渲染与呈现
原文链接:https://kylemayes.github.io/vulkanalia/drawing/rendering_and_presentation.html
Commit Hash: 7becee96b0029bf721f833039c00ea2a417714dd
本章代码:main.rs
在本章中我们会把所有东西组合起来。我们将实现 App::render 函数,该函数会由主循环调用,将三角形渲染到屏幕上。
同步
App::render 函数会进行以下操作:
- 从交换链获取一张图像
- 使用该图像作为帧缓冲的附件,执行指令缓冲
- 将该图像返还到交换链,以供呈现
每个操作都是通过单个函数调用来启动的,但它们会异步地(asynchronously)执行。函数调用会在操作实际完成之前返回,且操作之间的执行顺序也是不确定的。然而很不幸的是,我们的每一步操作实际上都依赖于前一步操作的完成。
有两种方法可以用于同步交换链事件:信号量(semaphores)和栅栏(fences)。它们都是可以用于协调操作的对象,这是通过让一个操作发出信号、另一个操作等待信号量或栅栏的状态从未发出信号(unsignaled)变为已发出信号(signaled)来实现的。
区别在于,栅栏的状态可以通过 wait_for_fences 等函数从程序中访问,而信号量则不行。栅栏主要用于同步应用程序本身与渲染操作,而信号量则用于同步指令队列内或跨队列的操作。我们希望同步绘制指令和呈现操作,因此信号量是最佳选择。
信号量
我们需要两个信号量,一个用于传递图像已被获取并可以用于渲染的信号,另一个用于传递渲染已完成并可以进行呈现的信号。在 AppData 中创建两个字段来存储这些信号量对象:
struct AppData {
// ...
image_available_semaphore: vk::Semaphore,
render_finished_semaphore: vk::Semaphore,
}添加一个 create_sync_objects 函数来创建信号量:
impl App {
unsafe fn create(window: &Window) -> Result<Self> {
// ...
create_command_buffers(&device, &mut data)?;
create_sync_objects(&device, &mut data)?;
// ...
}
}
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
Ok(())
}创建信号量需要填充 vk::SemaphoreCreateInfo 结构体,不过在当前版本的 API 中它并没有任何必填字段。
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
let semaphore_info = vk::SemaphoreCreateInfo::builder();
Ok(())
}未来的 Vulkan API 或者扩展可能会为 flags 和 p_next 参数添加功能,就像它为其他结构体所做的那样。信号量的创建也是熟悉的模式:
data.image_available_semaphore = device.create_semaphore(&semaphore_info, None)?;
data.render_finished_semaphore = device.create_semaphore(&semaphore_info, None)?;信号量应该在程序结束时清理,这时候所有指令都已经完成,用不着再进行同步了:
unsafe fn destroy(&mut self) {
self.device.destroy_semaphore(self.data.render_finished_semaphore, None);
self.device.destroy_semaphore(self.data.image_available_semaphore, None);
// ...
}从交换链获取图像
正如我们之前所提到的,在 App::render 函数中要做的第一件事就是从交换链取得一张图像。回想一下,交换链是一个扩展特性,所以我们要用的函数带有 _khr 后缀。
unsafe fn render(&mut self, window: &Window) -> Result<()> {
let image_index = self
.device
.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphore,
vk::Fence::null(),
)?
.0 as usize;
Ok(())
}acquire_next_image_khr 的第一个参数是我们将要从中获取图像的交换链。第二个参数指定了一个以纳秒为单位的超时时间,使用 64 位无符号整数的最大值可以禁用超时。
下一个参数指定了在呈现引擎使用完图像后要发出信号的同步对象,可以是信号量或者栅栏,也可以两者都指定。我们将在这里使用 image_available_semaphore,它发出信号的时刻就是我们可以开始绘制的时候。
这个函数返回将会被获取的交换链图像的索引。这个索引指向 swapchain_images 数组中的 vk::Image。我们将使用这个索引来选择正确的指令缓冲。
提交指令缓冲
队列的提交和同步是通过 vk::SubmitInfo 结构体来配置的:
let wait_semaphores = &[self.data.image_available_semaphore];
let wait_stages = &[vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT];
let command_buffers = &[self.data.command_buffers[image_index as usize]];
let signal_semaphores = &[self.data.render_finished_semaphore];
let submit_info = vk::SubmitInfo::builder()
.wait_semaphores(wait_semaphores)
.wait_dst_stage_mask(wait_stages)
.command_buffers(command_buffers)
.signal_semaphores(signal_semaphores);前两个参数 wait_semaphores 和 wait_dst_stage_mask 指定在指令缓冲执行前要等待的信号量,以及在管线的哪个阶段等待。我们希望在图像可用之前不要写入颜色,因此我们指定了写入颜色附件的管线阶段。这意味着理论上来说实现可以进行若干优化,例如可以在图像还不可用的时候就开始执行我们的顶点着色器。wait_stages 数组中的每个条目都对应于 wait_semaphores 中相同索引的信号量。
下一个参数,command_buffers,指定了要提交执行的指令缓冲。正如之前提到的,我们应该提交绑定了我们刚获取的交换链图像的指令缓冲。
最后一个参数 signal_semaphores 指定了在指令缓冲执行完毕后要发出信号的信号量。在我们的例子中,我们使用 render_finished_semaphore。
self.device.queue_submit(
self.data.graphics_queue, &[submit_info], vk::Fence::null())?;现在我们可以用 queue_submit 来将指令缓冲提交到图形队列了。这个函数接受一个 vk::SubmitInfo 结构体的数组作为参数,这样做是为了在工作量很大的时候提高效率。最后一个参数引用了一个可选的栅栏,当指令缓冲执行完毕时会发出信号。我们已经在用信号量来进行同步了,因此我们只传递一个 vk::Fence::null()。
子流程依赖
还记得渲染流程中自动进行图像布局转换的子流程吗?这些转换是由子流程依赖(subpass dependencies)控制的,它们指定了子流程之间的内存和执行依赖关系。我们现在只有一个子流程,但是在这个子流程之前和之后的操作也被视为隐式的“子流程”。
有两个内建的子流程依赖能在渲染流程开始前和结束后进行布局转换,但前者进行转换的时机并不正确 —— 它假设转换发生在管线开始的时候,但在那个时候我们还没有获取到图像!有两种方法可以解决这个问题。我们可以将 image_available_semaphore 的 wait_stages 改为 vk::PipelineStageFlags::TOP_OF_PIPE,以确保图像可用之前渲染流程不会开始。或者,我们可以让渲染流程等待 vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT 阶段。我决定在这里使用第二种方法,因为这是个了解子流程依赖的工作原理的好机会。
子流程依赖是由 vk::SubpassDependency 结构体来指定的。在 create_render_pass 函数中添加一个:
let dependency = vk::SubpassDependency::builder()
.src_subpass(vk::SUBPASS_EXTERNAL)
.dst_subpass(0)
// continued...前两个字段 src_subpass 和 dst_subpass 指定了依赖和被依赖的子流程的索引。特殊值 vk::SUBPASS_EXTERNAL 指的是隐式子流程,它位于渲染流程开始前或结束后,具体的语义取决于它是在 src_subpass 还是 dst_subpass 中指定的。索引 0 指的是我们的子流程,也是唯一的子流程。dst_subpass 必须始终大于 src_subpass,以防止依赖图中出现循环(除非其中一个子流程是 vk::SUBPASS_EXTERNAL)。
.src_stage_mask(vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT)
.src_access_mask(vk::AccessFlags::empty())接下来的两个字段 src_stage_mask 和 src_access_mask 指定了要等待的操作,以及这些操作会在哪个阶段发生。我们需要等待交换链完成对图像的读取,然后才能访问它。这可以通过等待颜色附件输出阶段本身来实现。
.dst_stage_mask(vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT)
.dst_access_mask(vk::AccessFlags::COLOR_ATTACHMENT_WRITE);最后两个字段 dst_stage_mask 和 dst_access_mask 指定了哪些操作会等待这个子流程依赖,以及这些操作会在哪个阶段发生。上面的设置会阻止转换发生,直到我们真正需要(且允许)它发生的时候:当我们想要开始向图像写入颜色的时候。
let attachments = &[color_attachment];
let subpasses = &[subpass];
let dependencies = &[dependency];
let info = vk::RenderPassCreateInfo::builder()
.attachments(attachments)
.subpasses(subpasses)
.dependencies(dependencies);最后在 vk::RenderPassCreateInfo 的 dependencies 字段中指定这个依赖。
呈现
绘制一帧的最后异步就是将结果提交回交换链,让它最终显示在屏幕上。我们在 App::render 函数末尾添加一个 vk::PresentInfoKHR 结构体来配置呈现:
let swapchains = &[self.data.swapchain];
let image_indices = &[image_index as u32];
let present_info = vk::PresentInfoKHR::builder()
.wait_semaphores(signal_semaphores)
.swapchains(swapchains)
.image_indices(image_indices);第一个参数指定了在呈现之前要等待的信号量,就像 vk::SubmitInfo 一样。
接下来的两个参数指定了要呈现图像的交换链,以及交换链的图像索引。这里几乎总是只有一张交换链图像。
还有一个可选的 result 参数,可以指定一个 vk::Result 数组,用于检查每个交换链的呈现是否成功。如果你只使用单个交换链,那么这个参数是不必要的,因为你可以直接使用呈现函数的返回值。
self.device.queue_present_khr(self.data.present_queue, &present_info)?;queue_present_khr 函数提交了一个请求,要求将图像呈现到交换链中。我们将在下一章修改 acquire_next_image_khr 和 queue_present_khr 的错误处理,因为它们的失败并不一定意味着应该终止程序,这与我们迄今为止所见到的函数不同。
如果你之前的工作都没有问题,那么现在你应该可以看到类似下面这样的东西:
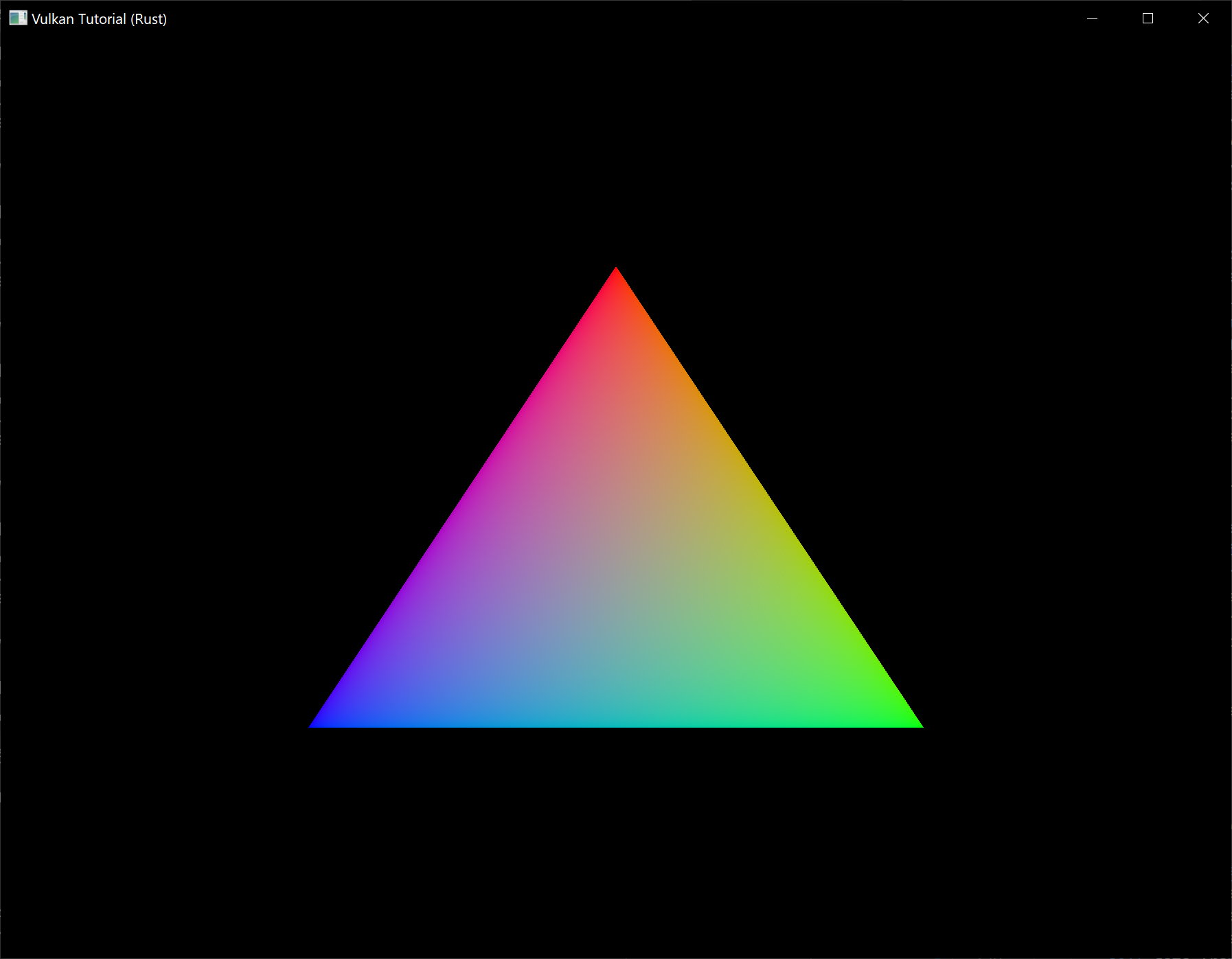
这个彩色三角形看上去可能和你在其他图形学教程中看到过的略有不同。这是因为本教程让着色器在线性颜色空间中进行插值,然后再转换到 sRGB 颜色空间。参见这篇博客来了解这两种颜色空间的区别。
好耶!然而不幸的是,当启用校验层时,程序在你关闭它的时候会崩溃。从 debug_callback 打印到终端的消息告诉了我们原因:

还记得吗?我们说过 App::render 中的所有操作都是异步的。也就是说,当我们在 main 函数中的循环退出之前调用 App::destroy 的时候,绘制和呈现操作可能仍在进行。在这种情况下清理资源可不是个好主意。
要修复这一问题,我们应该在 App::destroy 中调用 device_wait_idle 来等待逻辑设备完成操作:
Event::WindowEvent { event: WindowEvent::CloseRequested, .. } => {
destroying = true;
*control_flow = ControlFlow::Exit;
unsafe { app.device.device_wait_idle().unwrap(); }
unsafe { app.destroy(); }
}你也可以用 queue_wait_idle 来等待某个特定指令队列中的操作完成。这些函数可以用作一种非常简单的同步方式。你会发现当你关闭窗口时程序不再崩溃(不过如果你启用了校验层的话,你会看到一些与同步相关的错误)。
多帧并行渲染
如果你启用校验层并运行应用程序,你会看到一些错误信息,或者观察到内存使用量在缓慢增长。这是因为应用程序在 App::render 函数中快速提交了大量工作,但实际上并没有等待它们完成。如果 CPU 提交工作的速度比 GPU 处理工作的速度快,那么队列就会慢慢地被工作填满。更糟糕的是,我们同时还在重复使用 image_available_semaphore 和 render_finished_semaphore 信号量,以及指令缓冲。
最简单的解决方式就是在提交之后等待工作完成,例如使用 queue_wait_idle(注意:不要真的这么做):
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.device.queue_present_khr(self.data.present_queue, &present_info)?;
self.device.queue_wait_idle(self.data.present_queue)?;
Ok(())
}但这并不是使用 GPU 的最佳方式,因为如果这么做的话,整个图形管线只能同时渲染一帧了。然而当前帧已经完成的阶段是空闲的,可以用来渲染下一帧。我们现在将扩展我们的应用程序,允许多帧同时进行,同时限制积压的工作量。
首先在程序顶部添加一个常量,用于定义可以并行处理多少帧:
const MAX_FRAMES_IN_FLIGHT: usize = 2;每一帧都应该有自己的信号量,存储在 AppData 中:
struct AppData {
// ...
image_available_semaphores: Vec<vk::Semaphore>,
render_finished_semaphores: Vec<vk::Semaphore>,
}然后修改 create_sync_objects 函数,创建这些信号量:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
let semaphore_info = vk::SemaphoreCreateInfo::builder();
for _ in 0..MAX_FRAMES_IN_FLIGHT {
data.image_available_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
data.render_finished_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
}
Ok(())
}类似地,这些信号量也应该被清理:
unsafe fn destroy(&mut self) {
self.data.render_finished_semaphores
.iter()
.for_each(|s| self.device.destroy_semaphore(*s, None));
self.data.image_available_semaphores
.iter()
.for_each(|s| self.device.destroy_semaphore(*s, None));
// ...
}要确保每次都使用正确的信号量,我们需要跟踪当前帧。我们将使用一个帧索引来实现,我们把它添加到 App 中(在 App::create 中将其初始化为 0):
struct App {
// ...
frame: usize,
}然后修改 App::render 函数,使用正确的信号量对象:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
let image_index = self
.device
.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphores[self.frame],
vk::Fence::null(),
)?
.0 as usize;
// ...
let wait_semaphores = &[self.data.image_available_semaphores[self.frame]];
// ...
let signal_semaphores = &[self.data.render_finished_semaphores[self.frame]];
// ...
Ok(())
}当然,记得每次都要前进到下一帧:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.frame = (self.frame + 1) % MAX_FRAMES_IN_FLIGHT;
Ok(())
}使用取余(%)运算符,我们可以确保在每次入队 MAX_FRAMES_IN_FLIGHT 帧之后,帧索引都会绕回到 0。
尽管我们现在已经设置了所需的对象来同时处理多帧,但我们仍然没有真正阻止多于 MAX_FRAMES_IN_FLIGHT 的帧被提交。现在只有 GPU-GPU 同步,没有 CPU-GPU 同步来跟踪工作的进度。我们可能在帧 #0 还在飞行的时候就使用了与帧 #0 关联的对象!
要进行 CPU-GPU 同步,Vulkan 提供了第二种同步原语 —— 栅栏。栅栏与信号量类似,栅栏可以发出信号,也可以等待栅栏发出的信号。但这次我们实际上要在自己的代码中等待。我们首先为 AppData 中的每一帧创建一个栅栏:
struct AppData {
// ...
in_flight_fences: Vec<vk::Fence>,
}我们会在 create_sync_objects 函数中一起创建信号量和栅栏:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
let semaphore_info = vk::SemaphoreCreateInfo::builder();
let fence_info = vk::FenceCreateInfo::builder();
for _ in 0..MAX_FRAMES_IN_FLIGHT {
data.image_available_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
data.render_finished_semaphores
.push(device.create_semaphore(&semaphore_info, None)?);
data.in_flight_fences.push(device.create_fence(&fence_info, None)?);
}
Ok(())
}创建栅栏(vk::Fence)的方式与创建信号量非常相似。同样,确保在 App::destroy 中清理栅栏:
unsafe fn destroy(&mut self) {
self.data.in_flight_fences
.iter()
.for_each(|f| self.device.destroy_fence(*f, None));
// ...
}现在我们修改 App::render 函数并将栅栏用于同步。queue_submit 调用包含一个可选的参数,为其传递一个栅栏,当指令缓冲执行完毕时该栅栏会发出信号。我们可以使用这个来发出帧已经完成的信号。
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.device.queue_submit(
self.data.graphics_queue,
&[submit_info],
self.data.in_flight_fences[self.frame],
)?;
// ...
}现在剩下的就是修改 App::render 的开头,等待帧完成:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
self.device.wait_for_fences(
&[self.data.in_flight_fences[self.frame]],
true,
u64::MAX,
)?;
self.device.reset_fences(&[self.data.in_flight_fences[self.frame]])?;
// ...
}wait_for_fences 函数接受一个栅栏数组,并等待其中任意一个或全部栅栏发出信号后再返回。我们传递的 true 参数表示我们想要等待所有栅栏,但是在只有一个栅栏的情况下,这显然并不重要。与 acquire_next_image_khr 一样,这个函数也接受一个超时参数。与信号量不同,我们需要调用 reset_fences 函数手动将栅栏重置到未发出信号的状态。
如果你现在运行程序,你会发现一些奇怪的事情。应用程序似乎不再渲染任何东西,甚至可能会卡死。
这就意味着我们正在等待一个还没有发出信号的栅栏。问题在于,默认情况下,栅栏在创建之后处于未发出信号的状态。这意味着如果我们之前没有使用过栅栏,wait_for_fences 就会永远等待。要解决这个问题,我们可以修改栅栏的创建方式,将其初始化为已经发出信号的状态,就好像我们已经渲染了一帧:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
// ...
let fence_info = vk::FenceCreateInfo::builder()
.flags(vk::FenceCreateFlags::SIGNALED);
// ...
}现在就没有内存泄漏的问题了,但程序还不能正常工作。如果 MAX_FRAMES_IN_FLIGHT 大于交换链图像的数量,或者 acquire_next_image_khr 返回的图像是无序的,那么我们可能会开始渲染一个已经在飞行中(in flight)的交换链图像。为了避免这种情况,我们需要跟踪每个交换链图像是否有一个正在使用它的帧。这个映射将通过它们的栅栏来引用飞行帧,因此我们将立即拥有一个同步对象来等待,直到新的帧可以使用该图像。
首先在 AppData 中添加一个名为 images_in_flight 的新列表来跟踪正在使用的图像:
struct AppData {
// ...
in_flight_fences: Vec<vk::Fence>,
images_in_flight: Vec<vk::Fence>,
}并在 create_sync_objects 中初始化它:
unsafe fn create_sync_objects(device: &Device, data: &mut AppData) -> Result<()> {
// ...
data.images_in_flight = data.swapchain_images
.iter()
.map(|_| vk::Fence::null())
.collect();
Ok(())
}在最开始的时候,没有帧在使用图像,因此我们显式地将其初始化为没有栅栏(no fence)。现在我们将修改 App::render,等待任何正在使用我们刚刚为新帧分配的图像的上一帧:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
let image_index = self
.device
.acquire_next_image_khr(
self.data.swapchain,
u64::MAX,
self.data.image_available_semaphores[self.frame],
vk::Fence::null(),
)?
.0 as usize;
if !self.data.images_in_flight[image_index as usize].is_null() {
self.device.wait_for_fences(
&[self.data.images_in_flight[image_index as usize]],
true,
u64::MAX,
)?;
}
self.data.images_in_flight[image_index as usize] =
self.data.in_flight_fences[self.frame];
// ...
}因为我们现在有多个 wait_for_fences 调用,reset_fences 的调用也应该相应地改变。最好在实际使用栅栏之前再调用它:
unsafe fn render(&mut self, window: &Window) -> Result<()> {
// ...
self.device.reset_fences(&[self.data.in_flight_fences[self.frame]])?;
self.device.queue_submit(
self.data.graphics_queue,
&[submit_info],
self.data.in_flight_fences[self.frame],
)?;
// ...
}现在我们实现了所需的所有同步机制,确保没有两帧以上的工作被排入队列,并且排入队列的两帧不会使用同一张图像。代码中的其他部分,例如最终的清理工作,仍然可以依赖于 device_wait_idle 这类更粗略的同步机制。你应该基于性能需求选择使用哪种方式。
要通过示例学习更多关于同步机制的知识,请参阅 Khronos 编写的这篇全面概述。
结论
在编写了大概 600 行代码之后,我们终于看到有东西在屏幕上显示出来了!从零开始编写一个 Vulkan 程序显然是一项艰巨的任务,但要点是,Vulkan 通过其明确性为你提供了巨大的控制权。我建议你花些时间重读代码,并建立程序中所有 Vulkan 对象以及对象之间关系的思维模型。从现在开始,我们将以这些知识为基石,扩展我们程序的功能。
在下一章中,我们将处理良好的 Vulkan 程序需要的一点小事。