承信息描述了次级指令缓冲将与哪些指令缓冲状态兼容,并合法地继承它们。
要继承指令缓冲状态,渲染流程和子流程索引是必填项目。而帧缓冲则是可选的,你可以省略它,但提供它的话 Vulkan 或许能够更好地优化次级指令缓冲。
这还不足以实际地继承渲染流程,我们还需要将 vk::CommandBufferUsageFlags::RENDER_PASS_CONTINUE 提供给 begin_command_buffer。这告诉 Vulkan 这个次级指令缓冲将完全在渲染流程内执行。
let info = vk::CommandBufferBeginInfo::builder()
.flags(vk::CommandBufferUsageFlags::RENDER_PASS_CONTINUE)
.inheritance_info(&inheritance_info);
self.device.begin_command_buffer(command_buffer, &info)?;将计算推送常量值的代码从 App::update_command_buffer 移动到 App::update_secondary_command_buffer 中分配次级指令缓冲之后。同时,让模型实例的不透明度取决于模型索引,范围从 25% 到 100%,以增加我们场景的多样性。
unsafe fn update_secondary_command_buffer(
&mut self,
image_index: usize,
model_index: usize,
) -> Result<vk::CommandBuffer> {
// ...
let command_buffer = self.device.allocate_command_buffers(&allocate_info)?[0];
let time = self.start.elapsed().as_secs_f32();
let model = Mat4::from_axis_angle(
vec3(0.0, 0.0, 1.0),
Deg(90.0) * time
);
let model_bytes = &*slice_from_raw_parts(
&model as *const Mat4 as *const u8,
size_of::<Mat4>()
);
let opacity = (model_index + 1) as f32 * 0.25;
let opacity_bytes = &opacity.to_ne_bytes()[..];
// ...
}接下来我们将把渲染指令从主指令缓冲移动到次级指令缓冲。主指令缓冲仍然会用于开始和结束渲染流程实例,因为它将被我们的次级指令缓冲继承,但是 App::update_command_buffer 中在 cmd_begin_render_pass 和 cmd_end_render_pass 之间(但不包括这两个指令)的所有指令都应该被移动到 App::update_secondary_command_buffer。
unsafe fn update_secondary_command_buffer(
&mut self,
image_index: usize,
model_index: usize,
) -> Result<vk::CommandBuffer> {
// ...
self.device.begin_command_buffer(command_buffer, &info)?;
self.device.cmd_bind_pipeline(command_buffer, vk::PipelineBindPoint::GRAPHICS, self.data.pipeline);
self.device.cmd_bind_vertex_buffers(command_buffer, 0, &[self.data.vertex_buffer], &[0]);
self.device.cmd_bind_index_buffer(command_buffer, self.data.index_buffer, 0, vk::IndexType::UINT32);
self.device.cmd_bind_descriptor_sets(
command_buffer,
vk::PipelineBindPoint::GRAPHICS,
self.data.pipeline_layout,
0,
&[self.data.descriptor_sets[image_index]],
&[],
);
self.device.cmd_push_constants(
command_buffer,
self.data.pipeline_layout,
vk::ShaderStageFlags::VERTEX,
0,
model_bytes,
);
self.device.cmd_push_constants(
command_buffer,
self.data.pipeline_layout,
vk::ShaderStageFlags::FRAGMENT,
64,
opacity_bytes,
);
self.device.cmd_draw_indexed(command_buffer, self.data.indices.len() as u32, 1, 0, 0, 0);
self.device.end_command_buffer(command_buffer)?;
// ...
}现在我们可以轻松地创建用于渲染模型实例的次级指令缓冲,在 App::update_command_buffers 中调用我们的新方法,并使用 cmd_execute_commands 执行返回的次级指令缓冲。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
// ...
self.device.cmd_begin_render_pass(command_buffer, &info, vk::SubpassContents::INLINE);
let secondary_command_buffer = self.update_secondary_command_buffer(image_index, 0)?;
self.device.cmd_execute_commands(command_buffer, &[secondary_command_buffer]);
self.device.cmd_end_render_pass(command_buffer);
// ...
}这个改变使我们的 cmd_begin_render_pass 调用失效了,因为我们之前提供了 vk::SubpassContents::INLINE,这表示我们将直接将渲染指令记录到主指令缓冲中。现在我们已经将渲染指令移动到了次级指令缓冲中,因此我们需要改用 vk::SubpassContents::SECONDARY_COMMAND_BUFFERS。
self.device.cmd_begin_render_pass(
command_buffer,
&info,
vk::SubpassContents::SECONDARY_COMMAND_BUFFERS,
);注意这是两种互斥的模式,你不能在渲染流程实例中混用次级指令缓冲和内联渲染指令。
如果你现在运行程序,你应该会看到和之前一样的幽灵模型在旋转。让我们通过创建 4 个次级指令缓冲并从主指令缓冲中执行它们来提高一下难度,渲染 4 个模型实例。
unsafe fn update_command_buffer(&mut self, image_index: usize) -> Result<()> {
// ...
self.device.cmd_begin_render_pass(command_buffer, &info, vk::SubpassContents::SECONDARY_COMMAND_BUFFERS);
let secondary_command_buffers = (0..4)
.map(|i| self.update_secondary_command_buffer(image_index, i))
.collect::<Result<Vec<_>, _>>()?;
self.device.cmd_execute_commands(command_buffer, &secondary_command_buffers[..]);
self.device.cmd_end_render_pass(command_buffer);
// ...
}如果你再次运行程序,你会看到 4 个模型实例在同样的坐标上发生了深度冲突,并因此产生了奇怪的闪烁。
修改 App::update_secondary_command_buffers 中计算模型矩阵的过程,使其在旋转模型之前根据模型索引将模型平移到不同的位置。
let y = (((model_index % 2) as f32) * 2.5) - 1.25;
let z = (((model_index / 2) as f32) * -2.0) + 1.0;
let time = self.start.elapsed().as_secs_f32();
let model = Mat4::from_translation(vec3(0.0, y, z)) * Mat4::from_axis_angle(
vec3(0.0, 0.0, 1.0),
Deg(90.0) * time
);这段代码将模型实例放置在 Y 轴和 Z 轴上的网格中。然而,由于我们使用的视图矩阵,相机是以 45 度的角度看着这个平面的,所以让我们在 App::update_uniform_buffer 中更新视图矩阵,使其直接看向 YZ 平面,以更好地查看我们的模型实例。
let view = Mat4::look_at_rh(
point3(6.0, 0.0, 2.0),
point3(0.0, 0.0, 0.0),
vec3(0.0, 0.0, 1.0),
);有了一个更好的视角,运行程序并享受它的荣耀吧。

让我们提高一下难度,允许用户决定他们想要渲染多少个模型。在构造函数中为 App 结构体添加一个 models 字段,并将其初始化为 1。
struct App {
// ...
models: usize,
}将 App::update_command_buffer 中的模型索引范围更新为从 0 到 models 字段的值。
let secondary_command_buffers = (0..self.models)
.map(|i| self.update_secondary_command_buffer(image_index, i))
.collect::<Result<Vec<_>, _>>()?;现在我们只需要再根据用户输入来增加和减少 models 字段的值。首先导入以下 winit 类型,我们将需要它们来处理键盘输入。
use winit::event::{ElementState, VirtualKeyCode};最后,在 main 函数的事件匹配块中添加一个处理按键的分支,当按下左箭头键时,将 models 减少 1(最少为 1),当按下右箭头键时,将 models 增加 1(最多为 4)。
match event {
// ...
Event::WindowEvent { event, .. } => match event {
// ...
WindowEvent::KeyboardInput { event, .. } => {
if event.state == ElementState::Pressed {
match event.physical_key {
PhysicalKey::Code(KeyCode::ArrowLeft) if app.models > 1 => app.models -= 1,
PhysicalKey::Code(KeyCode::ArrowRight) if app.models < 4 => app.models += 1,
_ => { }
}
}
}
}
// ...
}运行程序并观察,当你按下左右箭头键时,我们每一帧分配和执行的次级指令缓冲的数量会如何变化。

现在你应该已经熟悉了使用 Vulkan 高效渲染动态帧的基本工具。你可以通过多种方式使用这些工具,每种方式都有不同的性能权衡。未来的教程章节可能会更深入地探讨这个问题,但是使用多个线程并行地记录次级指令缓冲的工作是一种常见的技术,通常可以在现代硬件上获得显著的性能提升。
总结
原文链接:https://kylemayes.github.io/vulkanalia/conclusion.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
一路千辛万苦,我们终于有了一个基本的 Vulkan 程序。你现在已经掌握了 Vulkan 的基本原理,可以开始探索更多的特性了,比如:
- 实例化渲染
- 动态 uniform
- 分离图像和采样器描述符
- 管线缓存
- 多线程指令缓冲生成
- 多个子通道
- 计算着色器
现在的程序能被以多种形式扩展,比如添加 Blinn-Phong 光照、后处理效果和阴影映射。你应该能够从其他 API 的教程中学习到这些效果的工作原理,因为尽管 Vulkan 是显式的,但是很多概念仍然是相同的。